システム開発の現場において、エンジニアは常に「時間」との戦いを強いられます。スロークエリがシステム全体のパフォーマンスを劣化させ、深夜の緊急対応を迫られるといった事態は、多くの開発現場で共通する課題です。
現在、生成AIの登場により、SQLの作成自体は容易になりました。しかし、「AIが書いたSQLが本当に効率的か?」「提案されたインデックスが他のクエリに悪影響を与えないか?」という不安は、むしろ以前より増している傾向にあります。
本記事では、AIを単なる「コード生成機」としてではなく、「高度な分析エンジン」として活用するためのプロンプト設計について解説します。特に、実行計画(EXPLAIN)の深層分析と、副作用のない安全なインデックス設計に焦点を当てます。
ここで目指すのは、AIに答えを出させることだけではありません。AIとの対話を通じて、データベース内部の挙動を正しく理解し、自信を持って本番環境に変更を適用できる状態を作ることです。
1. AIによるSQLチューニングの「安全性」と「ROI」を定義する
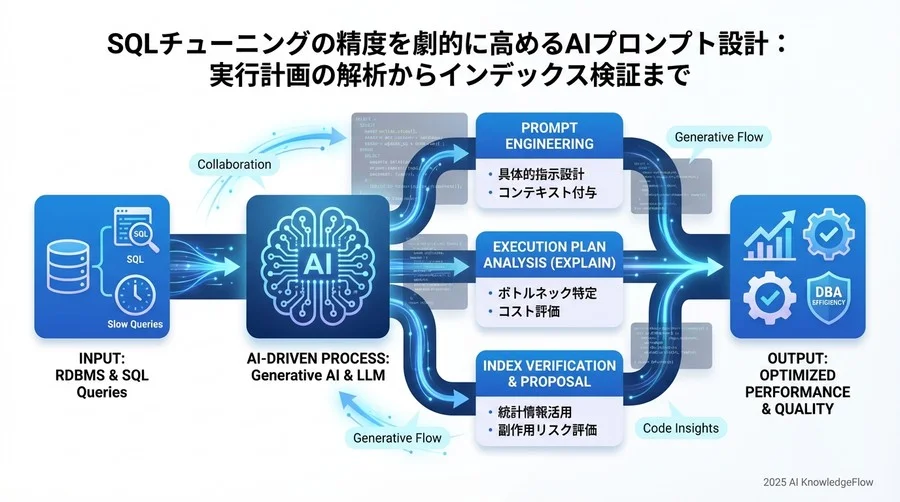
多くのエンジニアがChatGPTなどのLLM(大規模言語モデル)にSQLを書かせようとしますが、パフォーマンスチューニングの文脈では、アプローチを根本から変える必要があります。特に、GPT-5.2(InstantおよびThinking)のような最新のAIモデルが持つ高度な推論能力や長い文脈理解力を活かすには、単なる「コード生成機」としてではなく、「高度な分析エンジン」として位置づけることが重要です。
なぜAIにクエリを書かせるのではなく「診断」させるのか
生成AIは確率論的に「もっともらしい」回答を生成しますが、データベースの物理的なデータ分布やカーディナリティ(値のばらつき)までは、外部から情報を与えない限り知り得ません。そのため、AIがゼロから生成したSQLは、ロジックとしては正しくても、実際のデータ量やインデックス構成を考慮したパフォーマンスの観点では最適でないケースが多々あります。
一方で、「既存の情報(実行計画やスキーマ)を与えて、ボトルネックを指摘させる」タスクにおいては、最新のLLMは驚異的な能力を発揮します。GPT-5.2では論理推論や汎用知能が大幅に向上しており、提供された事実と膨大な知識ベースに基づいた「パターンマッチング」と「解析」を正確に行います。
この手法は「AI DBA(データベース管理者)診断」というアプローチとして捉えることができます。最大の利点は、ハルシネーション(嘘の生成)のリスクを最小化できる点です。AIには事実(EXPLAINの結果やテーブル定義)のみを入力し、その解釈を求めるため、架空のテーブルや関数を捏造する余地が極めて少なくなります。
熟練DBAの思考プロセスをプロンプトに落とし込む
熟練したDBAがスロークエリを見る際、以下のような思考プロセスを辿ります。AIへのプロンプト設計では、このプロセスを構造化して指示することが求められます。
- クエリの意図理解: 何を取得したいのか?(ビジネスロジックの把握)
- 実行計画の確認: インデックスは使われているか? スキャン範囲は適切か?
- 統計情報の確認: 行数は? カーディナリティは?
- ボトルネックの特定: ディスクI/Oか、CPUか、ロック待ちか?
- 改善案の策定: クエリの書き換えか、インデックス追加か?
- 副作用の検証: 他のクエリへの影響は?
本記事で紹介するアプローチは、この思考プロセスをAIに再現させるものです。単に「このクエリを速くして」と投げるのではなく、「目的・対象・制約・出力形式」を明確にした構造化プロンプトを使用します。公式の決まったテンプレートが存在するわけではありませんが、エージェントを活用したワークフローやコンテキストの明確な指定が現在のベストプラクティスです。
また、開発環境におけるAI支援の形も進化しています。例えば、GitHub Copilotでは従来の個別の拡張機能が非推奨となり、すべてのAI機能が「Copilot Chat拡張」に一本化されました。これにより、チャットやクラウドエージェントとの連携がシームレスに行えるようになっています。最新のGPT-5.2が持つ長い文脈理解力や、統合されたCopilot Chat環境を活用することで、プロジェクト全体のスキーマ情報や関連コードを考慮に入れた精度の高い診断が可能になります。以前のようにテキストをコピー&ペーストするだけでなく、AIをIDEのコンテキストに統合し、診断に必要な情報を効率的に渡すワークフローが極めて効果的です。
導入による工数削減効果と品質向上の試算
この「AI DBA診断」ワークフローを導入することで、以下のようなROI(投資対効果)が期待できます。
- 一次切り分け時間の短縮: 若手エンジニアが数時間悩む複雑な実行計画の解読を、GPT-5.2などの推論能力に優れたAIが数秒で要約・解説し、調査の当たりをつけます。
- レビュー品質の均質化: 「なぜそのインデックスが必要か」の理論的根拠が明確になるため、チーム内のコードレビューがスムーズになります。最新モデルの文章作成の構造化能力により、解説もより明瞭になっています。
- 学習コストの低減: AIによる詳細な解説を読むことで、チーム全体のDBパフォーマンスに対する理解度が向上し、属人化の解消につながります。
2. 前提条件:AIに「DBの構造」を正しく理解させるコンテキスト設計
AIに的確なアドバイスを求めるためには、まず「コンテキスト(文脈)」を正しくセットアップする必要があります。データベースにおけるコンテキストとは、テーブル定義(DDL)だけでなく、そこに格納されているデータの性質(統計情報)や、利用しているプラットフォーム特有の機能を指します。
DDLだけでは不十分:カーディナリティとデータ分布の伝え方
例えば、status というカラムにインデックスを貼るべきかどうかは、そのカラムの値の分布に依存します。status が「完了」と「未完了」の2値しかなく、99%が「完了」である場合、WHERE status = '未完了' の検索にはインデックスが有効ですが、逆はフルスキャンの方が速い場合があります。
AIにこの判断をさせるためには、以下のような情報をプロンプトに含める必要があります。
- テーブル定義(CREATE TABLE文)
- 主要カラムのデータ型と制約
- テーブルの総行数(概算で可)
- 主要カラムのカーディナリティ(ユニークな値の数)
LLMのコンテキストウィンドウを考慮したスキーマ情報の要約術
大規模なシステムではテーブル数が数百に及ぶこともありますが、全てのDDLをプロンプトに含める必要はありません。関連するテーブルのみを抽出し、以下のようなテンプレートを用いて構造化して渡します。
特にクラウドデータベース(AWS RedshiftやAurora等)を使用している場合、バージョンや利用可能な機能(マテリアライズドビューの自動リフレッシュやコンカレンシー・スケーリングの有無など)を明示することで、AIはプラットフォームの特性を活かした提案が可能になります。
プロンプトテンプレート:スキーマ情報定義
# Context: Database Schema & Statistics
以下のデータベース環境情報を前提として回答してください。
## Environment
- RDBMS: {{RDBMS_VERSION}} (例: MySQLの最新LTS版, PostgreSQL 16, Amazon Redshift)
- Hardware/Instance: {{HARDWARE_SPEC}} (例: AWS RDS db.r7g.xlarge, 32GB RAM)
- Key Features Enabled: {{FEATURES}} (例: Redshift Concurrency Scaling, Materialized Views)
## Table: {{TABLE_NAME}}
### DDL
```sql
{{CREATE_TABLE_STATEMENT}}
Statistics (Approximate)
- Total Rows: {{TOTAL_ROWS}} (例: 15,000,000)
- Avg Row Length: {{AVG_ROW_LENGTH}} bytes
Column Cardinality & Distribution
- user_id: Unique (Primary Key)
- status: Low Cardinality (Values: 'active', 'inactive', 'banned'. 'active' is 90%)
- created_at: High Cardinality (Range: 2024-01-01 to present)
- category_id: Medium Cardinality (approx 50 distinct values)
このように、「カーディナリティ」、「データの偏り(Distribution)」、そして「環境特性(Environment)」を明記することが、AIの推論精度を高める最大のポイントです。特にAmazon RedshiftのようなDWH環境では、最新のアップデート(2026年1月時点でのMV機能強化やスケーリング仕様など)により最適解が変わるため、バージョンや機能の有効化状態を伝えることが重要です。
### 機密情報をマスクするためのサニタイズ処理
当然ですが、実際の顧客データやPII(個人識別情報)をAIに入力してはいけません。プロンプトを作成する際は、以下のルールを徹底してください。
* 具体的な値(メールアドレス、電話番号など)はダミー値に置き換えるか、`{{EMAIL}}` のようにプレースホルダー化する。
* カラム名が機密情報を含む場合(例: `secret_access_key`)は、意味が通じる一般的な名称に変更する。
* 統計情報は概算値で十分であり、正確な数値を渡す必要はない。
## 3. 実装Step 1:実行計画(EXPLAIN)の「誤読」を防ぐ診断プロンプト
準備が整ったら、実際にスロークエリの診断を行います。ここでは、データベースが出力する実行計画(EXPLAIN)をAIに解析させます。
### EXPLAIN JSON形式の活用とAIへの入力フロー
従来の表形式のEXPLAIN出力は人間には読みやすいですが、構造がフラットであるため、複雑な結合やサブクエリの階層構造をAIが誤解する可能性があります。多くのRDBMSは実行計画をJSON形式で出力する機能を備えており、こちらの方がLLMにとって解析しやすい構造化データとなります。
* MySQL: `EXPLAIN FORMAT=JSON SELECT ...`
* PostgreSQL: `EXPLAIN (ANALYZE, BUFFERS, FORMAT JSON) SELECT ...`
PostgreSQLの場合、`ANALYZE` オプションを付けることで、実際の実行時間や処理行数も取得できるため、より正確な診断が可能になります(ただし、実際にクエリが実行される点に注意してください)。
#### プロンプトテンプレート:実行計画診断
```markdown
# Task: Analyze SQL Query Execution Plan
あなたはシニアデータベースアーキテクトです。
以下のスロークエリと実行計画(JSON形式)を分析し、パフォーマンスボトルの根本原因を特定してください。
## Query
```sql
{{TARGET_SQL}}
Execution Plan (JSON)
{{EXPLAIN_JSON_OUTPUT}}
Analysis Requirements
- Execution Steps: クエリがどのように実行されているか、処理の流れを要約してください。
- Bottleneck Identification: 最もコストがかかっている処理(Node)を特定し、その理由(例: Full Table Scan, Temporary Table, Filesort)を解説してください。
- Scan Efficiency: 読み取った行数とフィルタリング後の行数を比較し、非効率なスキャンが発生していないか評価してください。
- Optimization Hints: 具体的な改善の方向性(インデックス追加、クエリ書き換え、設定変更)を示してください。
### スキャンタイプ(Full Table Scan等)のリスク評価基準
AIからの回答を評価する際、特に注目すべきは「スキャンタイプ」の指摘です。
* MySQL: `type` フィールドが `ALL` (Full Table Scan) や `index` (Full Index Scan) になっている場合、それは明確な警告信号です。AIがこれを「危険」と判断しているか確認します。
* PostgreSQL: `Seq Scan` が必ずしも悪とは限りません(小さなテーブルでは効率的)。AIがテーブルサイズ(行数)を考慮して「このSeq Scanは問題ない」あるいは「改善が必要」と判断できているかが、コンテキスト設計の成否を分けます。
### 「なぜその実行計画が選ばれたか」をAIに言語化させる
オプティマイザは常に「コスト」に基づいて実行計画を選択します。AIに「なぜオプティマイザはインデックスAではなくインデックスBを選んだのか?」と問いかけることで、統計情報の不備(例えば、ANALYZEが実行されておらず統計が古いなど)に気づくきっかけになることがあります。
追加の質問プロンプト例:
> 「このクエリで `idx_user_created` インデックスが使用されず、Full Table Scanが選択された理由を、提供した統計情報に基づいて推論してください。」
## 4. 実装Step 2:副作用のない「最適インデックス」を提案させる設計プロンプト
ボトルネックが特定できたら、次は解決策としてのインデックス設計です。ここで最も重要なのは、「そのインデックスを追加することで、書き込み性能(INSERT/UPDATE/DELETE)や他のクエリに悪影響が出ないか」という視点です。
### 複合インデックスのカラム順序(最左プレフィックス)の推論
複合インデックス(Multi-column Index)は、カラムの並び順が命です。一般的に、「等価条件(=)で絞り込めるカラム」→「範囲条件(<, >)やソート(ORDER BY)に使うカラム」の順に配置するのがセオリーです(B-Treeインデックスの場合)。
AIにこの順序を最適化させるためのプロンプトを設計します。
#### プロンプトテンプレート:インデックス提案
```markdown
# Task: Propose Optimal Indexes
前述のクエリ分析に基づき、最適なインデックス設計を提案してください。
## Constraints & Guidelines
1. Best Practice: B-Treeインデックスの特性(最左プレフィックスルール)を考慮し、カラム順序を最適化してください。
2. Selectivity: カーディナリティが高い(選択性が高い)カラムを優先的に活用してください。
3. Covering Index: 可能な限り、テーブルアクセスを回避するカバリングインデックスを検討してください。
4. Write Amplification: インデックス追加による書き込みパフォーマンスへの影響を考慮し、必要最小限の構成にしてください。
5. Existing Indexes: 以下の既存インデックスと重複しないか、あるいは既存インデックスを拡張(DROP & CREATE)することで対応できないか検討してください。
## Existing Indexes
- idx_user_id (user_id)
- idx_created_at (created_at)
## Output Format
提案するインデックス定義(DDL)と、その設計意図(なぜこのカラム順序なのか)を説明してください。
更新コスト(Writeへの影響)を考慮したトレードオフ分析
インデックスは「読み取りを高速化し、書き込みを低速化する」トレードオフの産物です。AIに対して、単に速いインデックスを提案させるだけでなく、「このインデックスを追加すると、INSERT時のオーバーヘッドがどの程度増えるか(定性的な評価)」を出力させることで、導入の判断材料とします。
例えば、「このテーブルはログデータであり、毎秒数千件のINSERTが発生するため、インデックス追加は慎重に行うべきです」といったコンテキストを与えれば、AIは「カバリングインデックスまでは作成せず、最低限のフィルタリング用インデックスに留める」といったバランスの取れた提案が可能になります。
既存インデックスとの重複・競合チェック
データベース運用の現場でよくある失敗が、似たようなインデックスを乱立させてしまうことです。
- 既存:
INDEX (user_id) - 提案:
INDEX (user_id, status)
この場合、提案されたインデックスがあれば、既存の (user_id) インデックスは冗長(Redundant)となり、削除可能です。AIには「新しいインデックスを追加する代わりに、既存のインデックスを削除または統合する提案」も含めるよう指示することが重要です。
5. 実装Step 3:導入前の検証とベンチマーク手順
AIの提案がいかに論理的であっても、実機での検証なしに本番適用してはいけません。ここでは、安全かつ確実な検証プロセスを定義します。
AI提案を検証用環境でテストするためのチェックリスト
開発環境やステージング環境で以下の手順を実施します。
- ベースライン計測: 現状(インデックス適用前)のクエリ実行時間と
EXPLAIN結果を記録。 - インデックス作成: AIが提案したインデックスを作成。
- 改善効果計測:
EXPLAIN結果が変化したか(期待したインデックスが使われているか)、実行時間が短縮されたかを確認。 - 副作用チェック: 関連する他の主要クエリ(同じテーブルにアクセスする別のクエリ)の実行計画が変わっていないか確認。
Force Index等を用いた擬似的な効果測定
MySQLの場合、オプティマイザが新しいインデックスを選んでくれないことがあります。その際は、一時的に USE INDEX や FORCE INDEX ヒント句を使ってクエリを実行し、「もしオプティマイザがこのインデックスを選んだら、本当に速くなるのか?」を強制的に検証します。
逆に、インデックスを作成したが効果が怪しい場合、MySQL 8.0以降であれば Invisible Index 機能が役立ちます。
ALTER TABLE my_table ALTER INDEX idx_new_proposal INVISIBLE;
これにより、インデックスを物理的に削除することなく、オプティマイザから隠すことができます。この状態でクエリを実行し、パフォーマンスが劣化すれば、そのインデックスは有効だったという証明になります。
ロールバック手順の確立
本番適用時に予期せぬ問題(ロック競合によるシステム停止など)が発生した場合に備え、即座に切り戻すためのSQLも準備しておくべきです。
AIには、提案DDLとセットでロールバック用DDLも生成させましょう。
-- Apply
CREATE INDEX idx_user_status_created ON users(user_id, status, created_at);
-- Rollback
DROP INDEX idx_user_status_created ON users;
単純に見えますが、この準備があるだけで、リリース作業時の心理的負担は大幅に軽減されます。
6. 運用:チームで共有する「AI DBA」プロンプトテンプレート
個人のスキルとして留めるのではなく、チーム全体の資産としてAI活用を定着させるための運用方法です。
社内Wiki用のテンプレート配布
NotionやConfluenceなどの社内Wikiに、「SQLパフォーマンス診断ガイド」を作成し、今回紹介したプロンプトテンプレートを掲載しましょう。変数の部分({{TARGET_SQL}} など)を明確にし、誰でもコピペして使えるようにします。
CI/CDパイプラインでの自動チェックへの応用可能性
将来的には、GitHub ActionsなどのCI/CDパイプラインに組み込むアプローチが有効です。特定のAIコーディング支援ツールの機能に依存するのではなく、LLM APIを直接活用したカスタムアクションを構築することで、ツールの仕様変更に左右されない堅牢なチェック体制を作れます。
- 変更検知: プルリクエストに含まれるSQLファイルを抽出。
- 実行計画取得: 本番相当のスキーマを持つCI用DBで
EXPLAINを実行。 - AI診断: その結果をLLM API(OpenAI APIやAnthropic APIなど)に送信し、リスク判定(Full Table Scanの有無やインデックス不足など)を行わせる。
- 自動フィードバック: リスクが高い場合、PRに自動コメントして警告する。
これにより、人間のレビュアーが見落としがちなパフォーマンス劣化を、マージ前に機械的に検知する仕組み(Guardrail)を構築できます。なお、利用するAPIモデルや料金体系は頻繁に更新されるため、実装の際は各プロバイダーの公式ドキュメントで最新情報を確認してください。
継続的なプロンプト改善ループ
AIの回答精度は、入力する情報の質に比例します。「AIが的外れな回答をした」ときは、プロンプトに何の情報が不足していたかを分析し、テンプレートを更新してください。例えば、「データ型のサイズ感が考慮されていなかった」なら、カラム定義にバイト数の情報を追加するといった改善です。
まとめ:AIは「魔法の杖」ではなく「強力な顕微鏡」
本記事では、SQLクエリの最適化とインデックス設計におけるAI活用法を解説しました。
- AIを分析官として使う: ゼロからの生成ではなく、EXPLAIN結果の解析に特化させることで信頼性を担保する。
- コンテキストが命: 統計情報(カーディナリティ、行数)を与えることで、論理的な判断を引き出す。
- 副作用を考慮する: 書き込みコストや既存インデックスとの競合まで含めた包括的な設計をAIに求める。
- 検証を怠らない: AIの提案は仮説であり、実機での検証とロールバック計画が不可欠である。
AIは、あなたの代わりに責任を取ってくれるわけではありません。しかし、複雑怪奇な実行計画を瞬時に解読し、見落としていた観点を提示してくれる「強力な顕微鏡」として機能します。
まだ、スロークエリのログを一人で睨みつけていますか?
現在では、高度なナレッジ検索や分析ワークフローを、チーム全体でシームレスに共有・活用できるプラットフォームも存在します。プロンプトエンジニアリングの手間を省き、最適なデータベース戦略を即座に実行に移すための支援機能を活用することで、チームのデータベース管理業務は、より創造的で戦略的なものへと変わるはずです。
コメント