「大量の図面や仕様書をPDF化したのに、RAG(検索拡張生成)チャットボットがまともな回答をしてくれない」
実務の現場では、DX推進担当の方からこのような課題を耳にすることが急増しています。生成AIブームに乗り、社内に眠るアナログ資産をナレッジベース化しようと意気込んだものの、いざ蓋を開けてみれば「嘘の回答(ハルシネーション)」や「該当なし」のオンパレード。高額なAIツールを導入したのに、現場からは「紙のファイルを探したほうが早い」と揶揄されてしまう——。顧客体験や業務効率を損なうこうした事態に、悔しい思いをされているケースは少なくありません。
AI導入コンサルタントの視点から見ると、明確な事実が一つあります。それは、RAGの成否は「AIモデルの賢さ」ではなく、「入力データの品質」で9割決まるということです。
特に、紙文書を起点とする場合、「スキャンしてOCR(光学文字認識)にかければ終わり」と誤解されがちです。しかし、人間が目で見て読めるPDFと、AIが論理的に理解できるテキストデータは、全くの別物です。ここを理解せずにプロジェクトを進めると、後工程で莫大な修正コストが発生するか、使い物にならないシステムが出来上がってしまいます。
この記事では、Pythonコードやツールの細かい操作方法といった技術論は脇に置き、プロジェクト責任者が知っておくべき「データ化の品質管理」と「プロセス設計」に焦点を当てます。顧客ジャーニー全体を見据え、アナログ資産を価値あるナレッジに変えるための、確実なアプローチを見ていきましょう。
なぜ「ただのPDF化」がRAGの回答精度を劇的に下げるのか
まず、根本的な誤解を解くところから始めましょう。私たちが普段目にする「PDF」は、あくまで「紙の見た目をデジタル画面上で再現したもの」に過ぎません。人間には見出しの大きさや段組み、表の構造が視覚的に理解できますが、AI(大規模言語モデル)にとって、それは単なる「文字コードの羅列」か、最悪の場合は「意味不明な記号の集合体」として認識されることがあります。
AIは「見た目」ではなく「構造」を読む
人間は、太字で大きく書かれた文字を「見出し」と認識し、その下に続く文章を「本文」として読みます。また、罫線で囲まれた領域を「表」や「コラム」として認識し、本文とは別の情報として処理します。この「レイアウト解析」を、私たちは無意識のうちに行っています。
しかし、単純なテキスト抽出を経ただけのデータは、この「構造情報」が欠落していることが多々あります。例えば、2段組みのレイアウトを想像してください。人間は左の段を上から下へ読み、次に右の段へ移ります。しかし、構造を理解しない処理は、左段の1行目と右段の1行目を繋げて「1つの文章」として読み取ってしまうことがあります。
「製品Aの仕様は以下の通りです。(左段終了) / 注意事項:本製品は高温多湿を避けて…(右段開始)」
これが繋がってしまうと、「製品Aの仕様は以下の通りです。注意事項:本製品は高温多湿を避けて…」という、文脈の繋がらない文章が生成されます。
情報の関係性をグラフ構造で理解する「GraphRAG」は、Amazon Bedrock Knowledge Basesのクイック作成オプションでサポート(Preview段階)が開始されるなど、エンタープライズ環境でもより身近な技術になりつつあります。しかし、どれほど高度なGraphRAG環境を構築したとしても、この根本的なテキストデータが崩れていては、正しいエンティティの抽出や関係性のマッピングは行われません。
日本語のチャンク分割最適化(精度の高い文境界検出や、適切な埋め込みモデル・次元削減の適用など)といった高度な処理を議論する以前に、まずはこの支離滅裂なテキストを構造化し直す前処理が不可欠です。構造化を怠ると、RAGは崩れたテキストを「正解データ」として学習し、ユーザーからの質問に対して不正確な回答を生成する根本的な原因となります。
ノイズだらけのOCR結果が引き起こすハルシネーション
紙資料、特に古い図面やFAXで送られてきた注文書などは、汚れやカスレ、傾きが含まれています。これらをOCR(光学文字認識)にかけると、「1」が「l」や「I」に、「0」が「O」に誤認識されることは依然として珍しくありません。
最新のAI-OCR技術では、レイアウト解析やノイズ除去の機能が大きく向上しており、一部の製品では手書き文字や非定型帳票の認識精度も高まっています。しかし、それでも100%の精度を完全に保証するものではありません。
例えば、「型番:X-100」が「型番:X-IOO」と認識されたとしましょう。ユーザーが「X-100について教えて」と質問しても、AIはナレッジベースの中から「X-100」を見つけることができません。その結果、「情報が見つかりません」と答えるか、あるいは似たような別の型番の情報を無理やり引っ張ってきて、「X-100は最新の防水機能を備えています(実はX-200の情報)」といった嘘の回答、いわゆるハルシネーションを引き起こします。
RAGにおいて、抽出されたデータのノイズは単なる「誤字脱字」という軽微な問題ではありません。「検索機能の不全」とシステム全体の「信頼性の崩壊」を招く致命的な欠陥となるのです。
マルチモーダル時代でも残る「構造化」の重要性
さらに検討すべきは、「画像PDF」の扱いです。複合機でスキャンしただけのPDFは、コンピュータにとっては単なる「ピクセルの集合」でしかありません。
昨今では、画像や図表を直接理解できるマルチモーダルRAGの技術も進化しており、将来的には事前のテキスト抽出なしで画像を直接検索対象にできる可能性も広がっています。しかし、現時点の実務運用、特に正確性が厳しく求められる業務マニュアルや規定集の検索においては、依然としてテキストベースでの確実な構造化が推奨されます。
画像認識モデルはAPIの利用コストが高く、処理速度もテキスト処理に比べて劣る傾向があります。また、画像内に含まれる微細な文字情報の「検索ヒット率」を確実なものにするためには、やはり適切なOCR処理を行い、「テキストが正しい順序と意味を持って抽出されているか」を人間の目で確認するプロセスが不可欠です。
とりあえず最新のツールにデータを流し込んで安心し、中身のデータ品質を確認しないままRAGに投入して失敗するケースは、実務の現場でも頻繁に報告されています。泥臭いデータの前処理こそが、最終的な回答精度と顧客満足度を左右する最大の鍵と言えます。
現状分析:自社の「紙資産」のAI適性を診断する3つの指標
「倉庫にある段ボール100箱分の資料をすべてAI化したい」という要望が挙がることもありますが、コストと業務効率の観点から、すべてを対象とするのは推奨されません。
すべての紙資料を高品質なデータにするには、膨大なコストと時間がかかります。まずは、手持ちの資料が「AIにとって読みやすいか(OCR適性)」と「ビジネスにとって価値があるか(重要度)」を冷静に分析し、選別する必要があります。
手書き文字・レイアウト複雑性の評価基準
まず、物理的な難易度を評価します。以下の3つのレベルに分類してみましょう。
- レベルA(高適性): ワープロソフトで作成された活字文書。レイアウトがシンプル(1段組み)。汚れや傾きが少ない。
- レベルB(中適性): 活字だが、表組みや段組みが複雑。図版の中に文字が含まれている。多少の汚れや経年劣化がある。
- レベルC(低適性): 手書き文字が含まれる(日報やメモ書き)。FAX用紙のような低解像度・ノイズ過多。図面の中に手書きの修正指示がある。
レベルCの資料は、最新のAI-OCRを用いても認識精度が著しく低くなる傾向があります。これをデータ化するには、人間が手入力(打ち直し)するか、OCR結果を目視で全修正する必要があります。そのコストをかけてまでデータ化する価値があるか、厳しく問う必要があります。
情報の鮮度と重要度によるランク付け
次に、情報の価値基準です。古いマニュアルや、すでに廃番になった製品の仕様書をRAGに入れることは、かえって検索精度を下げる「ノイズ」になりかねません。
- Tier 1(必須): 現在稼働中の設備・製品のマニュアル、最新の安全基準、熟練技術者のノウハウが詰まったトラブルシューティング集。
- Tier 2(参考): 過去5年以内の事例集、旧製品だが現役で使用されているものの資料。
- Tier 3(不要): 10年以上前の日報、改定前の古い規定、重複している資料。
RAGの精度を高めるコツは、「何を入れるか」よりも「何を入れないか」にあります。Tier 3は迷わず廃棄、あるいは画像アーカイブとして保存するにとどめ、AIの検索対象からは外すべきです。
既存の複合機スキャン品質の確認
意外と見落とされがちなのが、スキャンデータの「解像度(dpi)」です。一般的なオフィス文書の保管用途であれば200dpi程度で十分ですが、OCRで高精度なテキスト抽出を行うには、最低でも300dpi、可能であれば400dpiが推奨されます。
また、カラーモードも重要です。文字認識だけであれば「白黒(2値)」や「グレースケール」の方が、裏写り(裏面の文字が透けて見える現象)を防ぎやすく、ファイルサイズも軽くなります。一方、図面や写真を含む資料で、その中の色情報(赤字の修正など)が重要な意味を持つ場合は、カラーでスキャンする必要があります。
まずはサンプルとして数種類の資料をスキャンし、OCRソフトに通してみて、どの程度正しく認識されるか「ベースライン精度」を測定してください。ここでの認識率が80%を下回るようであれば、スキャン設定の見直しや、原本のクリーニングといった前処理が必要になります。
最適化アプローチ①:AI視点での「前処理」とOCR設定の最適解
「OCRソフトの性能が悪い」と嘆く前に、入力する画像の質を見直すだけで、認識精度は劇的に向上します。AIにとって「読みやすい画像」を作るための、具体的な前処理テクニックを紹介します。
解像度とコントラストの黄金比
先ほど300dpi以上が推奨と述べましたが、単に解像度を上げれば良いわけではありません。解像度が高すぎるとファイルサイズが肥大化し、処理時間が長くなるだけでなく、紙の繊維などの微細なノイズまで拾ってしまい、かえって認識精度が落ちることがあります。A4サイズの文書であれば300〜400dpiが最適解です。
また、コントラスト調整は非常に有効です。紙が黄ばんでいたり、文字が薄かったりする場合、画像編集ソフトやスキャナの設定で「二値化しきい値」を調整し、背景を真っ白に、文字をくっきりとした黒に飛ばす処理を行います。これにより、AIは文字の輪郭を捉えやすくなります。
レイアウト解析エンジンの選び方
最近のAI-OCR製品には、強力な「レイアウト解析」機能が搭載されています。これは、文書内の「本文」「見出し」「表」「図」「ヘッダー/フッター」を自動で識別し、読む順序を決定する機能です。
RAG用のデータを作る際は、このレイアウト解析の設定で以下の点に注意してください。
- ヘッダー/フッターの除外: ページごとに繰り返される「社外秘」や「2023年度版」といった文字は、検索ノイズになります。これらを読み取り対象から除外する設定を行います。
- 表の構造化: 表組みを単なるテキストとして読むのではなく、CSVやMarkdownの表形式として出力できるエンジンを選びます。表のセル構造が維持されていないと、AIは「項目名」と「値」の対応関係を理解できません。
図表・キャプションの扱い方
図面やグラフの中に含まれる文字情報は、OCRの鬼門です。グラフの軸ラベルや凡例がバラバラのテキストとして認識されると、文脈が破壊されます。
ここでの現実的な解は、「図版エリアは画像として切り出し、キャプション(説明文)のみをテキスト化する」というアプローチです。あるいは、図の内容を人間が要約して「代替テキスト(Alt Text)」として付与します。最新のマルチモーダルAIであれば画像そのものを理解できる場合もありますが、現時点でのRAG構築においては、図版の意味を言語化してメタデータとして付与する方が、検索ヒット率は格段に上がります。
最適化アプローチ②:テキストの「意味」を残す構造化とチャンキング
OCRでテキストを抽出できたとしても、それはまだ「素材」に過ぎません。AIが文脈を正しく理解し、必要な情報をピンポイントで検索できるようにするためには、「構造化」と「チャンキング(分割)」という調理工程が不可欠です。
見出し・段落情報のメタデータ付与
抽出したテキストには、必ず「メタデータ」を付与しましょう。具体的には、そのテキストが「どの文書の」「どの章の」「どの見出しの下にあるか」という情報です。
例えば、あるトラブルシューティングのマニュアルで「電源が入らない場合」という項目が複数の製品(製品A、製品B)のマニュアルにあるとします。単に「電源が入らない場合:コンセントを確認してください」というテキストだけでは、それが製品Aの話なのかBの話なのかAIには判断できません。
そこで、Markdown形式などを活用して構造化します。
# 製品A 操作マニュアル
## 第3章 トラブルシューティング
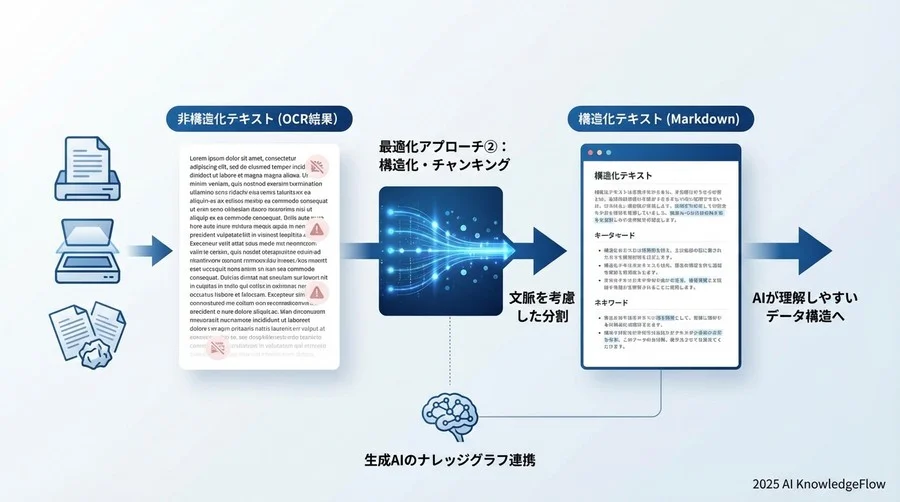
### 電源が入らない場合
- コンセントが正しく差し込まれているか確認してください。
このように階層構造を明示することで、AIは「製品Aの電源トラブルの解決策」として情報を正しくインデックスできます。
文脈を分断しないチャンク分割のコツ
RAGでは、長い文章を一定の長さ(チャンク)に分割してデータベースに保存します。この分割の仕方が検索精度を左右します。
単純に「500文字ごとに切る」という機械的な分割をしてしまうと、重要な文脈が分断されるリスクがあります。
悪い例: 「...原因としては以下の3つが挙げられ(ここで分割)ます。1. 電圧の低下...」
- これでは、前半のチャンクには「原因」が含まれず、後半のチャンクには「何の原因か」が含まれません。
良い例: 見出しや段落の区切り、あるいは「意味のまとまり」ごとに分割する。
これを自動化するのは難しい場合もありますが、最近のツールでは「セマンティック・チャンキング(意味に基づいた分割)」機能を持つものも増えています。紙文書の場合、OCRの認識ミスで段落が不明瞭なことがあるため、改行コードや空白行を基準にした慎重な分割設計が必要です。
マークダウン形式への変換メリット
Markdown形式への変換が強く推奨されます。Markdownは軽量で、かつ「見出し(#)」「箇条書き(-)」「強調()」といった文書構造を、AIが理解しやすい記号で表現できるからです。
OCRの結果をプレーンテキスト(ただの文字)として保存するのではなく、見出しを目視またはルールベースで特定し、Markdownタグを付与するひと手間を加えるだけで、RAGの回答品質は見違えるほど向上し、結果としてユーザーの自己解決率向上に寄与します。
トレードオフと注意点:コスト対効果を見極める「捨てる勇気」
ここまで品質向上の手法を述べてきましたが、重要なポイントがあります。「データ化において100%の精度を目指してはいけません」。
紙文書のデータ化プロジェクトが頓挫する最大の原因は、完璧主義によるコスト超過とスケジュールの遅延です。
「100%の精度」を目指してはいけない理由
OCRの精度が99.9%だとしても、1ページに1000文字あれば、必ず1文字は間違っています。これを人間が目視で全てチェックし、修正するには膨大な人件費がかかります。数万ページのマニュアル全てに対してこれを行うのは、予算的に不可能です。
RAGの用途を考えましょう。契約書の金額や図面の寸法数値など、一文字の間違いも許されないデータであれば、ダブルチェック・トリプルチェックが必要です。しかし、過去のトラブル事例や一般的な業務マニュアルであれば、多少の誤字(「てにをは」の間違いなど)があっても、LLM(大規模言語モデル)の推論能力で文脈を補完し、正しい回答を導き出せるケースが多いのです。
人手による修正コストの損益分岐点
どこまで人手をかけるべきか、基準を設けましょう。
- 重要数値・固有名詞: ここだけは人間がチェックする(正規表現などで抽出して確認)。
- 見出し・構造: ここが間違っていると検索できないため、優先的に修正する。
- 本文の誤字: 文脈が通じるレベルなら許容する。
「Human-in-the-loop(人が介介在するプロセス)」は、品質の要となる部分に集中投下すべきです。例えば、OCR後のテキスト全文チェックはせず、AIが「信頼度スコア」を低く出した箇所だけを人間が確認するツールを活用するのも賢い戦略です。
古いナレッジがAIを混乱させるリスク
「せっかくデータ化するのだから」と、昭和時代の古い技術資料までデジタル化しようとするケースが見受けられます。しかし、技術や法律、社内規定は変化しています。古い情報がナレッジベースに混ざることで、AIが現在のルールと矛盾する回答をしてしまうリスクがあります。
データのライフサイクル管理(Data Lifecycle Management)を導入し、「作成から10年以上経過したデータは、検索スコアを下げる」あるいは「参照対象から除外する」といった運用ルールをRAGシステム側に組み込むことも検討してください。
将来への投資:データ化プロジェクトを「一過性の作業」で終わらせない
最後に、最も重要な視点について触れておきます。RAGのための紙書類データ化は、単なる「過去の精算」ではありません。これを機に、「将来的に紙を生まない業務フロー」**へと転換し、顧客体験と業務効率を根本から改善する絶好のチャンスです。
これからの文書作成を「デジタルボーン」へ移行する
今、苦労して紙をスキャンしているのは、過去に誰かが紙で出力し、ハンコを押してファイリングしたからです。同じ苦労を数年後の後輩にさせないために、これからの業務は最初からデジタルデータとして作成・保存する「デジタルボーン」へ移行しましょう。
具体的には、タブレットによる電子帳票の導入、ワークフローシステムによる承認プロセスのデジタル化です。これにより、OCRという不確実なプロセスを経ることなく、100%正確なテキストデータをRAGに供給し続けることが可能になります。
段階的な導入ロードマップの描き方
いきなり全社展開を目指すのではなく、スモールスタートを推奨します。
- PoC(概念実証): 特定の部署(例:保守メンテナンス部門)の、特定の資料(例:過去3年分のトラブル対応報告書)に絞ってデータ化とRAG構築を行う。
- 効果測定: 検索にかかる時間がどれだけ短縮されたか、回答精度は実用に耐えうるかを検証する。
- 横展開: 成功モデルとデータ化のノウハウ(スキャン設定、構造化ルール)を他部署へ展開する。
社内説得のためのPoC設計
経営層や現場を説得するには、定量的な数字が必要です。「便利になります」ではなく、「ベテラン社員が資料探しに費やしていた月間20時間を削減し、若手への技術継承スピードが2倍になります」といった具体的な導入効果を提示してください。
紙文書のデータ化は、地味で根気のいる作業です。しかし、そこには組織の歴史と独自のノウハウが詰まっています。適切なKPI設計とコスト感覚を持って取り組めば、その「紙の山」は、競合が模倣できない最強の競争優位性、すなわち「AIの頭脳」へと生まれ変わるのです。
まとめ
RAG導入における紙文書のデータ化は、単なる「スキャン作業」ではなく、AIのための「知識の構造化プロセス」です。成功の鍵は、最新のツールを導入すること以上に、地道な前処理と選別にあります。
本記事の要点:
- AIは構造を読む: レイアウト解析と構造化(Markdown化)が検索精度の命。
- 選別が9割: 全てをデータ化せず、AI適性と重要度で資料をランク付けする。
- 前処理への投資: スキャン設定(300dpi以上)と画像のクリーニングでOCR精度を底上げする。
- 完璧主義を捨てる: コスト対効果を見極め、重要な箇所にのみ人的リソースを集中する。
- デジタルボーンへ: データ化プロジェクトを機に、紙を生まない業務フローへ移行する。
これからデータ化プロジェクトを始動する際は、どの資料を優先すべきか、どの程度まで前処理を行うべきかの判断基準を明確にすることが重要です。
現場の貴重な知見を確実に未来へ繋ぎ、顧客満足度と生産性の向上を両立させるために。まずは手元の資料の「診断」から始めてみませんか。
コメント