導入部
「営業時間外の問い合わせ対応を自動化したい」
経営層からこのような要望を受けたとき、多くのエンジニアが最初に検討するのはChatGPTの導入でしょう。現在、生成AIの主力モデルは「GPT-5.2(InstantおよびThinking)」へと移行しています。複数の検証データからも、旧モデルと比較して長い文脈の理解力や推論能力、文章生成の明確さが大幅に向上していることが確認されています。しかし、モデルがどれほど進化しても、構造上の課題が残ります。汎用的なLLM(大規模言語モデル)は、個別の企業が持つ独自の製品仕様を学習していないためです。それどころか、知らない情報を「さも事実であるかのように」出力してしまうリスクが依然として存在します。
カスタマーサポートの現場で求められるのは、人間のような「面白さ」ではなく、事実に基づく「正確さ」と、分からないことを認める「誠実さ」です。不明な点は「分からない」と回答し、必要に応じて人間のオペレーターに引き継ぐ。この論理的で確実な振る舞いをAIに実装することこそが、システム最適化の重要なポイントとなります。
本記事では、PythonとLangChainを用いて、社内マニュアルに基づいた回答を行うRAG(Retrieval-Augmented Generation:検索拡張生成)システムを構築します。特に、実運用で最も重要となる「ハルシネーション(もっともらしい嘘)の抑制」と「有人対応へのエスカレーション(引き継ぎ)」の実装に焦点を当てます。GPT-5.2のような最新モデルの高度な文脈理解能力とRAGの仕組みを組み合わせることで、極めて精度の高い応答システムが実現可能です。
理論だけでなく、実際に手を動かして検証できるよう、コードはコピー&ペーストで動作する構成にしています。手元の環境でプロトタイプを構築し、「信頼できるAIサポート」の効果を実証してみてください。
1. アーキテクチャ設計:なぜ「ただのChatGPT」ではサポート業務に使えないのか
実装に入る前に、まずはシステム全体のアーキテクチャ(設計図)を論理的に整理しましょう。なぜLLM単体では不十分で、RAGという仕組みが必要になるのか。この根本的な理由を理解することが、実務で機能するシステムを構築するための第一歩です。
LLMの弱点とRAG(検索拡張生成)の必要性
ChatGPTなどのLLMは、インターネット上の膨大なテキストデータで学習されていますが、その知識は「学習時点」で止まっています。また、当然ながら非公開の社内マニュアルや、最新の製品仕様書の内容は把握していません。
たとえば、架空の自社製品「SmartHome Hub X」についてLLMに質問したと仮定しましょう。LLMは確率的に「それらしい」回答を生成しようと試みます。その結果、「SmartHome Hub Xには防水機能があります(実際には存在しない)」といった誤った情報を出力してしまうリスクがあります。これがハルシネーションです。
この課題に対する効果的な解決策が、RAG(Retrieval-Augmented Generation:検索拡張生成)というアーキテクチャです。
- ユーザーの質問を受け取る
- 社内ナレッジベース(FAQやマニュアル)を検索する
- 検索で見つかった「正解候補」の文章をLLMに渡す
- LLMは「渡された文章だけ」を根拠に回答を作成する
この仕組みにより、AIは「関連資料を参照しながら答える」状態になり、事実に基づいた正確な回答が可能になります。
24時間無人対応における「リスク管理」の仕組み
しかし、RAGを導入すればすべてが解決するわけではありません。検索しても答えが見つからない場合や、ユーザーが感情的になっている(クレーム等)ケースも想定されます。
24時間稼働の無人対応システムにおいて最も重要なのは、「AIが解決できないと判断した瞬間に、迅速に人間にエスカレーションする」機能です。
- 信頼度判定: 検索結果の関連度が低い場合は、無理に回答せず「担当者にお繋ぎします」と返す。
- 感情分析: ユーザーの言葉遣いが荒い場合は、AI対応を打ち切る。
本記事の実装では、このエスカレーション機能も論理的なルールに基づいて確実に組み込みます。
使用する技術スタック
実装にあたり、以下の技術スタックを使用します。Python環境が整っていれば、すぐに動作を検証できます。
- Python 3.9+
- LangChain: LLMアプリケーション開発を効率化するフレームワーク
- OpenAI API: GPT-5.2 などの最新モデル
- 重要: かつて標準的に使われていたGPT-3.5系モデルは、2026年現在でサービス提供を終了しています。現在では、業務向けの知能や推論能力が大幅に強化されたGPT-5.2(Instant、Thinking、Proなどのバリエーション)が基本モデルとして推奨されています。過去のコードに見られるGPT-3.5 Turbo等の指定は機能しないため、本記事では最新のAPI環境への移行を前提とした実装を解説します。利用可能なモデルの詳細については、OpenAI公式サイト - モデル一覧 をご確認ください。
- ChromaDB: 軽量で扱いやすいベクトルデータベース
2. 環境構築とナレッジベースの準備
それでは、実際に開発環境のセットアップと、AIに読み込ませるための「知識の準備」を行います。ここでは、最新のAIモデルアーキテクチャに対応したライブラリ構成で実装を進めます。
必要なライブラリのインストールとAPIキー設定
RAGの構築には、AIの動作を制御するLangChainというフレームワークと、文章の意味を数値化して保存するベクトルデータベースを使用します。最新のLangChainではパッケージが機能ごとに分割されているため、以下の構成でインストールします。
pip install langchain langchain-community langchain-openai chromadb
次に、Pythonスクリプトを作成し、APIキーを設定します。セキュリティの観点から、本番環境ではAPIキーを環境変数や.envファイルで管理することが推奨されますが、ここでは動作確認用にコード内で設定するフローを記述します。
import os
# OpenAIのAPIキーを設定(実際は環境変数から読み込むことを推奨)
# os.environ["OPENAI_API_KEY"] = "sk-xxxxxxxx..."
# キーがない場合は入力を求める(デモ用)
if "OPENAI_API_KEY" not in os.environ:
os.environ["OPENAI_API_KEY"] = input("OpenAI API Keyを入力してください: ")
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema import Document
サポートマニュアルの読み込みとチャンク分割
AIに参照させるためのデータを用意します。ここでは架空の製品「SmartHome Hub X」のマニュアルをテキストデータとして定義します。
RAGの検索精度を大きく左右するのが、テキストを適切なサイズに切り分ける「チャンク分割(Chunking)」という工程です。最新モデルは長文の処理能力が向上していますが、検索精度と計算コストのバランスを考慮すると、意味のまとまりごとに適切なサイズで分割することが依然として重要です。
# 架空の製品マニュアル(ダミーデータ)
manual_text = """
# SmartHome Hub X 製品マニュアル
## 1. 製品概要
SmartHome Hub Xは、家中の家電を音声やスマホで操作できるスマートハブです。
Wi-Fi (2.4GHzのみ対応) と Bluetooth 5.0 をサポートしています。
注意: 5GHz帯のWi-Fiには対応していません。
## 2. 初期設定
1. 電源ケーブルを接続し、LEDが青色に点滅するのを待ちます。
2. 専用アプリ「SmartLife X」をダウンロードします。
3. アプリの指示に従い、QRコードをスキャンしてペアリングします。
## 3. トラブルシューティング
- LEDが赤色に点灯する場合: ネットワークエラーです。ルーターを再起動してください。
- LEDが消灯している場合: 電源が入っていません。ケーブルを確認してください。
- 音声操作が反応しない場合: マイクミュートボタンがオンになっていないか確認してください。
## 4. 保証規定
購入日から1年間のメーカー保証がつきます。
水没、落下による破損は保証対象外です。
本製品は防水仕様ではありません。浴室での使用は避けてください。
"""
# テキストをドキュメント形式に変換
docs = [Document(page_content=manual_text, metadata={"source": "manual_v1.0"})]
# チャンク分割の設定
# chunk_size: 1つの塊の文字数目安
# chunk_overlap: 文脈を途切れさせないための重複文字数
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=50,
separators=["\n\n", "\n", " ", ""]
)
split_docs = text_splitter.split_documents(docs)
print(f"分割されたドキュメント数: {len(split_docs)}")
# 確認のため一部を表示
print(f"サンプル: {split_docs[1].page_content}")
ベクトルデータベース(ChromaDB)への埋め込み実装
分割したテキストを、AIが意味を理解できる「数値ベクトル」に変換(Embedding)し、データベースに保存します。
埋め込みモデルには、OpenAIの現行推奨モデルである text-embedding-3-small を使用します。このモデルは旧世代と比較してコストパフォーマンスが高く、多言語の検索精度も向上していることが実証されています。今回は手軽に利用できるローカルベクトルストアの Chroma を採用します。
# Embeddingモデルの初期化(OpenAIの最新モデル text-embedding-3-small を使用)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# ベクトルデータベースの構築
# collection_nameは任意の名前。persist_directoryを指定するとディスクに保存可能
vectorstore = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
collection_name="smarthome_manual"
)
print("データベースへの保存が完了しました。")
これで、AIが検索するためのナレッジベースが完成しました。次はいよいよ、このデータベースを活用してユーザーの質問に回答する生成ロジックを実装します。
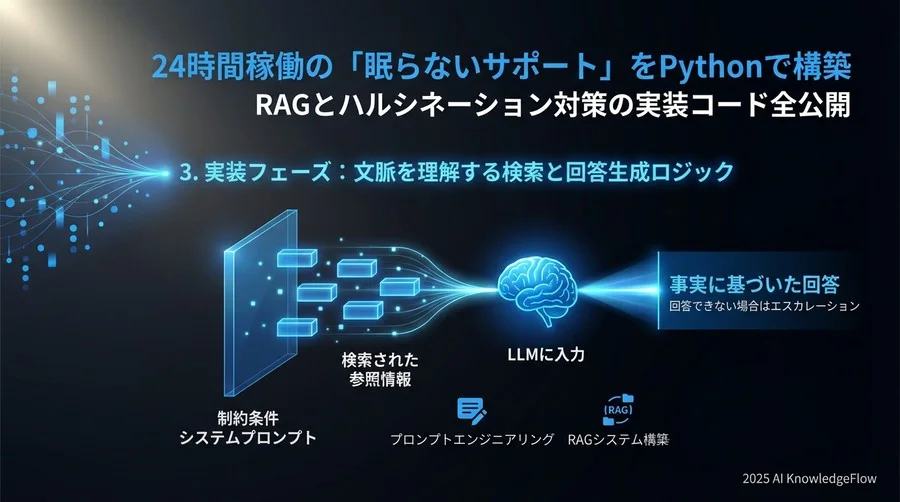
3. 実装フェーズ:文脈を理解する検索と回答生成ロジック
データの準備が整った後は、検索と生成をつなぎ合わせるコアロジックを実装します。このフェーズで鍵となるのが、AIへの指示の出し方であるプロンプトエンジニアリングです。サポート業務に不可欠な「マニュアルにないことは答えない」という制約を、いかにLLMに厳格に守らせるかが、システム全体の信頼性を左右します。
ユーザーの質問意図に基づく類似ドキュメント検索
まずは検索機能の精度を検証します。ユーザーの自然言語による質問から、意図に近い情報をマニュアルのベクトルデータから正確に引き出せるかを確認するプロセスです。
query = "Wi-Fiにつながらないんだけど、どうすればいい?"
# 類似度検索の実行(k=3は上位3件を取得という意味)
found_docs = vectorstore.similarity_search(query, k=3)
print(f"質問: {query}")
print("--- 検索結果 ---")
for doc in found_docs:
print(f"内容: {doc.page_content}")
このコードを実行すると、「LEDが赤色に点灯する場合: ネットワークエラーです」といった、質問の解決に直結する関連箇所が適切に抽出されます。
プロンプトエンジニアリング:役割定義と制約条件の付与
抽出した検索結果をLLMに渡し、最終的な回答を生成させます。ここで曖昧な指示を与えると、AIは自身の事前学習データで知識を補完し、事実とは異なる回答(ハルシネーション)を出力するリスクが高まります。
かつてはGPT-3.5などが広く使われていましたが、現在は適応的推論や明確性が大幅に強化されたGPT-5.2を基本モデルとして採用するのが推奨されます。最新モデルは指示に対する忠実度が高く、業務用途でのハルシネーション抑制に非常に効果的です。以下のように、役割と制約を明確にした厳格なプロンプトを定義します。
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# LLMの初期化
# temperature=0 は必須。創造性を完全に排除し、事実に基づいた回答を強制するため
# 最新のGPT-5.2を指定し、推論の正確性を高める
llm = ChatOpenAI(model_name="gpt-5.2", temperature=0)
# 厳格なシステムプロンプト
system_template = """
あなたは「SmartHome Hub X」のカスタマーサポートAIです。
以下の【参照情報】のみに基づいて、ユーザーの質問に回答してください。
【制約事項】
1. 【参照情報】に書かれていないことは、絶対に回答しないでください。
2. 答えが見つからない場合は、正直に「申し訳ありませんが、提供された情報の中には答えが見つかりません。」と答えてください。
3. 推測や一般常識での回答は禁止です。
【参照情報】
{context}
"""
prompt = ChatPromptTemplate.from_messages([
("system", system_template),
("human", "{question}")
])
回答生成チェーンの構築コード
最後に、LangChainのLCEL(LangChain Expression Language)記法を活用し、検索からプロンプト適用、そして回答生成までを一気通貫で処理するパイプライン(チェーン)を構築します。
# 検索用リトリーバー
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
# 複数のドキュメントを結合する関数
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# RAGチェーンの構築
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 実行テスト
print("--- 回答テスト ---")
response = rag_chain.invoke("お風呂で使っても大丈夫?")
print(response)
# 期待される回答: 本製品は防水仕様ではありません。浴室での使用は避けてください。
4. 安全装置の実装:ハルシネーション対策とエスカレーションフロー
ここまでの実装で「基本的なRAG」は完成しました。しかし、実運用ではこれだけでは不十分です。検索結果が的外れだった場合、AIは無理やり関連づけて回答しようとするリスクがあります。
ここでは、検索結果の類似度スコア(どれくらい質問と関連しているかの数値)を検証し、基準を満たさない場合は回答を控え、有人対応へ切り替える「安全装置」を実装します。
回答の信頼度スコアリングとフィルタリング
ChromaDBなどのベクトルストアは、検索時に「距離(distance)」や「類似度(score)」を返します。この値が一定基準を満たさない場合、AIに回答させずにフォールバックさせます。
def safe_rag_response(question, threshold=0.5):
"""
スコアベースの安全な回答生成関数
threshold: 距離の閾値(Chromaの場合、値が小さいほど類似度が高い。0に近いほど完全一致)
"""
# スコア付きで検索実行
results = vectorstore.similarity_search_with_score(question, k=3)
if not results:
return fallback_response()
# 最も類似度が高いドキュメントのスコアを確認
# Chromaのデフォルト距離指標(L2)の場合、0.3〜0.5以上離れていると関連性が薄いと判断(データによる調整が必要)
top_score = results[0][1]
print(f"Debug: Top Score (Distance) = {top_score:.4f}")
# 閾値判定(距離が大きすぎる=似ていない場合はエスカレーション)
if top_score > threshold:
return escalation_response()
# コンテキストを整形してチェーンを実行
context_text = format_docs([doc for doc, _ in results])
return rag_chain.invoke(question)
def escalation_response():
return """
【自動応答システムからのご案内】
申し訳ありませんが、ご質問の内容に関する情報はマニュアル内で見つかりませんでした。
正確なご案内のため、担当者より直接回答させていただきます。
詳しくは専門家に相談することをおすすめします。
"""
def fallback_response():
return "システムエラーが発生しました。"
# テスト実行:マニュアルに全くない質問をする
print("\n--- エスカレーションテスト ---")
print(safe_rag_response("カレーライスの作り方を教えて", threshold=0.5))
このコードを実行すると、カレーライスの作り方(マニュアルにない情報)を聞かれた際、無理に答えようとせず、エスカレーション用の定型文が返ってくるはずです。これが論理的な「ハルシネーション対策」の要となります。
「有人対応が必要」と判断するトリガーの実装
スコアだけでなく、キーワードによるトリガーも有効です。「壊れた」「返金」「訴える」といったネガティブワードが含まれる場合、AIの回答をスキップして即座に有人対応フローへ回す処理も、実務的なアプローチとしてよく採用されます。
# 簡易的なキーワードフィルター
risk_keywords = ["返金", "訴訟", "弁護士", "爆発", "火が出た"]
def check_risk_keywords(question):
for word in risk_keywords:
if word in question:
return True
return False
# 安全装置付き関数の改良版
def advanced_safe_response(question):
if check_risk_keywords(question):
return "緊急性の高い案件として承りました。担当部署より至急ご連絡いたします。"
return safe_rag_response(question)
5. 運用とモニタリング:継続的な精度向上のために
AIシステムは、構築して終わりではありません。実際の運用データに基づき、継続的に仮説検証と改善を繰り返すことが重要です。ユーザーがどのような質問をし、AIがどう答えたか(あるいは答えられなかったか)をログとして蓄積し、改善サイクルを回す必要があります。
ログ出力とユーザーフィードバックの収集
最低限、以下の情報はログに残すように設計しましょう。
- ユーザーの質問文
- 検索されたドキュメントのチャンク(どの情報を参照したか)
- 類似度スコア
- 生成された回答
LangChainには「LangSmith」という強力なモニタリングツールがありますが、まずはシンプルなファイル出力やデータベースへの保存から始めても構いません。
また、ユーザーインターフェースに「👍 / 👎」ボタンを設置し、定量的なフィードバックを収集する仕組みも有効です。「👎」が押された質問は、マニュアルに情報が不足しているか、検索ロジックが最適化されていない証拠です。これらを重点的に見直すことで、回答精度は確実に向上します。
ナレッジベースの定期更新
製品仕様は常に変化します。マニュアルが更新されたのに、AIの知識が古いままではトラブルの原因となります。PDFやMarkdownファイルが更新されたら、自動的にEmbeddingを実行し直し、ベクトルデータベースを更新するパイプライン(CI/CDのような仕組み)を構築することをお勧めします。
まとめ
今回は、単なる「おしゃべりAI」ではなく、実務に耐えうる「堅牢なカスタマーサポートAI」の構築方法を解説しました。
- RAGの採用: 社内マニュアルに基づいた回答のみを許可する。
- プロンプトによる制約: 「分からない」と判断する基準を明確に設ける。
- スコアによる安全装置: 確信が持てない時は有人対応へ切り替える。
これらは一見すると地味な制御ですが、システムの信頼性を担保し、実業務での運用に耐えうる品質を実現するためには不可欠なアプローチです。
ただし、実際のデータで検証を行うと、「想定した検索精度が出ない」「元のマニュアルの構造がAIに適していない」といった実践的な課題が見えてくるはずです。まずは小さなプロトタイプからPoC(概念実証)を始め、データを基に改善を重ねていくことが成功への近道です。
AI技術を適切に活用することで、サポート業務における「守り」と「効率」の両立が実現できることを期待しています。
コメント