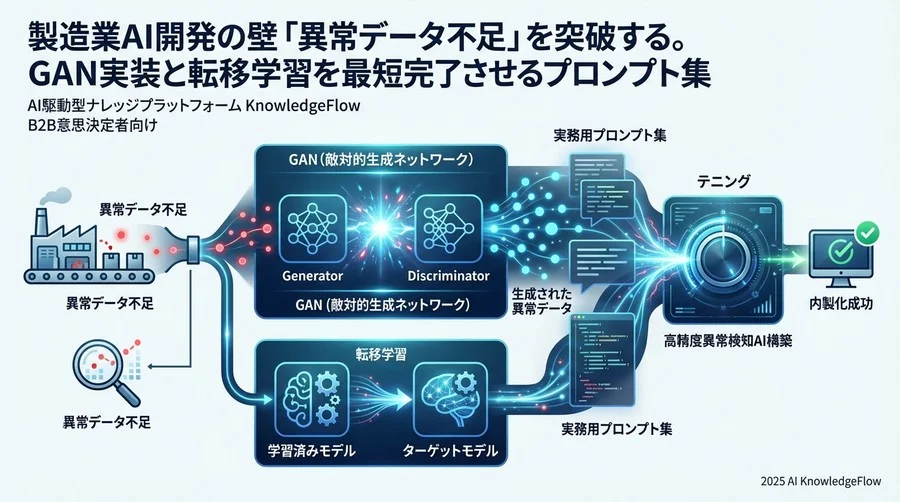
製造現場における品質予測AIや異常検知プロジェクトにおいて、高い確率で直面する課題があります。それは「異常データの不足」です。
良品データは数万件規模で蓄積されていても、不良品データは数十件に満たないケースが多々あります。この不均衡なデータセットではAIが十分な特徴を学習できず、実運用に耐えうる検知精度(例えば過検出率1%未満など)を達成することが困難になります。日本の製造現場はカイゼン活動により不良品の発生頻度が極めて低く保たれているため、データドリブンなアプローチを阻む壁となりがちです。
一般的な解決策として、GAN(敵対的生成ネットワーク)を用いて異常データを擬似的に生成し、データセットを拡張する手法があります。しかし、GANの実装は学習の不安定さやネットワーク設計の難易度が高く、開発工数が想定の2〜3倍に膨らむことも珍しくありません。
そこで本記事では、継続的な改善を推進する観点から、より効率的なアプローチを解説します。複雑なGANのコードや転移学習の実装をゼロから記述するのではなく、生成AI(LLM)を活用して実装プロセスを大幅に短縮する手法です。
異常検知AI実装のためのプロンプトテンプレートを活用することで、自社のセンサーデータや画像特性に合わせたGANおよび転移学習のコードを、従来の数分の一の工数で作成できる可能性があります。まずは小さく始めて成果を可視化し、段階的にスケールアップしていく導入戦略の第一歩として役立ててください。
本プロンプト集の活用方針と前提条件
GAN(敵対的生成ネットワーク)の実装において、生成AIのプロンプト活用がなぜ有効なのか、そして本記事で前提とする技術環境について解説します。
なぜGANの実装に生成AIプロンプトが必要なのか
GANは、Generator(生成器)とDiscriminator(識別器)という2つのネットワークを競わせる仕組み上、学習バランスの調整が極めて困難です。モード崩壊(同じような画像しか生成されなくなる現象)や勾配消失といった問題は、開発期間の長期化を招く主要な要因となります。
これらを回避するための実装テクニック(Spectral NormalizationやWGAN-GPなど)は多岐にわたり、全てを把握してゼロからコーディングすることは、生産性向上の観点から非効率です。しかし、最新のChatGPT(GPT-5.2ファミリーなど)やClaude 3.5 Sonnetは、これらのベストプラクティスや最新の研究論文の内容を網羅的に学習しています。
特に現在のAIモデルは、単なるコード生成ツールから「自律的な開発パートナー」へと進化を遂げました。
- 推論能力の飛躍的な向上: 例えばChatGPTの最新バージョンであるGPT-5.2のThinkingモードやProモード、そしてClaude 3.5 Sonnetは、複雑なネットワーク構造の設計意図を深く理解し、論理的な整合性を保ったコードを提案します。旧来のモデルに比べて思考プロセスが強化されており、より高度な問題解決が可能です。
- コンテキストを維持した反復精緻化: エラーログを解析して修正案を提示するだけでなく、メモリ機能やカスタムGPTを活用することで、プロジェクト全体の文脈を長期間保持できます。「この変更を行うと、こちらの損失関数にも影響が出ますがどうしますか?」といった、実務経験豊富なエンジニアのような多角的な指摘を引き出す使い方が一般的になっています。
重要なのは、AIを単なるツールではなく、高度な実装能力を持つパートナーと捉えることです。明確な役割をAIに付与し、構造化されたプロンプト(指示書)を渡すことで、実装工数を数十パーセント削減しつつ、品質の高いコードを得ることが可能になります。
異常データ生成における「要件定義」の重要性
製造業における検査画像データは特殊です。一般的な画像生成とは異なり、以下のような微細かつ具体的な特徴を定量的に捉える必要があります。
- 金属表面のヘアライン加工に紛れた微細なスクラッチ(ひっかき傷)。
- 鋳造部品内部の巣(空洞)。
- プラスチック成形品のウェルドラインやショートショット。
単に「異常画像を作って」と指示しても、AIは一般的なノイズが付加されただけの、実際の検査工程では役に立たない画像生成コードを出力してしまいます。製造現場特有の「異常の質感」や「発生メカニズム」を言語化し、AIに正確に伝えるプロセスが不可欠です。これはいわば、異常データ生成のための「要件定義」であり、品質改善の第一歩となります。
最新のAIは文脈適応能力が高まっているため、フォーマットや出力形式を具体的に指定し、Chain of Thought(ステップバイステップでの思考)を促すプロンプト設計が効果を発揮します。本記事のプロンプト集は、現場の暗黙知をAIが理解可能な技術仕様に変換し、データドリブンな改善を加速させるためのテンプレートとして設計されています。
推奨環境と対象ライブラリ
本記事のプロンプトは、以下の環境を想定して作成しています。
- 言語: Python 3.10以上。
- 主要ライブラリの互換性と、最新のAIコーディングアシスタントが生成するコードの傾向を考慮しています。
- ライブラリ: PyTorch。
- 研究・実装例が豊富で、GANのネットワーク構造を柔軟にカスタマイズしやすいため推奨します。TensorFlow/Kerasでも応用可能ですが、動的な計算グラフの取り扱いにおいてPyTorchの方がAIによるデバッグや反復検証が容易な傾向があります。
- 推奨AIモデル:
- 複雑な設計・論理構築: ChatGPT(GPT-5.2 Thinkingモード、Proモードなど)やClaude 3.5 Sonnetといった、論理的思考能力と文脈理解力が高いモデル。タスクに応じて適切なモデルを選択するルーティングの考え方も有効です。
- コーディング・実装: 上記に加え、各種コーディング特化型AIアシスタント。
- ハードウェア: NVIDIA GPU搭載マシン。
- Google Colab Pro等のクラウド環境でも実行可能です。
次章より、具体的なフェーズごとのプロンプトテンプレートを提示します。
【Phase 1】要件定義とデータ特性の言語化プロンプト
コーディングに着手する前に、手元にあるデータと生成したい異常の特徴をLLMに正確に理解させる必要があります。ここでの定義が曖昧だと、後のコード生成精度が低下し、手戻りによる工数増加を招く可能性があります。
画像データの特性をAIに伝えるテンプレート
以下のプロンプトをコピーし、[]の部分を自社の状況に合わせて記述してください。
## 前提条件定義プロンプト
あなたは製造業における画像処理とディープラーニングの専門家です。
以下の要件に基づき、後続のタスクで異常検知AIモデル(GANおよび転移学習モデル)の実装コードを作成してもらいます。
まずは、以下のデータセット特性とハードウェア制約を理解してください。
## 1. データセット特性
- 対象製品: [例: 自動車用ギア部品の表面]
- 画像解像度: [例: 256x256ピクセル]
- カラーモード: [例: グレースケール (1ch)]
- 背景: [例: 黒色のコンベアベルト、照明条件により光沢の変化あり]
- 良品データ数: [例: 500枚]
- 異常データ数: [例: 20枚 (極端に少ない)]
## 2. 生成したい異常の種類(欠陥定義)
- 欠陥名: [例: 線状のスクラッチ傷]
- 特徴: [例: 長さ10px〜50px、幅1px〜3px。周囲より輝度が高い白色の線。ランダムな方向に入る]
- 発生頻度: [例: 製品表面の任意の位置に1〜2箇所]
## 3. 開発環境と制約
- フレームワーク: PyTorch
- GPUメモリ: [例: 16GB (Google Colab Pro想定)]
- 目標: 良品画像から、リアルな異常画像を生成するGANモデルを構築し、データ拡張を行うこと。
この情報を理解したら、「データ特性を理解しました。次の指示を待機します」とだけ答えてください。
[書き換えのポイント]
- 対象製品: 具体的に記述すると、AIは適切な前処理を提案しやすくなります。素材感(金属、樹脂、布)が伝わるように記述すると効果的です。
- 特徴: 「傷」ではなく、「輝度が高い線」「暗い点」など、画像処理的な特徴を言語化するのがポイントです。
【Phase 2】GANモデル構築・学習コード生成プロンプト
データ特性を伝えたら、次は実際にGANのモデルを構築します。ここでは、良品画像をベースに異常箇所だけを生成・合成するアプローチや、良品ドメインから異常ドメインへ変換するアプローチが考えられます。
DCGAN/CycleGANベースコード生成テンプレート
製造業の異常生成では、CycleGAN(ペアのないデータ間での変換)や、AnoGAN(良品分布を学習し、外れたものを検知するが、ここではデータ生成に応用)の変種が利用されることがあります。ここでは、比較的実装しやすく、良品画像に欠陥を付加するタスクに適した構成を指示します。
## GANモデル実装プロンプト
データ特性に基づき、異常画像を生成するためのGAN(Generative Adversarial Networks)の実装コードをPython(PyTorch)で作成してください。
## GANモデルの要件
1. アーキテクチャ:
- 良品画像を入力とし、欠陥(定義したスクラッチ傷など)が付加された画像を生成するImage-to-Image変換モデル(CycleGANまたはPix2Pixの考え方を応用した簡易モデル)を構築してください。
- GeneratorはU-Netベースの構造を採用してください。
- DiscriminatorはPatchGANを採用し、局所的なテクスチャの整合性を評価させてください。
2. 損失関数:
- Adversarial Lossに加え、入力画像と生成画像の構造を維持するためのL1 Loss(Identity Loss)を含めてください。
- 学習を安定させるため、Label Smoothing(正解ラベルを1.0ではなく0.9にする等)を実装に含めてください。
3. 出力コードの構成:
- データローダーの定義(Data Augmentation含む)
- モデル定義(Generator, Discriminator)
- 学習ループ(各エポックでのLoss表示、一定間隔での生成画像保存機能付き)
コードは各ブロックに日本語で詳細なコメントを記述し、Google Colabですぐに実行可能な形式にしてください。
モード崩壊を防ぐ損失関数設定
もし生成された画像が同じようなパターンばかりになる場合(モード崩壊)、以下の追加指示を記述してください。
生成画像が単調です。モード崩壊を防ぐために、WGAN-GP (Wasserstein GAN with Gradient Penalty) の損失関数を導入するようにコードを修正してください。また、Generatorの学習回数をDiscriminatorよりも多くする(例: 1:5)設定を追加してください。
【Phase 3】転移学習による異常検知モデル強化プロンプト
GANで擬似的な異常データを生成できたら(例えば500枚程度)、それを用いて分類モデル(異常検知モデル)を学習させます。ここで重要なのが転移学習です。既存のモデルをチューニングすることで、学習時間を短縮しつつ高い精度を目指します。
生成データ(拡張データ)を学習セットに組み込む指示
## 転移学習モデル実装プロンプト
GANで生成した「擬似異常データ」と、元々の「良品データ」を使用して、異常検知(二値分類)モデルを構築します。
## 転移学習モデルの要件
1. ベースモデル:
- ResNet50 または EfficientNet-B0(事前学習済みモデル: ImageNet)を使用してください。
- 最終層を、今回のクラス数(良品/異常 の2クラス)に合わせて変更してください。
2. ファインチューニング設定:
- 初期の数エポックはバックボーン(特徴抽出部)の重みを固定(Freeze)し、最終層のみ学習させてください。
- その後、全層の固定を解除し、非常に小さな学習率(例: 1e-5)で全体を微調整してください。
3. データセット構成:
- 良品データ: [500枚] + Data Augmentation(回転、反転、輝度調整)
- 異常データ: [実データ20枚] + [GAN生成データ480枚]
- 上記をTrain/Val/Testに8:1:1で分割するコードを含めてください。
4. 不均衡対策:
- もし良品と異常のデータ数に偏りがある場合は、Weighted Random Sampler または Focal Loss を実装してください。
学習推移(Loss/Accuracy)のグラフ描画コードと、混同行列(Confusion Matrix)による評価コードも併せて出力してください。
[ここがポイント]
転移学習において、いきなり全層を学習させると、事前学習済みの特徴抽出能力が損なわれることがあります。まずは「重みを固定(Freeze)」して分類層だけ馴染ませるという手順をプロンプトに含めることが、計算リソースを節約しつつ、短期間で検知精度を向上させるためのポイントです。
【Phase 4】生成品質の評価とトラブルシューティング
生成AIにコードを作成させても、初回から完璧に動作するとは限りません。エラーの発生や想定した精度に達しない場合に備え、迅速に改善サイクルを回すための「修正指示(リファクタリング・プロンプト)」を用意しておくことが重要です。
「学習が進まない」時の原因特定プロンプト
Lossが減らない、あるいはAccuracyが50%から変化しない、といった状況に陥ったら、以下のプロンプトで診断してみましょう。
学習を実行しましたが、Lossが減らず、モデルが収束しません。以下の原因について可能性を検討し、チェックすべきポイントと修正コード案を提示してください。
1. 学習率(Learning Rate)が不適切ではないか(学習率スケジューラの実装案)
2. データの前処理(正規化)が、事前学習済みモデルの要件(例: ImageNetの平均・分散の使用)と合致しているか
3. バッチサイズが小さすぎてBatch Normalizationが機能していない可能性はないか
特に2番目の正規化処理について、PyTorchのtorchvision.modelsを使用する場合の正しい前処理コードを再提示してください。
生成画像の品質を評価するコード生成
GANによる生成画像の評価は目視による主観的な判断に依存しがちです。継続的な改善を図るためには、FID (Fréchet Inception Distance) などの指標を用いて定量的に評価する仕組みを構築しておくことが不可欠です。
GANで生成した画像の品質と多様性を評価するために、FIDスコア (Fréchet Inception Distance) を計算するPythonコードを作成してください。実データ群と生成データ群のフォルダパスを入力とし、スコアを出力する関数にしてください。
実装ロードマップ:PoCから本番運用へ
プロンプトを活用してコードが生成できたら、いよいよ実装フェーズです。ここで重要なのは、小さく始めて成果を可視化し、段階的にスケールアップする導入戦略です。まずは「1つの欠陥、1つのライン」に絞ってPoC(概念実証)を進めることを推奨します。
小規模データセットでの検証ステップ
- 実データ20枚でベースライン作成: まずはGANを使わず、手元の少ない異常データだけで転移学習を行い、精度のベースライン(基準値)を定量的に把握します。
- GANによる拡張: プロンプトで生成したコードを使用し、異常データを100枚程度生成します。
- 混合学習: 実データ20枚と生成データ100枚を組み合わせて学習し、ベースラインと比較して検知精度が何パーセント向上するかを検証します。
- 現場検証: 生成された異常画像が物理的にあり得るものか(光の当たり方や影など)を現場の担当者に確認してもらい、フィードバックをモデル改善に活かします。
現場へのモデルデプロイに向けたチェックリスト
- 推論速度: 工場のタクトタイム(生産サイクル)内に判定処理が完了するか。(要件を満たさない場合、モデルの軽量化や量子化を検討します)
- 過検出率: 異常検知において「見逃し」は厳禁ですが、「過検出(良品を異常と判定)」が多発すると現場の確認工数が増大します。運用に合わせた閾値調整の仕組みが必要です。
- モデル更新: 新たなパターンの欠陥が発生した際、迅速にGANでデータを生成し、再学習サイクルを回せるパイプラインが構築されているか。
まとめ
製造現場における「異常データ不足」は、決して乗り越えられない壁ではありません。GANと生成AIプロンプトを効果的に組み合わせることで、外部リソースに過度に依存することなく、社内の体制で解決策を導き出せる可能性が高まります。
今回紹介したプロンプトは、改善活動の起点となるテンプレートです。実際のデータ特性に合わせて、「もっと暗い画像にして」「傷の深さを表現して」と、AIに具体的な指示を出して反復検証を行ってください。データドリブンなアプローチでAIと対話することで、より現場に即したコードへと洗練されていきます。
まずは手元の環境で、最初のプロンプトを試して小さな成果を確認してみてください。現場の知見が反映された「リアルな異常画像」が生成されたとき、生産性向上と品質改善に向けたプロジェクトは確実な一歩を踏み出すはずです。
コメント