「Pythonで学習させたモデル、精度は良いのにマイコンに乗らない」
「C++への移植で、前処理の計算結果が合わない」
「TensorFlow Lite for Microcontrollers(TFLM)のドキュメントが少なすぎて、エラーの原因がわからない」
現場で日々、限られたSRAMやFlashメモリと格闘している皆さんなら、一度はこうした壁にぶつかったことがあるのではないでしょうか?
AIモデルの実装やエッジコンピューティングを専門とするAIエンジニアの原田美咲が、今回はこの課題を乗り越えるためのアプローチを解説します。
私たちは普段、リッチな計算資源を持つクラウド上のAI開発と、数キロバイトを削り出すエッジコンピューティング環境での組み込み開発という、全く異なる2つの世界を行き来しています。この「ギャップ」こそが、TinyML開発の最大のボトルネックです。
でも、もしこのギャップを埋めてくれる優秀な「通訳」がいたらどうでしょう?
今回は、ChatGPTやClaudeなどの生成AIを「TinyML専門のペアプログラマー」として活用し、開発を劇的に加速させるための実践的なテクニックをお話しします。単なるコード生成ではなく、「メモリ制約を理解させた上でのモデル選定」や「Pythonロジックの正確なC++移植」など、AIエンジニアが実務で活用する具体的なプロンプトテンプレートを公開します。
AIという強力なアシスタントと共に、制約だらけのマイコン開発を、もっとクリエイティブで楽しいものに変えていきましょう。
TinyML開発における生成AI活用の勘所
TinyML開発が他のソフトウェア開発と決定的に違うのは、「ハードウェアの物理的な制約」が常に頭上にある点です。一般的なコード生成AIは、放っておくと富豪的なメモリ使いをするPythonコードや、標準ライブラリ(std::vectorなど)を多用したC++コードを書いてしまいがちです。
マイコン開発においてAIを使いこなすための勘所は、「制約条件の数値化」と「役割の明確化」にあります。
PythonとC++の「言語の壁」をAIで埋める
データ分析やモデル構築を担うエンジニアはPythonを好み、組み込みエンジニアはC/C++を操ります。TinyMLプロジェクトでは、この両者のスキルセットが必要不可欠です。しかし、一人の人間が両方を高いレベルで習得するのは容易ではありません。
ここで生成AIの出番です。AIは「多言語話者」であり、PythonのNumPyで行った行列演算を、C++のCMSIS-DSPライブラリを使ったコードに翻訳するのが得意です。重要なのは、単に「翻訳して」と頼むのではなく、「このPythonコードと同じ挙動をする、動的メモリ確保を行わないC++コードを書いて」と指示することです。
リソース制約の数値化がプロンプトの鍵
「軽量なモデルを作って」という指示は、AIにとっては曖昧すぎます。TinyMLにおいては、以下のような具体的な数値を含めることが成功の鍵となります。
- Flashメモリ上限: 例「256KB以内」
- SRAM上限: 例「64KB以内」
- ターゲットデバイス: 例「Arduino Nano 33 BLE Sense (Cortex-M4F)」
- 推論時間: 例「100ms以下」
これらをプロンプトの冒頭(System Prompt的な位置づけ)で宣言することで、AIは「この制約の中で動くコード」を生成しようと努力し始めます。
このテンプレート集の使い方と前提条件
これから紹介するプロンプトテンプレートは、AIエンジニアがエッジコンピューティングの実務で直面する課題を解決するために構築した、実践的なノウハウをベースにしています。以下の点に注意して活用してください。
- []で囲った部分: あなたのプロジェクトに合わせて書き換えてください。
- 検証の重要性とAPIの変更: AIは時折、存在しない関数や、すでに廃止された古いTensorFlow Lite for Microcontrollers (TFLM) のAPIを提案することがあります(ハルシネーション)。特にTensorFlowエコシステムは変化が速く、機能の非推奨化や変更が頻繁に行われます。生成されたコードは必ず公式ドキュメントや実機で検証してください。
- 対象環境: 主にTensorFlow Lite for Microcontrollers、Arduino、ESP32環境を想定しています。
- ※TensorFlowのバージョンや環境(例:Windows環境でのGPUサポート状況の変化など)によって、学習側のPythonコードと推論側のC++ライブラリの整合性が取れなくなる場合があります。AIにコード生成を依頼する際は、使用しているライブラリのバージョンを明示することをお勧めします。
【設計・選定】ハードウェア制約に基づいたモデルアーキテクチャ選定
プロジェクトの初期段階で最も悩ましいのが、「どの程度のモデルなら、このマイコンで動くのか?」という見積もりです。モデルを作り込んでから「メモリに入りませんでした」では目も当てられません。
ここでは、ハードウェアスペックをAIに提示し、実現可能なモデル構成を提案させるアプローチをとります。
テンプレート1:マイコンスペックからのモデル推薦
このプロンプトは、使用するマイコンとやりたいタスク(画像分類、音声認識など)を伝え、適切なモデルアーキテクチャの候補を出させるものです。
特に時系列データ(加速度センサーや音声)を扱う場合、かつてはRNN(LSTM/GRU)が主流でしたが、現在は推論効率や並列処理の観点から1D-CNN(一次元畳み込みニューラルネットワーク)やTCN(Temporal Convolutional Network)への移行が進んでいます。マイコンのDSP命令(SIMD)を有効活用するためにも、AIにはこうした最新の最適化トレンドを含めて提案させましょう。
# 役割定義
あなたは組み込みAIの専門家です。リソース制約の厳しいマイコン環境向けに最適なモデルアーキテクチャを提案してください。
# 制約条件
- ターゲットデバイス: [Arduino Nano 33 BLE Sense]
- プロセッサ: [Arm Cortex-M4F @ 64MHz]
- Flashメモリ: [1MB (モデル格納用に使用可能領域は約500KB)]
- SRAM: [256KB (Tensor Arenaとして使用可能領域は約100KB)]
- タスク: [3軸加速度センサーを用いたジェスチャー認識(4クラス)]
- サンプリングレート: [50Hz]
# 指示
上記の制約条件内で動作し、かつ高精度が期待できるニューラルネットワークアーキテクチャの候補を3つ提案してください。
各候補について以下を明記してください:
1. モデル構造(層の構成、1D-CNN/Dense/TCNなど)
※推論時の並列化効率が低いRNN系よりも、DSP命令を活用しやすいCNN系やTCNを優先検討してください。
2. 推定パラメータ数とモデルサイズ(int8量子化後)
3. 推定推論演算量(FLOPs)
4. このデバイスでの実装実現性(高/中/低)
特に、MobileNetなどの既成モデルを使うべきか、スクラッチで単純なCNNを組むべきかの判断基準も示してください。
出力の活用ポイント:
AIが出してきた「推定モデルサイズ」はあくまで概算ですが、桁違いのミスを防ぐための良い指針になります。特に「Tensor Arena(作業用メモリ)」が足りるかどうかを初期段階で意識できるのが大きなメリットです。
テンプレート2:センサーデータ特性に合わせた入力層設計
センサーデータをそのまま突っ込むのか、FFT(高速フーリエ変換)をかけるのか、スペクトログラムにするのか。前処理によって入力層の形状(Shape)は変わります。これを最適化するためのプロンプトです。
# コンテキスト
[3軸加速度センサー]の時系列データを使って[異常検知]を行いたいです。
# データ特性
- 軸数: 3 (X, Y, Z)
- サンプリング周波数: [100Hz]
- 検出したいイベントの持続時間: [約1秒]
# 相談事項
マイコン上での計算負荷と精度のバランスを考慮し、モデルへの最適な入力データ形式を提案してください。
比較検討項目:
1. 生波形をそのまま入力(Time domain)
2. FFTによる周波数領域特徴量(Frequency domain)
3. スペクトログラム画像(Time-Frequency domain)
それぞれのメリット・デメリットと、Cortex-M4F等のDSP命令を持つマイコンでの実装難易度を評価してください。
これにより、「画像として扱うとメモリを食いすぎるから、1D-CNNで生波形を扱おう」といった意思決定がスムーズになります。
【学習・変換】TFLite Micro向け量子化・変換スクリプト生成
Pythonで学習したKerasモデルなどを、マイコンが解釈できるC言語のバイト配列(unsigned char array)に変換するプロセスについて解説します。
AI業界全体では、LLM(大規模言語モデル)の台頭に伴い、4bitやそれ以下の低ビット量子化(AWQやGPTQなど)や、学習時から量子化を考慮するQAT(Quantization-Aware Training)といった技術が急速に進化しています。しかし、リソースが極端に制限されたマイコン(TinyML/TFLite Micro)環境においては、依然として「int8 完全整数量子化(Full Integer Quantization)」が標準かつ最も安定した解です。
最新のエッジAIトレンドを横目に見つつも、マイコン実務ではこの「int8化」をいかに正確に行うかが、推論速度と精度の生命線となります。不適切な量子化は、実機でのエラーや極端な推論遅延に直結します。
テンプレート3:学習済みモデルのint8量子化スクリプト生成
TensorFlow LiteのコンバータAPIや推奨される量子化手順は、ドキュメントが分散しており複雑になりがちです。特に「入力/出力の型強制」や「代表データセット(Representative Dataset)」の扱いはミスが多発するポイントです。AIに最新のベストプラクティスに沿ったコードを書かせましょう。
# 役割
あなたは組み込みAIおよびTensorFlow Liteのエキスパートです。
# タスク
学習済みのKerasモデル(`model`)を、TensorFlow Lite for Microcontrollers向けに「完全整数量子化(Full Integer Quantization)」し、`.tflite`ファイルとして保存するPythonコードを生成してください。
# 重要な要件
1. 完全整数量子化:
- `converter.optimizations = [tf.lite.Optimize.DEFAULT]` を使用すること。
- `converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]` を指定し、int8演算のみを許可すること。
- 入力と出力のインターフェース型(`inference_input_type`, `inference_output_type`)を `tf.int8` (または `tf.uint8`) に強制すること。
2. 代表データセット:
- `X_train` (numpy array) からランダムにデータをサンプリングして生成するジェネレータ関数(`representative_dataset_gen`)を実装すること。
- データの型キャスト(float32)が必要な場合は適切に処理すること。
3. 検証と出力:
- 変換後のモデルサイズ(バイト数)を表示するコードを含めること。
- TFLite Microで未サポートの演算が含まれていないかチェックするロジック、または変換エラー時のトラブルシューティングのヒントをコメントとして含めること。
# 前提コード
```python
import tensorflow as tf
import numpy as np
# model = ... (学習済みモデルオブジェクト)
# X_train = ... (学習データセット: numpy array, shape=(samples, ...))
### テンプレート4:C配列への変換とヘッダーファイル作成
かつては `xxd` コマンドを使ってバイナリファイルをC配列に変換していましたが、OS間の互換性やビルドパイプラインへの組み込みにくさが課題でした。現在はPythonスクリプト内で完結させ、マイコン開発に最適化されたヘッダーファイルを直接生成するのがスマートです。
```markdown
# タスク
生成された `model.tflite` バイナリファイルを読み込み、C++のヘッダーファイル形式(.h)のテキストとして出力するPythonスクリプトを作成してください。
# 出力フォーマット要件
1. 配列定義:
- 変数名は `g_model` とする。
- データ型は `unsigned char` とする。
- `const` 修飾子をつける。
- TFLite Microの要件に合わせて、アライメント指定(`alignas(16)` または `__attribute__((aligned(16)))`)を含めること。
2. メタデータ:
- 配列の長さを示す定数 `g_model_len` (`int` または `unsigned int`) を定義する。
3. 構造:
- `#ifndef`, `#define`, `#endif` によるインクルードガードを付与する。
- C++コンパイラ用に `extern "C"` ブロックが必要かどうかも考慮した汎用的な記述にする。
# 出力例のイメージ
```cpp
#ifndef MODEL_H
#define MODEL_H
// TFLite Micro requires 16-byte alignment
extern const unsigned char g_model[];
extern const int g_model_len;
#endif
この2段階のプロンプトを活用することで、モデルの学習からマイコンへの組み込み準備までを、ワンクリックで実行可能なパイプラインとして構築できます。手作業によるコマンド入力ミスを防ぎ、モデルの更新サイクルを劇的に短縮できるでしょう。
## 【実装】推論エンジンのC++コード統合とドライバ記述
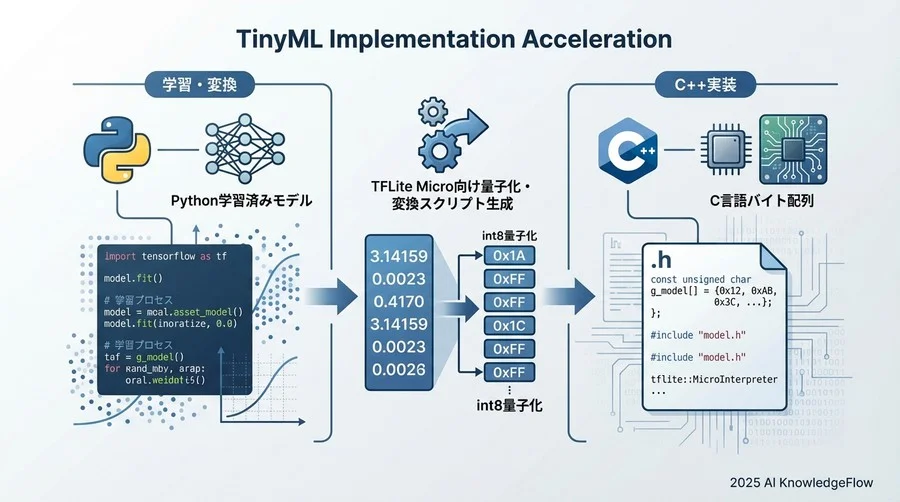
モデルができたら、いよいよマイコン側のファームウェア実装です。ここでは、Pythonで検証した前処理ロジックを、C++で正確に再現する必要があります。
### テンプレート5:TFLMライブラリのセットアップコード生成
`AllOpsResolver`を使うとバイナリサイズが肥大化します。必要なオペレータだけを追加する`MicroMutableOpResolver`の使用を推奨するコードを生成させます。
```markdown
# 役割
Arduino環境でTensorFlow Lite for Microcontrollersを使用する組み込みエンジニア。
# タスク
以下のモデルで使用されているオペレータのみを登録する `MicroMutableOpResolver` のセットアップコードと、インタプリタの初期化コード(C++)を生成してください。
# モデル情報
- 使用しているレイヤー: Conv2D, DepthwiseConv2D, FullyConnected, Softmax, Reshape
- 必要なTensor Arenaサイズ: 約[20]KB(仮定)
# 要件
- `tflite::MicroErrorReporter` を使用。
- `tflite::MicroInterpreter` のインスタンス化。
- Tensor Arenaのメモリ確保(静的配列として確保)。
- `setup()` 関数内に記述する初期化フローを示してください。
テンプレート6:センサーデータの前処理C++コード変換
Pythonでの (x - mean) / std といった正規化処理を、マイコン上のC++で実装します。浮動小数点演算を避けるべきかどうかも相談できます。
# 入力コード(Python)
以下のPythonの前処理ロジックを、Arduino (C++) コードに変換してください。
```python
def preprocess(acc_data):
# acc_dataは [ax, ay, az] のリスト。単位は G。
# 重力加速度成分を除去(ハイパスフィルタ相当の簡易処理)
gravity = 0.9 * gravity + 0.1 * acc_data
linear_acc = acc_data - gravity
# 値を -2.0 ~ 2.0 の範囲でクリッピングし、-128 ~ 127 (int8) に量子化
normalized = clip(linear_acc, -2.0, 2.0)
quantized = int(normalized / 4.0 * 255)
return quantized
要件
- グローバル変数やstatic変数を使って状態(gravity)を保持してください。
- 入力モデルの量子化パラメータ(Scale, Zero Point)を考慮し、TFLiteモデルの入力テンソル(
input->data.int8[i])に直接値をセットする形式にしてください。 - 可能な限り高速な演算を使用してください。
これにより、PythonとC++の間で「計算結果が微妙に違う」という問題を最小限に抑えられます。
## 【最適化】メモリ・レイテンシ制約をクリアするためのリファクタリング
実装してみたものの、「推論に時間がかかりすぎてセンサーデータの取りこぼしが起きる」「スタックオーバーフローで落ちる」といった問題が発生した際の対策です。
### テンプレート7:推論速度向上のための演算最適化
```markdown
# 現状の課題
Arduino Nano 33 BLE Senseで推論を実行していますが、推論時間が[150ms]かかっており、目標の[50ms]を満たせません。
# コード断片
[現在使用しているメインループと推論実行部分のコードを貼り付け]
# 依頼事項
推論速度を向上させるための具体的な改善案と、修正後のコード例を提示してください。
考慮してほしい点:
1. CMSIS-NN ライブラリが有効になっているかどうかの確認方法
2. コンパイラ最適化オプション(-O3など)
3. モデルの量子化状態(float32で推論していないか確認)
4. 入力データ処理のループ展開や効率化
テンプレート8:SRAM使用量削減のためのコードレビュー
# 役割
組み込みC++のコードレビュアー。
# 課題
SRAMの使用量が限界に近く、動作が不安定です。メモリ使用量を削減したいです。
# コード
[メモリを消費していそうな部分のコードや、グローバル変数の定義部分]
# 依頼事項
メモリ効率の観点からコードレビューを行い、以下の点を指摘してください。
1. 不要なバッファや重複したデータ保持がないか
2. `tensor_arena` のサイズは適切か(実験的に最小サイズを見つける方法)
3. 変数のスコープやデータ型の最適化(int32 -> int16など)
AIは「ここ、floatの配列を2つ持っていますが、1つを使い回せませんか?」といった鋭い指摘をしてくれることがあります。
開発フェーズ別プロンプト活用チートシート
最後に、これまでのプロンプトをどのタイミングで使うべきか、開発フローに沿って整理しました。これを手元に置いておくだけで、開発の手戻りを防げます。
フェーズごとの推奨プロンプト一覧
| 開発フェーズ | 課題 | 推奨テンプレート | 期待される成果 |
|---|---|---|---|
| 1. 要件定義・設計 | ハードウェア選定の不安 | テンプレ1, 2 | 実現可能なモデルアーキテクチャの特定 |
| 2. モデル学習 | 量子化の複雑さ | テンプレ3 | エラーのないtfliteファイル生成 |
| 3. コード変換 | 手作業によるミス | テンプレ4 | C++ヘッダーファイルの自動生成 |
| 4. ファームウェア実装 | Pythonロジックの移植 | テンプレ5, 6 | TFLM初期化と前処理の正確な実装 |
| 5. テスト・最適化 | メモリ不足・速度不足 | テンプレ7, 8 | ボトルネック解消とリソース削減 |
AIからの回答が不正確な場合の修正指示パターン
AIがハルシネーション(嘘)をついた時の対処法も覚えておきましょう。
- 存在しない関数を使われた時: 「その関数は現在のTFLMライブラリ(バージョン2.x系)には存在しないようです。
tflite::MicroInterpreterクラスにあるメソッドのみを使用してください。」 - メモリ確保が動的な時: 「組み込み環境なので
newやmallocは使用禁止です。静的な配列確保、またはスタック利用に書き換えてください。」 - ライブラリ依存が不明な時: 「このコードをコンパイルするために必要な
#include文と、platformio.iniに記述すべきライブラリ依存関係を教えてください。」
まとめ:AIを味方につけ、エッジの限界を突破する
TinyML開発は、制約との戦いです。しかし、その制約の中にこそ、エンジニアとしての創意工夫の余地があります。今回紹介したプロンプトテンプレートを活用することで、ボイラープレートコードの記述や単純な変換作業から解放され、より本質的な「どんなデータをどう処理すれば価値が生まれるか」という部分に集中できるようになるはずです。
AIは魔法の杖ではありませんが、使い方次第で最強の工具になります。ぜひ、あなたのツールボックスにこれらのプロンプトを加えてみてください。
「テンプレートを使ってみたけれど、特殊なセンサーへの対応で詰まってしまった」
「自社の独自ボード向けに最適化したいが、AIの回答だけでは解決できない」
もしそんな課題に直面しても、立ち止まる必要はありません。プロジェクト固有の制約条件を改めて整理し、センサーデータ解析の知見を活かして最適なモデル設計から実装までを追求し続けることが、小さなデバイスで大きなイノベーションを起こす鍵となります。
コメント