「触るな危険」のコードと対峙するあなたへ
「この関数、触ったら何が起きるか分からないから、とりあえずコピーして別名で作ろう……」
開発現場でこのような会話を耳にすることは少なくありません。
仕様書は10年前の日付で止まっており、当時の担当者は既に退職済み、テストコードも存在しない。
いわゆる「塩漬けコード」や「スパゲッティコード」と呼ばれるレガシーなシステムに対して、機能追加や改修を行わなければならない時のストレスは計り知れません。
多くのエンジニアが生成AI(LLM)に期待するのは、「魔法のようにコードを書き直してくれること」でしょう。しかし、AIソリューションアーキテクトの視点から見ると、いきなりAIにコードを書き換えさせるアプローチは推奨できません。
それは、地雷原を地図なしで走るようなものです。LLMの真価は、コードを自動生成すること以上に、「人間には読み解くのが辛い複雑なコードを、文脈を汲み取って論理的に解説してくれる」点にあります。
今回は、LLMを単なる「コード生成機」としてではなく、未知の遺跡を調査する「専属のコード考古学者」として活用する実践的な手法を解説します。恐怖心を安心感に変える、実証に基づいたテクニックです。
なぜ「塩漬けコード」にLLMが効くのか?
レガシーコードの修正作業において、実際にコードをタイピングしている時間はどれくらいでしょうか。
一般的な開発現場のデータでは、作業時間の約8割が「既存コードの理解(リーディング)」に費やされているという報告もあります。変数の値がどこで変わり、どの関数がどこに影響しているのかを脳内でトレースする作業。これこそが、精神的な疲労(コグニティブ負荷)の正体です。
人間には辛い「解読作業」をAIに肩代わりさせる
LLM(大規模言語モデル)は、自然言語処理の技術、特にTransformerモデルの仕組みをベースにしています。プログラミング言語もまた規則性を持った「言語」であり、LLMはコードの構造だけでなく、変数名やコメントの断片から全体の「文脈」を推測することに長けています。
人間が数時間かけて解読する「ネストが深すぎる条件分岐」も、LLMなら数秒で要約できます。効果的なアプローチは、「修正案を出させる前に、徹底的に解説させる」ことです。まずはAIを使って、ブラックボックスの中身を論理的に明るく照らすことから始めましょう。
「コード考古学」の相棒としてのLLM
ドキュメントがないコードは、古代の石板と同じです。書かれた背景や意図が失われています。
LLMは、残されたコードという「遺物」から、当時の設計者の意図を推論する強力なパートナーになります。「なぜここでこの変数をリセットしているのか?」といった疑問を投げかけることで、AIはコードの行間にあるロジックを分かりやすい言葉で言語化してくれます。
Tip 1:仕様推測のための「逆設計図」プロンプト
ここからは具体的なテクニックに入ります。まずは、仕様書が存在しないコードから、仕様を「逆算」してドキュメント化する方法です。
よくある間違いは、「このコードを解説して」とだけ投げてしまうことです。これでは「for文でループしています」といった、見れば分かるレベルの回答しか得られません。
「何をしているか」ではなく「なぜそう書かれたか」を聞く
ビジネスロジックを抽出するには、視点を一段高くした指示が必要です。
以下のような、可読性の低いコード(悪い例)があったと仮定します。
// よくあるレガシーコードの例
function calc(a, b, t) {
let r = 0;
if (t === 1) {
if (a > 100) r = a * 0.9; else r = a;
} else if (t === 2) {
r = a - b;
if (r < 0) r = 0;
}
return r;
}
このコードの意図を探るためのプロンプトは以下の通りです。
【実践プロンプト:逆設計図生成】
あなたは優秀なシステムエンジニアです。
以下のコードはドキュメントが存在しないレガシーコードです。
コードの挙動から、背後にある「業務要件」や「ビジネスルール」を推測し、仕様書として出力してください。
## 制約条件
- コードの行単位の解説は不要です。
- 「入力」「処理ロジック」「出力」の観点でまとめてください。
- 条件分岐が複雑な場合は、Markdownの表形式(デシジョンテーブル)で条件と結果の組み合わせを網羅してください。
- 変数名が不明瞭な場合、文脈から適切な名前を推測して提案してください。
## 対象コード(逆設計図生成)
[ここにコードを貼り付け]
入出力のパターンからビジネスロジックを言語化させる
このプロンプトを使うと、LLMは単なるコードの直訳ではなく、「tは取引タイプ(Transaction Type)の可能性が高く、1は割引適用、2は減算処理(ポイント利用など)を示唆している」といった、意味論的な推測を行ってくれます。
特にデシジョンテーブル(決定表)を出力させることで、複雑なif文の網羅性を視覚的に確認できるため、人間が見落としていたロジックの穴に気づきやすくなります。
Tip 2:隠れた「時限爆弾」を見つけるエッジケース検知
レガシーコードが怖いのは、特定の条件下でのみ発生するバグ(時限爆弾)が埋まっている可能性があるからです。リファクタリング中にこれを踏んでシステムを停止させるのが、最も避けたい事態です。
正常系バイアスを打破する「意地悪なレビュアー」役
人間はどうしても「正しく動くルート(正常系)」ばかりを目で追ってしまいます。そこで、AIに「性格の悪いQA(品質保証)担当」になってもらいましょう。
【実践プロンプト:エッジケース探索】
あなたは非常に厳格で、意地悪な視点を持つセキュリティエンジニアです。
以下のコードに潜んでいる可能性のあるバグ、エッジケース、クラッシュする条件を3つ以上指摘してください。
## 指示(エッジケース探索)
- 「通常は起きないが、理論上ありえる入力」を想定してください。
- Null/Undefined、型不整合、境界値(0, 負の数, 最大値)に関するリスクを優先して指摘してください。
- それぞれのリスクについて、具体的な「攻撃コード」または「再現データ」を例示してください。
## 対象コード(エッジケース探索)
[ここにコードを貼り付け]
境界値と異常系に特化したバグ探索
このプロンプトを実行すると、「引数bがnullの場合に計算がNaNになる」「aが極端に大きい数値の場合、オーバーフローする可能性がある」といった論理的な指摘が得られます。
AIに指摘された箇所は、修正時の「重点確認ポイント」になります。これらを事前に把握しておくことで、改修の安全性は飛躍的に高まります。
Tip 3:安全ネットを張るための「現状維持テスト」生成
「テストがないからリファクタリングできない。リファクタリングできないからテストが書けない」
このジレンマを解消するのが、「現状維持テスト(Characterization Test)」です。
これは、「仕様として正しいか」ではなく、「現在の挙動(バグも含めて)が変わらないこと」を保証するテストです。リファクタリング中のデグレ(機能破壊)を防ぐための強固な命綱となります。
リファクタリング前の「スナップショットテスト」
LLMを使って、現在のコードの挙動を固定化するテストケースを大量生成させましょう。
【実践プロンプト:現状維持テスト生成】
あなたはテスト自動化のスペシャリストです。
以下のレガシーコードのリファクタリングを行いますが、既存の挙動を壊さないための「現状維持テスト」を作成してください。
## 要件
- テストフレームワークは [Jest / PyTest / JUnit など使用言語に合わせて指定] を使用。
- 正常系だけでなく、境界値や異常値を含む多様な入力パターンを用意すること。
- 期待される出力値(Expected)は、現在のコードの実際の実行結果と一致させてください(たとえそれが論理的にバグに見えても、今の挙動を正とします)。
- パラメータ化テスト(Table Driven Test)の形式で記述し、網羅性を高めてください。
## 対象コード(現状維持テスト生成)
[ここにコードを貼り付け]
既存の挙動を保証するテストケースの大量生成
このプロンプトで生成されたテストコードを実行し、すべてPASSすることを確認してから作業を始めます。もしリファクタリング中にテストが落ちたら、それは「挙動を変えてしまった」という明確な警告です。
この安全ネットがあるだけで、エンジニアの心理的負担は劇的に軽減されます。
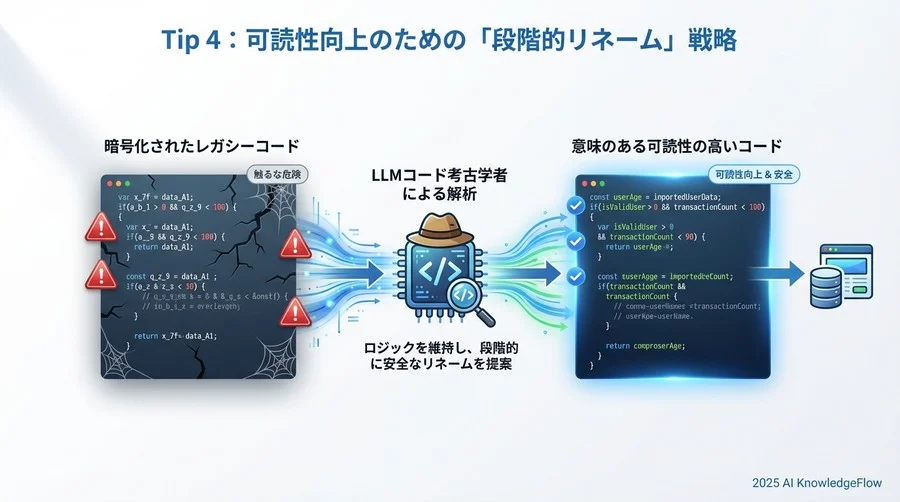
Tip 4:可読性向上のための「段階的リネーム」戦略
構造を大きく変えるのはリスクが高いですが、変数名や関数名を分かりやすくするだけなら、リスクは比較的低く、かつ効果は絶大です。
ロジックを変えずに名前だけを変える
先ほどのcalc(a, b, t)のようなコードに対し、LLMに適切なネーミングを提案させます。
【実践プロンプト:リネーム提案】
以下のコードは可読性が低く、保守が困難です。
ロジックは一切変更せず、変数名と関数名だけを「自己文書化」された分かりやすい名前に変更したコードを提示してください。
## ルール
- 略語(t, val, data等)は避け、具体的なビジネス用語を使用すること。
- コード内に、変更理由を説明するコメントを補足すること。
- 元のロジック構造(if文のネストなど)は維持すること(diffを取りやすくするため)。
## 対象コード(リネーム提案)
[ここにコードを貼り付け]
認知負荷を下げる変数名の提案
例えば、tがtransactionTypeに、calcがcalculateDiscountedPriceに変わるだけで、コードを読むスピードは倍増します。
いきなりクラス設計を見直すのではなく、まずは「名前を変える」という小さな一歩から始めましょう。これはチームメンバー全員にとって非常に有益な変更です。
Tip 5:小さな関数への切り出しと依存関係の整理
数百行に及ぶ「神クラス」や「神関数」は、レガシーコードの典型です。これらを安全に解体するには、依存関係の論理的な整理が不可欠です。
スパゲッティコードを「一口サイズ」にほぐす
LLMに、コードの塊から「独立して切り出せる部分」を見つけてもらいます。
【実践プロンプト:関数抽出の提案】
以下の長い関数を、保守性を高めるために小さな関数に分割したいと考えています。
## 指示(関数抽出の提案)
- 外部の変数(グローバル変数やクラスメンバ)への依存が少なく、独立した関数として切り出しやすいブロックを特定してください。
- 切り出した関数の入力(引数)と出力(戻り値)を明記してください。
- 元の関数が、切り出した関数を呼び出す形にリファクタリングしたコード例を示してください。
## 対象コード(関数抽出の提案)
[ここにコードを貼り付け]
副作用のない純粋関数の抽出
特に、計算ロジックなどの「副作用のない処理(純粋関数)」を切り出すことができれば、その部分だけを単体テストすることが容易になります。
複雑に絡み合ったスパゲッティも、一本ずつ麺を取り分けるように整理していけば、いずれは保守しやすい状態に戻すことができます。
まとめ:AIは「魔法の杖」ではなく「高性能な懐中電灯」
ここまで、レガシーコードに対するLLM活用法を紹介してきました。
重要なのは、AIに「全自動で直してもらう」のではなく、「暗闇を照らすための明かり」として使うというマインドセットです。
- 逆設計図プロンプトで、仕様を可視化する。
- エッジケース検知で、地雷の位置を把握する。
- 現状維持テストで、安全ネットを張る。
- 段階的リネームで、可読性を上げる。
- 関数切り出しで、少しずつ構造を改善する。
セキュリティへの配慮(機密情報の扱い)
最後に一つ、重要な注意点です。業務コードをLLMに入力する際は、組織のセキュリティ規定を必ず確認してください。
機密情報(APIキー、個人情報、具体的な顧客名など)は、必ずダミーの値(API_KEY_XXXXなど)に置換してからプロンプトに含めるようにしましょう。この「マスキング処理」自体も、ローカル環境のスクリプト等で行うのが鉄則です。
さらなる実践知見を求めて
今回ご紹介したのは、実際の開発現場で有効とされる手法の一部です。実際のプロジェクトでは、CI/CDパイプラインへの組み込みや、より大規模なアーキテクチャ刷新におけるAI活用など、さらに踏み込んだ戦略が必要になります。
恐怖におびえながらコードを触る日々を終わらせ、実証データと論理的なアプローチに基づき、自信を持ってリファクタリングできる環境を構築していきましょう。
コメント