終わらないRAGのチューニングに疲れていませんか?
「チャンクサイズ(テキストの分割単位)はどうする?」「ベクトル検索の精度が出ない」「ドキュメント更新の仕組みが複雑すぎる」
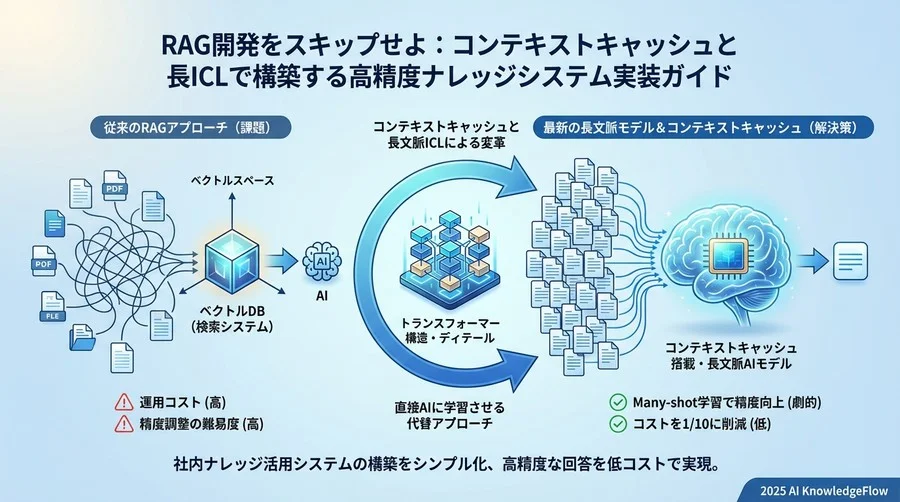
社内ナレッジシステムの開発現場では、こうしたRAG(検索拡張生成)特有の悩みがよく聞かれます。一般的に、RAGの構築や運用にかかるコストが、当初の想定を遥かに超えてしまうという課題は珍しくありません。多くの組織において、複雑なチューニング作業や継続的なメンテナンスの負荷が、AIシステム定着の大きな障壁となっています。
しかし、技術の潮目は大きく変わりました。GeminiやClaudeといった超長文脈(Long Context)モデルの進化が、その背景にあります。特にClaudeは旧モデルから新たなモデルファミリーへと移行を遂げ、より高度な推論能力と長大なコンテキスト(文脈)処理を実現しています。こうした基盤モデルの進化と、一度読み込んだ情報を記憶しておくContext Caching(コンテキストキャッシュ)機能の実装により、必ずしもRAGを構築することが最適解ではなくなりました。
今回は、あえて「RAGを作らない」という選択肢を論理的に紐解いていきます。数千ページに及ぶマニュアルやFAQを丸ごとモデルに読み込ませ、キャッシュ機能で計算コストを抑えながら、Many-shot In-Context Learning(ICL:多数の例示を用いた文脈内学習)によって高精度な回答を引き出します。旧来の複雑な仕組みに依存せず、最新アーキテクチャのポテンシャルを直接引き出す実践的な手法です。
このシンプルかつ強力なアプローチを、机上の空論ではなく、実際に動くPythonコードとともに順を追って明快に解説します。数週間の開発工数を数日に短縮する、新しい手法の実証プロセスを見ていきましょう。
1. 本ガイドの目的と到達点
まず、今回構築するシステムの全体像と、なぜこのアプローチが有効なのかを論理的に整理しておきます。
なぜ今、長文脈ICL(In-Context Learning)なのか
これまでのLLM(大規模言語モデル)は、一度に入力できる情報量(コンテキストウィンドウ)に厳しい制限がありました。そのため、外部データベースから必要な情報だけを検索して継ぎ足す「RAG」が必須だったのです。
しかし、現在は100万〜200万トークン(日本語で数百万文字相当)を一度に処理できるモデルが利用可能です。これは、分厚い技術書数十冊分に相当します。つまり、「検索せずに全部読ませればいい」という力技が、実証可能なレベルで実現できるようになりました。
RAG構築とのコスト・精度比較
「全部読ませるとAPI利用料が膨大になるのでは?」
非常に論理的な疑問です。通常、毎回100万トークンを送信すれば、コストは跳ね上がります。そこで登場するのがContext Cachingです。一度読み込ませたプロンプト(ドキュメント群)をキャッシュ(一時保存)し、2回目以降の入力トークン課金を劇的に(最大90%以上)削減する技術です。
| 項目 | 従来のRAG | 長文脈ICL + キャッシュ |
|---|---|---|
| アーキテクチャ | 複雑(ベクトルDB、Embeddingモデル必須) | シンプル(LLMのみ) |
| 情報の網羅性 | 検索漏れのリスクあり | 全情報を参照可能 |
| 回答精度 | 検索精度に依存 | モデルの推論能力に依存 |
| 初期開発工数 | 高い(数週間〜数ヶ月) | 低い(数日) |
| 運用コスト | DB維持費 + 都度Embedding | キャッシュ維持費 + 推論費 |
特に、社内規定やマニュアルのように「頻繁には変わらないが、参照時には正確性が求められる」データにおいて、このアプローチは実証データからも圧倒的なパフォーマンスを発揮する傾向にあります。
本ガイドで構築する環境の構成図
今回目指すのは、以下のようなシンプルな構成です。
- データ準備: PDFやMarkdownなどの社内ドキュメントを、AIが理解しやすい構造化テキストに変換。
- キャッシュ作成: ドキュメント群とシステムプロンプトをLLMに送信し、キャッシュIDを取得。
- 推論実行: ユーザーの質問とキャッシュIDを使って回答を生成。
ベクトルDBも、テキストを数値化するEmbedding処理も不要です。それでは、具体的な実装手順を見ていきましょう。
2. 事前準備と環境要件
実装に入る前に、必要なツールとアクセス権限を確認します。特に長文脈を扱うモデルは更新が速いため、最新のモデル状況や仕様変更を常にキャッチアップしておくことが重要です。
必要なAPIキーとアクセス権限
本ガイドでは、コンテキストキャッシュ機能や長文脈処理が利用可能な以下のいずれかのAPIを想定しています。
- Gemini API: Google AI StudioでAPIキーを取得できます。Geminiではコンテキストキャッシュ機能が利用可能です。機能の提供状況や仕様は頻繁に更新されるため、必ず公式ドキュメントで最新情報を確認してください。
- Claude API: Anthropic Consoleで設定します。
- 注意と最新動向: 旧モデルの提供は順次非推奨となるため、計画的なモデル移行が必要です。最新のアップデート(Sonnet 4.6等)では、前モデル(Sonnet 4.5等)と比較してコーディングや長文推論、エージェント機能が大幅に向上しています。さらに、タスクの複雑度に応じて思考の深さを自動調整する「Adaptive Thinking」機能(APIリクエスト時に
thinking={"type": "adaptive"}を指定)や、ベータ版での最大100万トークン対応、コンテキスト上限近辺で自動サマリーを行うCompaction機能などが追加されています。利用可能な最新のモデルIDや新機能の詳細は、必ず公式ドキュメントを参照してください。
- 注意と最新動向: 旧モデルの提供は順次非推奨となるため、計画的なモデル移行が必要です。最新のアップデート(Sonnet 4.6等)では、前モデル(Sonnet 4.5等)と比較してコーディングや長文推論、エージェント機能が大幅に向上しています。さらに、タスクの複雑度に応じて思考の深さを自動調整する「Adaptive Thinking」機能(APIリクエスト時に
今回は、コード例としてPython SDKが充実しているGemini APIを使用しますが、基本的な考え方はClaude APIでも同様です。
Python開発環境のセットアップ
以下のライブラリを使用します。仮想環境(venvなど)を作成し、インストールしてください。
pip install -q -U google-generativeai python-dotenv
.envファイルを作成し、APIキーを環境変数として設定しておきましょう。
# .env
GOOGLE_API_KEY="your_api_key_here"
トークン計算ライブラリのインストール
コスト管理のために、トークン数(AIが処理するテキストの単位)を正確に把握することは非常に重要です。Geminiの場合はSDKにカウント機能が含まれていますが、一般的な概算にはtiktokenなどのライブラリも便利です。今回はSDKのカウント機能を使用します。長文脈を扱うシステムでは、コンテキストウィンドウの上限やAPI利用制限(Rate Limit)に意図せず達してしまうことを防ぐため、リクエスト前の正確なトークン計算がより一層求められます。
3. ステップ1:データセットの構造化とトークン最適化
ここがシステム最適化の要となります。単にテキストをベタ貼りするのではなく、LLMが「どこに何が書いてあるか」を論理的に理解しやすい形式に変換します。
非構造化ドキュメントのテキスト抽出
PDFやWordファイルからテキストを抽出する際は、見出しや箇条書きの構造を維持することが重要です。単なる文字列の羅列になってしまうと、モデルが文脈を正確に追えなくなります。
例えば、社内規定のPDFがある場合、以下のようなMarkdown形式への変換を目指してください。
# 第1章 総則
## 第1条(目的)
本規定は、社員の...
XMLタグを活用した情報の区分け
長文脈プロンプトにおいて、XMLタグは非常に強力な区切り文字として機能します。モデルに対して「ここからここまでがマニュアルAです」と明示的に伝えるためです。
以下のような構造化を行うPython関数のイメージです。
def format_document(title, content, doc_id):
return f"""
<document id="{doc_id}">
<title>{title}</title>
<content>
{content}
</content>
</document>
"""
複数のドキュメントを結合する際は、これらを<knowledge_base>タグで囲みます。
<knowledge_base>
<document id="doc1">...</document>
<document id="doc2">...</document>
...
</knowledge_base>
不要なメタデータの削除とトークン節約
100万トークン使えるといっても、無駄な情報はノイズになりますし、キャッシュコストもかかります。効率的な解決策を追求するためには、以下の整理が必要です。
- ヘッダー・フッター: ページ番号や「社外秘」といった繰り返されるテキストは削除します。
- URLの羅列: リンク先の内容を読み込めない場合は、単なる文字列として扱い、場合によっては削除します。
- 重複: 同じ内容のFAQが含まれていないかチェックします。
この「データクリーニング」の工程が、最終的な回答精度を左右します。ここは従来のRAGと同じく、仮説検証を繰り返しながら丁寧に行うべきステップです。
4. ステップ2:コンテキストキャッシュの実装
いよいよ核心部分です。Google Gen AI SDKを使って、作成したコンテキストをキャッシュします。
Context Caching機能のAPI設定手順
通常のAPIコールとは異なり、まずキャッシュオブジェクトを作成し、それをモデルに渡す形になります。
import os
import google.generativeai as genai
from google.generativeai import caching
import datetime
# APIキーの設定
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])
# 読み込ませるドキュメント(実際はファイルから読み込む)
huge_context_text = """
<knowledge_base>
...(ここに数万〜数十万文字のテキストが入る)...
</knowledge_base>
"""
# キャッシュの作成
# TTL(生存期間)を設定します。ここでは60分とします。
cache = caching.CachedContent.create(
model="models/gemini-1.5-pro-001",
display_name="company_manual_cache",
system_instruction="あなたは社内規定の専門家です。提供されたknowledge_baseに基づいて回答してください。",
contents=[huge_context_text],
ttl=datetime.timedelta(minutes=60),
)
print(f"Cache created: {cache.name}")
このコードを実行すると、Googleのサーバー側にコンテキストが保存され、参照用のID(cache.name)が返されます。
キャッシュのTTL(生存期間)管理
キャッシュには生存期間(TTL)があります。デフォルトでは短めに設定されていることが多いので、業務時間に合わせて延長する必要があります。また、キャッシュストレージにもコストがかかる(通常、時間単位×データ量)ため、夜間や休日には自動的に切れるように設計するか、明示的に削除する処理を入れるのが実践的です。
# キャッシュの更新(TTLの延長)
cache.update(ttl=datetime.timedelta(hours=2))
# 不要になったら削除
# cache.delete()
コスト試算と最適化ロジック
ここでコスト感覚を持っておきましょう。例えばGeminiの場合(※価格は変動します)、キャッシュ入力は通常入力の数分の一の価格設定になっています。
- 通常入力: $3.50 / 1M tokens
- キャッシュ入力: $0.875 / 1M tokens
- キャッシュストレージ: $4.50 / 1M tokens / hour
頻繁にクエリが発生する場合、毎回フルコンテキストを送るよりも、ストレージ代を払ってキャッシュした方が圧倒的に安くなります。「1時間に何回以上質問が来るならキャッシュがお得か」という損益分岐点を論理的に計算しておくことが、システム最適化の重要なポイントです。
5. ステップ3:Many-shotプロンプトの設計と実行
キャッシュのおかげで、コンテキストウィンドウに余裕ができました。ここでRAGでは難しかったMany-shot Learningを投入します。
数百の事例を含めるMany-shotプロンプトの構成
Few-shot(数個の例示)ではなく、Many-shot(数十〜数百の例示)を行うことで、モデルはタスクのパターンをより深く、実証的に理解します。
例えば、「ユーザーの曖昧な質問」と「理想的な回答(根拠となる条文付き)」のペアを100個ほど用意し、それもキャッシュに含めてしまいます。
<examples>
<example>
<user_query>交通費ってどこまで出るの?</user_query>
<ideal_answer>旅費規程 第3条に基づき、自宅から勤務地までの最短経路の定期代が支給されます。特急料金は原則として認められませんが、第5条の例外規定により...</ideal_answer>
</example>
<!-- これを大量に繰り返す -->
</examples>
これにより、モデルは「条文を引用して回答する」というスタイルを強力に学習します。
「Lost in the Middle」現象への対策配置
長文脈モデルには、入力の中間部分にある情報を忘れやすいという「Lost in the Middle」現象が報告されています。最新モデルでは改善されていますが、念のため重要な指示(システムプロンプトや制約条件)は、コンテキストの最初と最後の両方に配置するサンドイッチ構造が有効です。
推論実行用Pythonスクリプトの作成
作成したキャッシュを使って、実際にチャットを行うコードです。
# キャッシュを指定してモデルを初期化
model = genai.GenerativeModel.from_cached_content(cached_content=cache)
chat = model.start_chat()
def ask_question(query):
response = chat.send_message(query)
print(f"User: {query}")
print(f"AI: {response.text}")
print(f"Usage: {response.usage_metadata}") # トークン使用量の確認
# テスト実行
ask_question("来週から育休を取りたいんだけど、手続きはどうすればいい?")
このresponse.usage_metadataを確認すると、入力トークン数がキャッシュのおかげで非常に少なくなっている(キャッシュヒットしている)ことが確認できるはずです。
6. ステップ4:精度検証とトラブルシューティング
実装したら、必ず検証を行います。RAGと比較してどうなのか、定量・定性の両面から実証データに基づいてチェックします。
回答精度の定性・定量評価
実務において推奨されるのは、実際の業務で発生した過去の質問リスト(ゴールデンデータセット)を用意し、以下の観点でスコアリングすることです。
- 正確性: 間違った情報を言っていないか。
- 網羅性: 関連する複数の規定を横断して回答できているか(これがRAGの苦手分野であり、長文脈ICLの得意分野です)。
- 根拠: 参照元の条文やページ数を正しく示せているか。
特に「網羅性」において、ドキュメント全体を俯瞰できる長文脈モデルの強みが発揮されるはずです。
ハルシネーションの検知と抑制
コンテキスト内にある情報だけで回答させるために、プロンプトの最後に以下の制約を強く加えます。
「回答は必ず提供された
<knowledge_base>内の情報のみに基づいて作成してください。情報が見つからない場合は、正直に『規定内に情報が見当たりません』と答えてください。」
また、Many-shotの例示の中に、「情報がない場合の回答例」を含めておくことも、ハルシネーション(もっともらしい嘘)の抑制に非常に効果的です。
エラーハンドリングとリトライ設計
キャッシュのTTL切れによるエラー(404 Not Foundなど)は必ず発生します。エラーハンドリングとして、「キャッシュが見つからない場合は、再度キャッシュ作成フローを走らせる」ロジックを実装しておくことが、商用利用では必須となります。
シンプルさがもたらす競争力
RAGは素晴らしい技術ですが、複雑さはバグの温床であり、メンテナンスコストの増大を招きます。
今回解説した「コンテキストキャッシュ + Many-shot ICL」のアプローチは、「AIにドキュメントを読ませる」という原点回帰でありながら、最新モデルの能力を最大限に活かした合理的かつ実践的なソリューションです。ベクトルDBの調整に費やしていた時間を、より本質的な「どんなデータを読ませるか」「どんな回答をユーザーに届けたいか」というUX設計に使ってみてください。
もし、社内データの構造化が難しい、あるいはこのアーキテクチャを既存システムにどう組み込めばいいか迷っている場合は、専門家に相談してPoC(概念実証)を進めることも一つの有効な手段です。まずはドキュメントの一部を使って、最新モデルの「賢さ」を実証してみることをおすすめします。
コメント