大規模なAIモデルの学習中、ログに突如として現れる「NaN(Not a Number)」のエラー。数日間の計算リソースと時間が、たった一つの数値オーバーフローで無に帰す瞬間は、プロジェクトの進行において大きな痛手となります。
学習時間を短縮し、メモリ効率を劇的に改善する「混合精度演算(Mixed Precision)」は、現代のAI開発において必須の技術ですが、同時に非常に扱いが難しい側面を持っています。
FP16(半精度浮動小数点数)の狭いダイナミックレンジを管理し、勾配消失や発散を防ぐための繊細な制御。そして、GPUアーキテクチャごとに異なるCUDAバージョンとライブラリの整合性管理。これらをすべて手動で完璧に行うには、膨大な知識と検証時間が必要です。
現代のシステム開発やデータ分析の現場では、開発スピードとプロジェクトの円滑な進行が極めて重要です。複雑な環境設定や数値安定性の管理は、AI(LLM)を活用することで大幅に効率化できます。
今回は、混合精度演算の実装と環境構築をAIに安全に行わせるための、実務ですぐに使えるプロンプトテンプレートを解説します。技術的な実現可能性とビジネス上の成果を両立させるため、まずは確実かつ高速に動作する環境を構築しましょう。
なぜ混合精度演算の設定をAIに任せるべきなのか
混合精度演算は、単にコード上でフラグを有効にすれば済むものではありません。特にPyTorchなどのフレームワークで独自の学習ループを構築している場合、その実装難易度は高まります。ハードウェアの進化が加速する現在、設定の最適解は常に変化し続けているため、プロジェクトマネジメントの観点からも効率的な対応が求められます。
FP16/BF16利用時の「数値安定性」の壁
通常のFP32(単精度)に比べ、FP16(半精度)は表現できる数値の範囲が極端に狭くなります。AIモデルの学習時、勾配はしばしば非常に小さな値になりますが、FP16ではこれがゼロになってしまう「アンダーフロー」が頻発します。逆に、大きな値はすぐに無限大へと発散してしまいます。
これを防ぐために「損失スケーリング」という技術を使いますが、スケーリング係数の調整を誤れば、学習はまったく収束しません。さらに直近の動向として、最新のNVIDIA GPUアーキテクチャでは、FP16からさらに計算負荷の低いFP8やFP4への最適化が主流へとシフトしています。同時に、FP32専用の演算器が廃止され、低精度ユニットを組み合わせた擬似的な処理に移行する動きも見られます。
一方で、BF16(BFloat16)は依然として標準的な学習精度として広く利用されています。単にFP16を使うのではなく、環境に合わせてBF16を選択したり、将来を見据えてFP8への移行を検討したりと、数値計算の複雑な仕様を人間がコードレビューだけで見抜くのは非常に困難な状況です。
環境依存(GPUアーキテクチャ)による最適設定の複雑さ
GPUの世代によって、計算を高速化するTensor Coreが有効になる条件や、最適なライブラリの組み合わせは全く異なります。
例えば、少し前の世代であるAmpereアーキテクチャ(A100など)では、TF32というモードがデフォルトで有効になりますが、これを意識的に制御しないと学習の再現性が取れないケースがあります。そして現在、次世代アーキテクチャへの移行が進む中で、低精度推論への最適化がさらに加速しています。
古いFP16に依存したコードは、最新環境ではかえってパフォーマンスの低下を招く恐れがあります。新しい環境へ移行する際は、FP8へのコード書き換えや、モデルの重みを圧縮してメモリ消費を抑える量子化技術などを積極的に取り入れる必要があります。世代ごとの仕様変更や非推奨となる機能を常に把握し続けることは、開発チームにとって大きな負担となります。
AIペアプログラミングによる実装ミス削減効果
ここでAIの出番です。最新のAIモデルは、公式ドキュメントや世界中のリポジトリにある膨大な失敗事例と修正パッチを学習しています。
使用しているGPUのアーキテクチャとモデル構造を正確に伝えるプロンプトさえあれば、AIは人間よりも遥かに高い精度で複雑な依存関係を整理し、数値安定性や最新のハードウェア制約を考慮したコードを生成します。廃止された機能の回避や、FP8への安全な移行手順の提案もAIに任せることが可能です。
開発現場で求められるのは、ゼロから手作業でコードを書くことではありません。AIに対して正しい制約条件と目的を与え、より戦略的なモデル設計やビジネス課題の解決に集中することが、プロジェクトを成功に導く鍵となります。
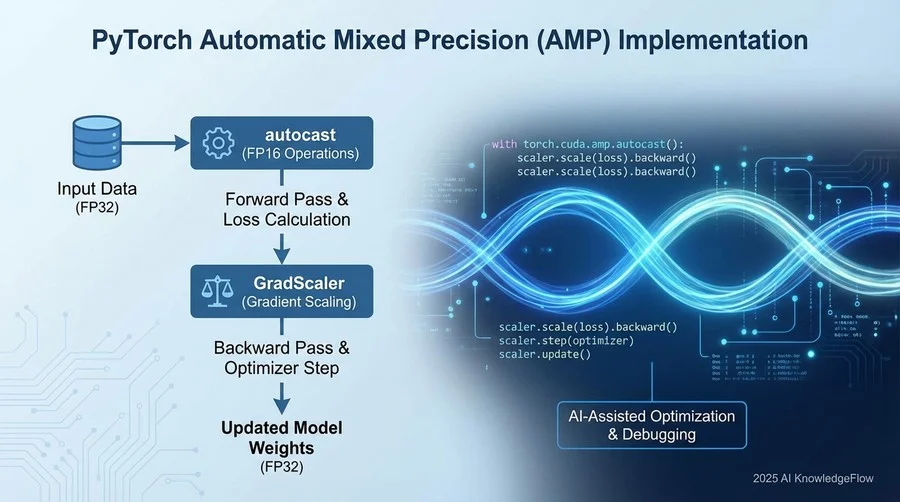
基本プロンプト:安全なAMP実装コードの生成
それでは、実務ですぐに使えるプロンプトを見ていきましょう。まずは、既存の標準的なPyTorch学習ループ(FP32)を、混合精度演算(AMP)対応に書き換えるためのテンプレートです。
このプロンプトの要点は、単に変換を依頼するだけでなく、「GradScalerの配置」と「autocastの適用範囲」について明示的な制約を設けている点にあります。
PyTorch AMP実装プロンプトテンプレート
以下のプロンプトを、既存の学習コード(train.py の主要部分)と一緒にLLM(ChatGPTやClaude 3.5 Sonnet推奨)に入力してください。
## Role
あなたはPyTorchとCUDA最適化の専門家です。
## Task
以下のPyTorch学習ループのコードを、`torch.cuda.amp`を用いた混合精度演算(Mixed Precision)対応にリファクタリングしてください。
## Constraints & Requirements
1. GradScalerの使用: 勾配のスケーリングには必ず `torch.cuda.amp.GradScaler` を使用し、アンダーフローを防止してください。
2. autocastの適用範囲: モデルのforwardパスと損失計算の部分のみを `with torch.autocast(device_type='cuda', dtype=torch.float16):` ブロックで囲ってください。
3. Backwardパスの除外: `loss.backward()` やオプティマイザのステップはautocastの外で行うこと。
4. UnscaleとStep: `scaler.scale(loss).backward()`、`scaler.step(optimizer)`、`scaler.update()` の順序を厳守してください。
5. 勾配クリッピング: 必要に応じて `scaler.unscale_(optimizer)` を実行した後、`torch.nn.utils.clip_grad_norm_` を適用するコードを含めてください。
6. 互換性: PyTorch 1.10以降の推奨記法を使用してください。
## Input Code
```python
{{ここにあなたの学習ループのコードを貼り付けてください}}
### このプロンプトが防ぐ「よくあるミス」
多くのエンジニアが陥りやすいのが、`scaler.step(optimizer)` の前に `optimizer.step()` を呼んでしまったり、勾配クリッピングを行う際に `unscale_` を忘れて、スケーリングされたままの巨大な勾配をクリッピングしてしまうミスです。
上記のプロンプトは、これらの落とし穴をあらかじめ制約条件として塞いでいます。出力されたコードは、基本に忠実なAMP実装となるよう設計されています。
## 環境構築プロンプト:CUDAバージョンの整合性確保
コードが正しくても、動かす環境(CUDA Toolkit、cuDNN、PyTorchのバージョン)が噛み合っていなければ、パフォーマンスが出ないどころかエラーで停止してしまいます。特にDockerコンテナを作成する際、ベースイメージの選定に時間をかけるのは避けたいところです。
### 最適なDockerfile生成プロンプト
使用するGPUと行いたいタスクを伝えるだけで、NVIDIAの公式コンテナ(NGC)をベースにした最適なDockerfileを生成させます。
```markdown
## Role
あなたはAIインフラ構築の専門家(DevOpsエンジニア)です。
## Task
以下のGPU環境と要件に基づいて、PyTorchでの混合精度学習に最適化された `Dockerfile` を作成してください。
## Environment Info
- GPU Model: {{GPU_MODEL}} (例: NVIDIA A100 80GB, RTX 4090)
- Driver Version: {{DRIVER_VERSION}} (例: 535.104.05)
- Host OS: Ubuntu 22.04
## Requirements
1. Base Image: NVIDIA NGC CatalogのPyTorchイメージ (`nvcr.io/nvidia/pytorch`) から、指定したドライババージョンで動作する最新かつ安定したタグを選定してください。
2. Libraries: 以下のライブラリを追加インストールする記述を含めてください。
- {{ADDITIONAL_LIBRARIES}} (例: transformers, datasets, accelerate)
3. Optimization: ビルド時間を短縮し、イメージサイズを抑えるベストプラクティス(キャッシュ削除など)を適用してください。
4. Workdir: 作業ディレクトリを `/workspace` に設定してください。
## Output
- Dockerfileの内容
- なぜそのベースイメージタグを選んだかの解説(CUDAバージョンとの整合性観点から)
このプロンプトのポイントは、「NVIDIA NGCカタログ」を指定している点です。公式の pytorch/pytorch イメージよりも、NVIDIAがチューニングしたNGCイメージの方が、最新のGPU機能への最適化が進んでいることが多いからです。AIに選定させることで、ドライババージョンとの不整合リスクを最小限に抑え、円滑なプロジェクト進行を支援します。
デバッグ・最適化プロンプト:NaN/Infエラーへの対処
機械学習モデルの学習において、Lossが突然 NaN や Inf に発散する現象は、多くの開発チームが直面する深刻な課題です。特に混合精度演算を導入した際、数値のオーバーフローやアンダーフローが原因でこの問題が頻発する傾向があります。
現在、NVIDIA GPU環境などではBFloat16(BF16)が標準的な学習精度として広く採用されています。BF16は従来のFP16と比較してダイナミックレンジが広いため、オーバーフローに対する耐性は大幅に向上しています。しかし、それでも特定のレイヤーや最適化の過程で数値不安定性が発生するリスクはゼロではありません。
エラーログを前にして手探りで原因を探るのではなく、AIのコード解析能力を活用して論理的かつ構造的にデバッグを進めるアプローチが有効です。
NaN発生時の原因特定と修正プロンプト
## Role
あなたはDeep Learningの数値計算安定化の専門家です。
## Task
混合精度演算(Mixed Precision)を用いた学習中にLossが `NaN` になりました。以下の学習ログとモデル構造から、原因を推測し、具体的な修正コードを提案してください。
## Log Snippet
```text
{{ここにNaN発生前後のログを貼り付け}}
Model Architecture Summary
- Model Type: {{MODEL_TYPE}} (例: Transformer, ResNet)
- Optimizer: {{OPTIMIZER}} (例: AdamW)
- Precision: {{PRECISION}} (例: BF16, FP16, FP8)
Analysis Instructions
- 原因分析: 勾配発散時のチェックポイント解析結果をもとに、学習率の設定、Loss Scaling係数の不備、あるいは特定のレイヤー(BatchNormやLayerNormなど)での数値不安定性など、可能性が高い原因を列挙してください。
- 修正案:
- 特定の演算(SoftmaxやLayerNormなど)をFP32に強制するブラックリスト設定(
autocastの無効化など) - Loss Scaling係数の動的調整ロジックの生成
- 勾配クリッピング(Gradient Clipping)の閾値調整案
- AdamWの
epsパラメータの最適化案
これらをすぐに実装できる具体的なコードスニペットとして提示してください。
- 特定の演算(SoftmaxやLayerNormなど)をFP32に強制するブラックリスト設定(
AIモデルは、TransformerのAttention層で生じる巨大な値や、特定の正規化層における演算の不安定性を的確に指摘します。最新のハードウェアアーキテクチャではBF16が基幹精度として定着し、さらにFP8への移行トレンドも見られますが、計算精度を下げるほど局所的なFP32へのフォールバック(ブラックリスト設定)が重要になります。
「特定のレイヤーだけをFP32で計算させる」といった細かな精度制御や、Loss Scalingの動的な調整ロジックを手動で実装するのは手間がかかります。しかし、このプロンプトを活用すれば、環境に合わせた具体的なパッチコードを迅速に生成し、堅牢な学習パイプラインの構築に直結させることが可能です。計算資源を無駄にせず、プロジェクトを予定通りに進めるためにも、AIによる効率的なトラブルシューティングを開発プロセスに組み込むことが推奨されます。
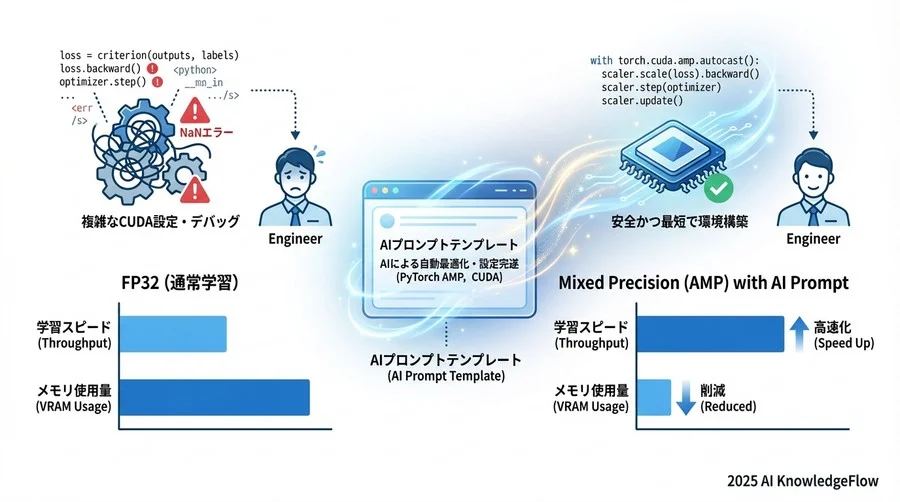
## 検証用プロンプト:パフォーマンス比較ベンチマーク
混合精度演算を導入した後は、その効果をデータで明確に示すことが重要です。「なんとなく速くなった」という感覚的な評価ではなく、「スループットが1.8倍に向上し、メモリ使用量が40%削減された」と具体的な数値で客観的に評価できるようにしましょう。
特に近年は、従来のFP16だけでなく、学習時の安定性に優れたBF16(BFloat16)が標準的な精度として広く利用されています。さらに最新のGPUアーキテクチャではFP8のサポートも強化されており、どの精度を選択するかでパフォーマンスは大きく変動します。
以下のプロンプトは、通常のFP32と、AMP(自動混合精度)を用いた場合のパフォーマンスを比較するベンチマークスクリプトを生成するためのものです。
### ベンチマークスクリプト生成プロンプト
```markdown
## Role
あなたはAIパフォーマンスエンジニアです。
## Task
PyTorchモデルの学習スループット(samples/sec)とメモリ使用量を計測し、FP32(通常)とAMP(FP16またはBF16)の場合で比較するベンチマークスクリプトを作成してください。
## Requirements
1. ダミーデータ: 実際のデータセットを使わず、`torch.randn` などでモデル入力と同じ形状のダミーデータを生成して計測してください。
2. ウォームアップ: 正確な計測のために、計測開始前に数ステップのウォームアップ実行を含めてください。
3. 同期処理: 時間計測の前後には必ず `torch.cuda.synchronize()` を入れて、非同期実行による計測ミスを防いでください。
4. メモリ計測: `torch.cuda.max_memory_allocated()` を使用してピークメモリ使用量を記録してください。
5. 精度の選択: 実行環境のGPUが対応している場合、FP16だけでなくBF16(BFloat16)での計測もオプションとして含めてください。
6. 出力: 結果を表形式(Markdown)で出力するコードにしてください。
## Model Setup Code
```python
{{モデルの定義と入力サイズの情報をここに}}
このプロンプトで生成されるスクリプトを実行することで、ハードウェアの性能をどこまで引き出せているのか、客観的な基礎データを得ることができます。データに基づいた意思決定は、チーム内の知識共有やステークホルダーへの報告において非常に有効です。
## まとめ
混合精度演算は、システム開発やデータ分析のサイクルを加速させる強力な手法です。しかし、その実装にはCUDAのバージョン依存やオーバーフロー対策など、複雑なハードルが存在し、多くの開発チームが環境構築の段階で時間を奪われているという課題は珍しくありません。
今回紹介したプロンプトテンプレートは、そうした複雑な手続きをAIに委ね、効率的にプロジェクトを進めるための戦略的アプローチです。
1. 基本実装: AMPの作法をAIに守らせ、適切な精度(BF16やFP16)を選択する。
2. 環境構築: ハードウェア要件に合ったコンテナ環境をAIに選定させる。
3. デバッグ: NaNやInfといったエラーの原因究明をAIにサポートさせる。
4. 検証: スループットとメモリ使用量の効果測定を自動化する。
開発チームの本質的な価値は、ミドルウェアのバージョン合わせに時間を費やすことではありません。技術的な制約を賢く乗り越え、そのリソースを使ってクライアントの課題を解決し、ビジネス上の成果を生み出すことにあります。
煩雑な設定作業やトラブルシューティングはAIに任せ、より創造的なシステム提案やデータ分析に注力できる環境を整えることをお勧めします。
コメント