はじめに
「APIを叩いてデータを取ってくるだけの簡単なエージェントのはずが、なぜか延々と挨拶を繰り返している」
「ツールの引数が微妙に間違っていて、エラーが起きるとAIがパニックになる」
自社プロダクトにLLMエージェントを組み込もうとしたとき、上記のような「AIの迷走」に悩まされるケースは少なくありません。チャットボットの開発経験がある方ほど、エージェント開発の難易度の高さに驚かれることが多いようです。対話の自然さと業務要件の確実な遂行を両立させるためには、ユーザーの発話パターンを分析し、適切な対話フローを設計する視点が求められます。
単発の質問に答えるだけのチャットボットと違い、自律的にタスクを遂行するエージェントには、「文脈の維持」と「的確なツール選択」という重い負荷がかかり続けます。ここで重要なのは、プロンプトを自然言語の指示書としてではなく、システムの一部(コード)として厳密に設計するという視点転換です。
本記事では、実務の現場で採用されているワークフローに基づき、AIを「迷子」にさせないための設計図を共有します。抽象的な概念論ではなく、タスク分解からエラーハンドリングまで、実用レベルに引き上げるための具体的なエンジニアリング手法を見ていきましょう。
1. 自律型エージェント開発の「壁」とプロンプト設計の役割
まず、開発において直面する課題の本質を整理します。なぜ、LLMエージェントはこれほどまでに制御が難しいのでしょうか。
単発回答型LLMと自律遂行型エージェントの決定的な違い
従来型のRAG(検索拡張生成)チャットボットと、自律型エージェントシステムの最大の違いは「状態遷移(ステートフルネス)」と「推論ループ」の有無にあります。
- 従来型RAG(単発回答型): ユーザーの質問に対し、検索結果(コンテキスト)を元に回答を生成して終了します。基本的に1ターンで完結し、複雑な状態管理を必要としません。
- 自律型エージェント(Agentic RAG含む): ゴール達成のために、自ら計画を立て、ツールを実行し、その結果を見て次の行動を決定します。ナレッジグラフを活用した高度な検索手法(Amazon Bedrock Knowledge Bases等でのサポート拡大が進んでいますが、具体的な対応状況や仕様は各プラットフォームの公式ドキュメントでの確認を推奨します)や、マルチモーダル入力を扱う場合でも、この「判断のループ」が中核となります。
エージェントは、一般的に Thought(思考) → Action(行動) → Observation(観察) というサイクル(ReActパターンなど)を回し続けます。ただし、LangChainやLangGraphなどの最新のフレームワーク環境では、単純なReActループに依存するだけでなく、より細やかな状態管理(StateGraphなど)を用いたグラフベースのワークフロー設計への移行が推奨されるケースが増えています。実装の際は、利用するツールの公式ドキュメントで最新のアーキテクチャを確認し、適切な制御フローへとアップデートすることが確実な動作への近道となります。
このループ構造こそが強力な自律性を生む一方で、一度でも判断を誤ると、その後の工程がすべて破綻するか、無限ループに陥るリスクを孕んでいます。
なぜAIはタスクの途中で迷走するのか
開発現場で頻繁に遭遇する「エージェントの迷走」ですが、最新のLLMを用いたとしても、以下の3点が主な原因として挙げられます。
- ゴール条件の曖昧さ: 「いい感じに予約しておいて」といった曖昧な指示では、AIは終了条件(Exit Condition)を判定できず、不要な確認や検索を繰り返します。対話の自然さを追求しつつも、システムとしての明確なゴール設定が欠かせません。
- コンテキストの汚染と注意の分散: ツール実行結果(JSONや検索ログ)が長大になると、たとえコンテキストウィンドウが広い最新モデルであっても、初期指示(System Prompt)への注意(Attention)が薄れ、本来の目的を見失うことがあります。
- 例外処理の欠如: APIエラーや予期せぬツール出力が返ってきた際、AIがそれを「解決すべき課題」ではなく「単なるテキスト」として処理してしまい、同じ引数でリトライし続けるケースです。業務要件を満たすためには、エラー時のリカバリールートを事前に設計しておく必要があります。
プロンプトを「コード」として扱う設計思想
これらを防ぐためには、プロンプトエンジニアリングを「上手な言い回しを探す作業」から脱却させる必要があります。
プロンプトは、エージェントシステムにおける「自然言語で記述されたプログラムコード」です。変数の型定義、条件分岐(If-Then)、例外処理(Try-Catch)といったプログラミングの概念を、プロンプトというインターフェースを通じて実装する意識が不可欠です。
特に自律型エージェントでは、プロンプト内の指示がシステムの挙動そのものを決定します。次章以降では、この思想に基づき、曖昧さを排除した具体的な開発フローとタスク分解の手法を整理します。対話の自然さと確実な業務遂行を両立させるためのヒントとして、ぜひ参考にしてください。
2. 工程1:タスクの原子化とゴール状態の定義
いきなりプロンプトを書き始めるのは、設計図なしに家を建てるようなものです。まずは、AIに任せる業務プロセスを解剖します。
複雑な業務を「AIが理解できる単位」まで分解する
人間は「会議室を予約しておいて」と言われれば、空き状況を見て、参加者の予定を確認し、適切な部屋を押さえるという一連の流れを無意識に行います。しかし、LLMにとってこれは巨大すぎるタスクです。
タスクを「アトミック(それ以上分割できない最小単位)」に分解しましょう。
- NG: 会議室予約タスク
- OK:
- 参加者スケジュールの取得タスク
- 空き会議室の検索タスク
- 予約登録実行タスク
- 参加者への通知タスク
このように分解することで、各ステップで必要な入力情報と、期待される出力が明確になります。これを「チェイン・オブ・ソート(Chain of Thought)」の事前設計とも呼べます。
入力データと期待される出力形式の厳密な仕様化
各アトミックタスクについて、I/O(Input/Output)を定義します。これはプロンプト内の指示として記述することになります。
例えば「空き会議室の検索タスク」であれば:
- Input: 日時(ISO format)、人数(integer)、設備要件(list[string])
- Output: 候補リスト(JSON format: {room_id, capacity, equipment})
- 終了条件: 候補が1つ以上見つかる、または「空きなし」が確定する
この定義が曖昧だと、AIは「空いている部屋はありますか?」とユーザーに聞き返すという、不要な対話ターンを消費してしまいます。
ワークフローの全体像を可視化する(ステート図の作成)
実務の現場では、Mermaid記法やホワイトボードを使ってステート図(状態遷移図)を描く手法が有効です。「情報不足状態」→「検索実行状態」→「候補提示状態」→「確定状態」といった遷移を可視化し、それぞれの遷移条件(トリガー)を言語化します。
このステート図は、そのままシステムプロンプトの「振る舞い指示」に変換できます。「現在はどのステートにいるか」をAIに認識させることで、迷子になる確率を劇的に下げることができます。
3. 工程2:思考プロセス(Reasoning)のプロンプト実装
タスク分解が完了した後は、AIに対して「考え方」のプロセスを教え込みます。この段階で非常に有効なのが、ReAct(Reasoning + Acting)フレームワークの応用です。
ReAct(Reasoning + Acting)パターンの適用方法
ReActは、AIに実際の行動を起こさせる前に、必ず「思考(Thought)」のプロセスを出力させる設計手法です。単に「指定のAPIを呼べ」と命令するのではなく、「なぜそのタイミングで、そのAPIを呼ぶ必要があるのか」を言語化させます。
以下は、ReActパターンを実装する際の基本的なプロンプト構造の例です。
あなたは自律型アシスタントです。
ユーザーの要望に応えるために、以下のフォーマットを厳守して応答してください。
Question: ユーザーの入力
Thought: 次に何をすべきか、あなたの思考プロセスを記述。
Action: 実行すべきツール名([{tool_names}]から選択)
Action Input: ツールへの入力パラメータ
Observation: ツールの実行結果(システムから挿入される)
...(必要な回数だけThought/Action/Observationを繰り返す)...
Thought: 十分な情報が集まったので、最終回答を作成する。
Final Answer: ユーザーへの最終回答
「思考・計画・行動・観察」のループを指示に組み込む
この明確なフォーマットを強制することで、AIの挙動を追跡し、デバッグの難易度を大幅に下げることができます。万が一、AIが不適切なツールを選択したとしても、直前の Thought を確認すれば、「追加の検索が必要だと判断した」のか、それとも「すでに十分な情報を持っていると勘違いした」のか、エラーの根本原因を即座に特定できます。
ここで特に重要な役割を果たすのが、Few-Shotプロンプティングの併用です。ChatGPTやClaude、Geminiといった主要なLLMにおいて、Few-Shotは現在も出力形式や品質を安定させるための強力な基本テクニックとして推奨されています。
最新のプロンプト設計のトレンドでは、過度に複雑なルールを羅列するよりも、シンプルに「入力A→出力B」のペアを提示する手法が主流です。上記のフォーマット定義に加えて、通常パターンの成功例と、例外的な境界ケースを含む具体例(Shot)を2〜3個提示してください。多すぎる例示はトークンを無駄に消費してしまいますが、厳選した2〜3個の例を組み込むことで、AIは「どの程度の粒度で思考すべきか」や「どのようなトーンで出力すべきか」を効果的に模倣学習し、精度が劇的に向上します。
コンテキストウィンドウを圧迫しない情報の取捨選択
マルチターンでの対話が長く続くと、過去の Observation(APIのレスポンス結果や長文の取得データなど)がコンテキスト内に蓄積され、ウィンドウの上限を圧迫し始めます。これが、AIのハルシネーション(幻覚)や初期の指示を忘れてしまう現象の主な原因です。
この問題への対策として、個々のサブタスクが完了するたびに、過去の思考履歴を要約(Summarize)してコンテキストを圧縮する処理を意図的に挟む設計が求められます。
LangChainなどのLLMアプリケーション開発フレームワークでは、会話履歴を効率的に管理・要約する機能が提供されていますが、実装にあたっては常に最新の公式ドキュメントを参照することが不可欠です。フレームワークのアップデートにより、パッケージ構成の変更や、セキュリティに関する重要な修正が頻繁に行われます。特定の古いクラス名やメソッドに固執するのではなく、最新のアーキテクチャやベストプラクティスに従って、「古くなった詳細な思考ログは破棄し、その後の推論に必要な重要な事実のみを要約して文脈に残す」という堅牢な設計を組み込んでください。これにより、長期的なタスク実行でも迷走しにくい自律型エージェントを実現できます。
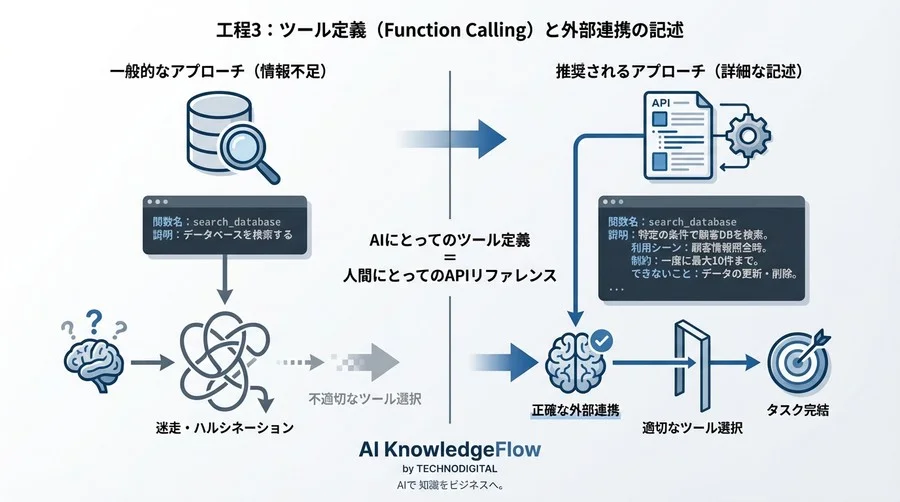
4. 工程3:ツール定義(Function Calling)と外部連携の記述
エージェントの「手足」となるのが、Function Calling(またはTool Use)です。AIが適切なツールを選べるかどうかは、ツールの定義文(Description)の品質にかかっています。
AIに「使える道具」を正しく認識させる記述ルール
多くの開発者が、関数名を search_database とし、説明を データベースを検索する とだけ記述してしまいます。これではAIにとって情報不足です。
AIにとってのツール定義は、人間にとってのAPIリファレンスと同じです。「どのような状況で使うべきか」「何ができないか」まで明記しましょう。
良い記述例:
{
"name": "search_product_stock\
コメント