「データ前処理にプロジェクト期間の8割を費やし、残りの時間でモデルを作ったが精度が出ない」。これは、製造業の現場で痛いほどよく耳にする課題です。
手作業での外れ値除去や、属人的なルールベースのクリーニングに頼っている限り、AIプロジェクトの成功率は頭打ちになります。センサーデータ量は爆発的に増加しており、人間がExcelや従来の可視化ツールを目視して判断する方法には限界が来ています。前処理の工数を定量的に削減し、モデル構築と現場への適用にリソースを集中させることが、生産性向上の鍵となります。
本記事では、「異常検知アルゴリズム実装のためのプロンプトテンプレート」を紹介します。これは、GPT-5.4やClaudeなどの最新AIツールに対し、Pythonによるデータクレンジングコードを生成させるための実践的な指示書です。かつてのGPT-4oなどはすでに引退し、現在の生成AIは単なるコード補完の枠を超えています。データの文脈を深く理解し、最適なアルゴリズムを自律的に選定する強力な推論エンジンへと進化を遂げているのです。
なぜ「異常検知」をAIに委ねるのか
Garbage In, Garbage Out(ゴミが入ればゴミが出る)。この格言は製造業のデータ分析において鉄則ですが、多くの現場では「何がゴミ(ノイズ)で、何が異常の予兆か」の定義すら曖昧なままプロジェクトが進んでいます。熟練のエンジニアであっても、数万行の時系列データから「瞬間的なスパイクノイズ」と「ベアリング摩耗の予兆としての微細な振動」を見分けるのは困難です。
ここで、最新の大規模言語モデルを単なる「コード生成ツール」としてではなく、「統計学とアルゴリズムに精通したデータサイエンティスト」として扱うアプローチを提案します。
例えば、最新のGPT-5.4は100万トークンという膨大なコンテキストを処理できるため、長大なセンサーデータや複雑な仕様書を丸ごと読み込ませることが可能です。適切なコンテキスト(製造プロセスの背景やデータの物理的意味)と制約条件を与えれば、Scikit-learnやPandasを駆使した高度な異常検知パイプラインを提案・構築してくれます。
さらに、ClaudeなどのAIモデルでは、単純な一問一答から「計画を立ててから実行する」というワークフローへの移行が推奨されています。エージェント機能を活用し、タスクを細かく分割しながら進めることで、実装工数を劇的に短縮しつつ、より確実な異常検知モデルを構築できるのです。小さく始めて成果を可視化し、段階的にスケールアップしていく導入戦略において、このアプローチは非常に有効です。
テンプレート活用の4つのPhase
本記事で紹介するテンプレートは、AIから精度の高い回答を引き出すための「役割・目的・制約」を明確化した設計になっており、以下の4つのPhaseで構成されています。最新のAIモデルの特性を最大限に引き出し、データドリブンな改善を進めるため、具体的なワークフローを意識して活用してください。
定義(Definition):
データの分布特性とビジネスルールを言語化し、異常の基準を定めます。ここでは、AIに対して「あなたは品質管理の専門家です」といった役割や出力形式をあらかじめ設定し、会話全体に適用させることが重要です。データの物理的な意味をしっかりと理解させましょう。前処理(Preprocessing):
欠損値の補完やノイズの除去、データの正規化など、異常検知モデルに入力する前のデータ整形を行います。本記事の主題である「データ前処理の9割削減」という定量的な効果を実現するため、AIにデータ構造や要件を提示し、最適な前処理のPythonコードを自動生成させるプロンプトを活用します。実装(Implementation):
統計的手法(3σ法、IQR等)および機械学習モデル(Isolation Forest, Local Outlier Factor等)を用いた検知コードを生成させます。最新のAIモデルは要件に応じて最適なライブラリを選定する能力を持っています。「どのような条件で何を実行するか」というトリガー条件を明確に記述し、ステップバイステップで実装を進めるアプローチが推奨されます。評価(Evaluation):
検知結果を検証し、誤検知(False Positive)を抑制するためのチューニングを行います。AIにコードの解説や改善案を求めましょう。対話的に精度を高めていくプロセス(Human-in-the-loop)を取り入れることで、より堅牢なシステムへと進化し、継続的なカイゼンにつながります。
これらを順に実行することで、属人性を排除した「再現性のあるデータ品質管理」が可能になります。製造現場ですぐに使える具体的なプロンプト設計を通じて、データ前処理の自動化を実現してください。
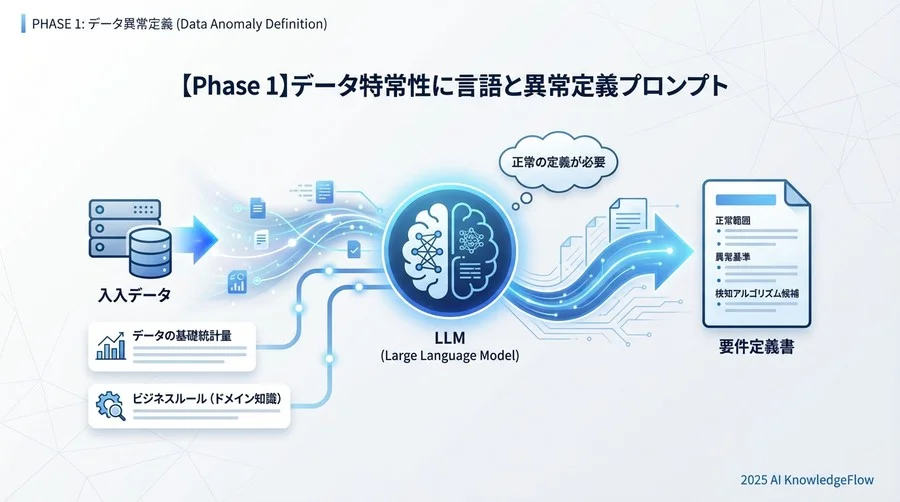
【Phase 1】データ特性の言語化と異常定義プロンプト
異常検知の精度は、アルゴリズムの優劣よりも「ドメイン知識の注入量」で決まります。いきなり「異常検知のコードを書いて」と指示しても、LLMは一般的なコードしか返さない可能性があります。
まずは、手元にあるデータがどのような振る舞いをするものなのか、LLMに理解させる必要があります。以下のプロンプトは、データの基礎統計量とビジネス上の制約を伝え、要件定義書を作成させるためのものです。
テンプレート:データプロファイル記述用
このプロンプトでは、pandas.DataFrame.describe() の出力結果や、カラムの意味を入力として与えます。
## 前提条件
あなたは製造業のデータ分析におけるデータエンジニアです。
以下のデータセット情報に基づき、Pythonで実装すべき「異常検知(外れ値除外)の要件定義」を箇条書きで出力してください。
## 入力データ情報
### データの種類
{{DATA_DOMAIN}}
(例: 工場の射出成形機のセンサーデータ、Webサイトのアクセスログ)
### カラム構成と意味
{{COLUMN_INFO}}
(例:
- timestamp: 計測時刻
- temperature: 金型温度[℃]
- pressure: 射出圧力[MPa]
)
### 基礎統計量 (df.describe()の結果)
{{STATISTICS_SUMMARY}}
### 既知のビジネスルール(ドメイン知識)
{{BUSINESS_RULES}}
(例: 温度が200℃を超えることは物理的にあり得ない。圧力はマイナスにならない。)
## 期待される出力
1. 各カラムにおける「物理的な限界値(絶対異常)」の定義
2. 統計的に疑わしい「外れ値」の定義(分布の歪みを考慮)
3. 時系列的な「急激な変動」の定義
4. 推奨される前処理アプローチ(クリッピング、除外、補間など)
現場での活用ポイント
実務の現場では、このフェーズで「マイナスの流量」が含まれていることが発覚するケースがあります。センサーの配線ミスが原因であっても、これをAIに学習させる前に排除できたことは重要です。LLMは統計量を見て「最小値が-50になっていますが、これは物理的に正しいですか?」と指摘してくれることもあります。対話を通じて、自分たちが気づいていないデータの誤りに気づくことが、データドリブンな改善の第一歩です。
【Phase 2】統計的手法によるベースライン実装プロンプト
高度なAIモデルを使う前に、まずは計算コストの低い統計的手法でノイズを除去し、ベースラインを構築して成果を可視化することが重要です。これをスキップしていきなりDeep Learningに適用するのは、適切ではない場合があります。
ここでは、3σ法(Zスコア)や四分位範囲(IQR)を用いたベースラインの実装を指示します。これらは解釈性が高く、現場のエンジニアにも説明しやすいという利点があります。
テンプレート:基礎的除外ロジック生成用
## 目的
PythonのPandasライブラリを使用して、統計的な外れ値を自動的に検出し、除外またはフラグ付けを行う関数を作成してください。
## 要件
1. 手法:
- 正規分布に近いカラム({{NORMAL_COLUMNS}})には「3σ法(Z-score > 3)」を適用
- 分布が歪んでいるカラム({{SKEWED_COLUMNS}})には「IQR法(1.5 * IQR)」を適用
2. 機能:
- 元のデータフレームを受け取り、異常値を除外したデータフレームと、除外された行数を返すこと。
- どのカラムで異常が検知されたかを確認できるようにすること。
- 処理前後のヒストグラムと箱ひげ図を描画し、削除されたデータが可視化されるコードを含めること。
## 入力変数
- 対象データフレーム変数名: df_sensor
- 正規分布カラムリスト: ['temperature', 'voltage']
- 歪みのあるカラムリスト: ['error_count', 'processing_time']
## 期待される出力
- そのまま実行可能なPythonコードブロック
- コードの解説(特に閾値調整の方法について)
閾値の動的調整機能の実装
生成されたコードを実行し、可視化されたグラフを確認してください。もし正常なデータまで削られているようなら、IQRの係数を1.5から3.0に緩めるなどの調整が必要になる場合があります。このプロンプトで生成される可視化コードは、その判断を定量的にサポートします。
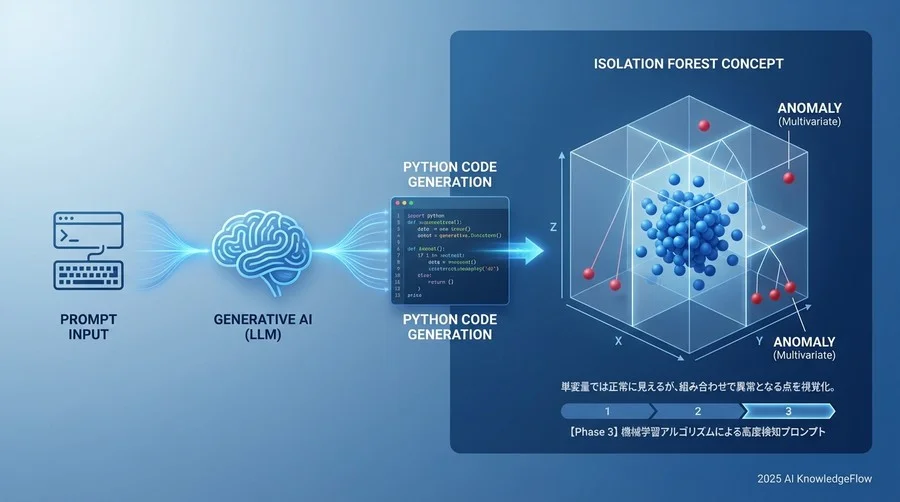
【Phase 3】機械学習アルゴリズムによる高度検知プロンプト
単変量の統計処理では見抜けない異常があります。例えば、「温度は正常範囲、圧力も正常範囲だが、この温度でこの圧力はおかしい」といった多変量間の相関崩れです。これこそが、AI(機械学習)を使うメリットです。
ここでは、教師なし異常検知の代表格である Isolation Forest を実装させます。Scikit-learnを使えば数行で書けますが、パラメータ設定が重要です。
テンプレート:Scikit-learn実装コード生成用
## 目的
Scikit-learnのIsolation Forestを使用して、多変量データの異常検知を行うPythonクラスを実装してください。
## データ特性
- データセットの行数: {{ROW_COUNT}} (例: 100,000行)
- 特徴量数: {{FEATURE_COUNT}} (例: 20カラム)
- 想定される異常混入率: {{CONTAMINATION_RATE}} (例: 0.01 = 1%)
## 実装要件
1. 前処理:
- StandardScalerを用いた標準化をパイプラインに組み込むこと。
2. モデル設定:
- contaminationパラメータは変数として外から調整可能にすること。
- random_stateを固定し、再現性を確保すること。
3. 出力:
- 異常スコア(decision_function)を計算し、ヒストグラムで分布を表示すること。
- 異常と判定されたデータの主要な特徴量における傾向を分析するコード(例: 異常群と正常群の平均値比較)を含めること。
## 期待される出力
- クラス設計されたPythonコード
- Isolation Forestのパラメータ(n_estimators, max_samples)の推奨設定とその根拠
多変量データの相関関係を考慮した検知
このプロンプトのポイントは、contamination(異常混入率)の指定と、結果の解釈コードを含めている点です。Isolation Forestは強力ですが、中身がブラックボックスになりがちです。「なぜ異常と判定されたか」を事後分析するコード(平均値比較など)をセットで作らせることで、現場への説明責任を果たし、納得感のあるカイゼン活動につなげることができます。
【Phase 4】誤検知(False Positive)抑制とチューニング
自動化におけるリスクは、「重要な異常データ(予兆)」をノイズとして捨ててしまうこと、あるいは「正常なレアケース」を異常として弾いてしまうことです。特に後者は、生産ラインを不必要に止めることになりかねず、現場の稼働率低下や信頼の喪失につながる可能性があります。
ここでは、LLMを使って検知結果を「監査」し、パラメータを最適化するループを構築します。
テンプレート:再学習・パラメータ最適化用
このフェーズでは、Phase 3で検知された「異常データ候補」の一部をLLMに提示し、それが本当に異常かどうか、あるいは閾値が厳しすぎないかを問います。
## 目的
Isolation Forestによる異常検知結果の妥当性を評価し、誤検知(False Positive)を減らすための改善案を提示してください。
## 現状の検知結果サンプル
以下は、モデルが「異常」と判定したデータの一部です。
{{DETECTED_ANOMALIES_SAMPLE}}
## 正常データの統計情報
{{NORMAL_DATA_STATS}}
## 依頼事項
1. 上記の異常判定サンプルの中で、ビジネスルール({{BUSINESS_RULES}})に照らして「実は正常である可能性が高いもの」を指摘してください。
2. もし誤検知が多い場合、Isolation Forestのパラメータ(contamination, max_features等)をどのように修正すべきか具体的に提案してください。
3. 特定の条件下(例:装置起動時など)でのみ発生する外れ値を許容するための、事後フィルタリングロジックのコード案を提示してください。
## 期待される出力
- 誤検知の原因分析
- 修正後のパラメータ設定案
- 例外処理を追加したPythonコードスニペット
人間によるレビュープロセスの組み込み
完全に自動化したい気持ちは理解できますが、初期段階では必ずこの「人間とAIによるレビュー」を挟み、小さく検証しながら段階的にスケールアップしていくべきです。このフィードバックループを回すことで、実用的なモデル精度に到達する可能性があります。LLMは、数値の羅列から「これは装置の立ち上がり時の挙動に似ていますね」といった洞察を返してくることがあります。これをルールとしてコードに落とし込む作業が重要です。
導入時の注意点と品質保証チェックリスト
最後に、これらのプロンプトを用いて構築したシステムを運用に乗せる際の注意点を述べます。コードが動くことと、実際の製造現場でビジネス価値を生むことは別問題です。
ブラックボックス化のリスク管理
AIがデータを処理するシステムは、リスクがあります。必ず「除外ログ(Exclusion Log)」を残すこと。いつ、どのデータが、どのロジック(ZスコアなのかIsolation Forestなのか)によって除外されたかを記録し、後からトレーサビリティを確保できるように設計する必要があります。
データドリフトへの対応策
製造現場は常に変化します。季節が変われば温度も湿度も変わります。材料のロットが変わればセンサー値のベースラインも変わります。一度作った異常検知モデルは、時間とともに劣化(データドリフト)する可能性があります。本記事で紹介したプロンプトを使い、定期的にモデルの再評価とパラメータ調整を行い、カイゼンの精神で継続的な改善を推進することを推奨します。
品質保証チェックリスト
導入前に以下の項目をチェックすることをお勧めします。
- 除外されたデータが全データの何%か?(通常は1〜5%程度に収まることが望ましい)
- 既知の過去のトラブル事例(異常データ)を正しく検知できているか?
- 正常な操業データ(ゴールデンバッチ)を誤って異常としていないか?
- 除外理由を現場のオペレーターに定量的な根拠をもって説明できるか?
まとめ
今回紹介したプロンプトテンプレートを使えば、Pythonコードを書く時間を大幅に短縮し、データ前処理の工数を削減することで、生産性向上と品質改善に向けた第一歩を踏み出すことができるでしょう。しかし、これはあくまでツールであり、最終的に「何が異常か」を決めるのは、現場の状況を深く理解し、データドリブンな判断を下すあなた自身です。
コメント