Webアクセシビリティの改善を進める中で、現場のエンジニアから「Lighthouseで診断したらエラーが数百件も出ました。これ、全部手作業で直すんですか…?」という切実な声が上がることは珍しくありません。
真っ赤に染まった診断レポートを見ると、どこから手をつけていいのか途方に暮れてしまうのも無理はありません。特に大規模なサイトや、長期間運用されているレガシーなコードベースでは、アクセシビリティ対応は「終わりのない戦い」のように感じられるケースが多いと言えます。
しかし、ここで少し視点を変える必要があります。
数百件のエラーリストは単なる「作業指示書」ではなく、構造化可能な「データ」として扱うべきです。
もし、この診断結果をプログラムで処理可能なデータセットとして捉え、AI(大規模言語モデル)の力を使って修正コードを生成させることができたら、状況は一変します。
アクセシビリティ診断を「職人芸」や「根性論」で乗り切るのではなく、「データ処理パイプライン」としてエンジニアリングする方法について、具体的なアプローチやデータ構造の観点から解説します。
2. データ処理プロセスによるWebアクセシビリティ改善
アクセシビリティ対応が遅々として進まない最大の要因は、「発見コスト」に対して「修正コスト」が圧倒的に高いことにあります。
「診断して終わり」からの脱却
多くの開発現場で起きているのが、「診断ツールを回してPDFレポートを出力し、それを開発チームに渡す」というフローです。これでは、受け取ったエンジニアは以下のようなプロセスを一件ずつ踏まなければなりません。
- レポートから該当箇所をソースコード内で特定する
- エラーの内容とWCAGの基準を理解する
- 修正方法を調査・検討する
- コードを修正する
- 再度診断して解消されたか確認する
これを数百回繰り返すのは、現実的ではありません。このプロセス自体を自動化・半自動化する仕組みの構築が求められます。
修正コストのボトルネック分析
特に時間がかかるのが「2. 理解」と「3. 修正案の検討」です。
例えば、「コントラスト比が不十分です」というエラーは機械的に修正しやすいですが、「ARIA属性の使用方法が誤っています」といったエラーは、DOM構造や仕様の深い理解が不可欠です。
ここで生成AIの出番となります。最近のLLMは、HTML/CSSの構造理解とWCAGガイドラインの知識を高度なレベルで兼ね備えています。
特に近年のモデル進化は目覚ましく、旧来のGPT-4o等のモデルが廃止されGPT-5.2への移行が進んだことで、長い文脈の理解力や複雑なDOM構造の解析精度が飛躍的に向上しました。また、Claudeにおいては最新のClaude Sonnet 4.6モデルが登場し、100万トークンという膨大なコンテキストウィンドウを処理できるようになっています。これにより、単一のコンポーネントだけでなく、ページ全体の構造や依存関係を踏まえた上で、より正確な修正案を導き出すことが可能です。適切なコンテキスト(文脈)さえ与えれば、彼らは非常に優秀な「修正アシスタント」として機能します。
データパイプラインによる自動化の全体像
構築すべきデータパイプラインのフローは以下の通りです。
- Input: 診断ツール(CLI)からJSONデータを取得
- Process: データをクレンジング・正規化(ノイズ除去)
- Transform: エラー情報と該当コードをプロンプト化し、AIに渡す(※最新のAIモデルが備える推論機能や、タスクの複雑度に応じた思考モードを活用することで、より精度の高い分析を行わせることも有効です)
- Output: AIが生成した修正コードを受け取る
- Verify: 人間または自動テストで検証する
このアプローチにより、エンジニアは「ゼロから修正案を考える」のではなく、「AIが出した修正案をレビューする」という立ち位置にシフトできます。これだけで、心理的ハードルと実工数は劇的に下がります。
2. データソース:診断ツールの生データを取得する
まずは、AIに読み込ませるための「原材料」である診断データを取得します。ブラウザのGUIではなく、CLI(Command Line Interface)やNode.js APIを利用して、生データ(Raw Data)にアクセスします。
Axe-core/LighthouseのJSON出力活用
ここでは、GoogleのLighthouse(内部的にはAxe-coreを利用)をNode.jsから実行し、JSONを取得する例を見てみます。
// lighthouse-runner.js
const lighthouse = require('lighthouse');
const chromeLauncher = require('chrome-launcher');
(async () => {
const chrome = await chromeLauncher.launch({chromeFlags: ['--headless']});
const options = {logLevel: 'info', output: 'json', onlyCategories: ['accessibility'], port: chrome.port};
const runnerResult = await lighthouse('https://example.com', options);
const reportJson = runnerResult.report;
// JSONとして保存、または次の処理へ
console.log('Report is done for', runnerResult.lhr.finalUrl);
console.log('Accessibility score was', runnerResult.lhr.categories.accessibility.score * 100);
await chrome.kill();
})();
このスクリプトを実行すると、非常に巨大なJSONオブジェクトが得られます。AIに必要なのは、この中のごく一部です。
必要なデータフィールドの特定
LighthouseのJSON出力(LHR: Lighthouse Result)の中で、特に重要なのは audits オブジェクト内の各項目です。以下のような構造になっています。
// 診断結果JSONの抜粋例
"audits": {
"image-alt": {
"id": "image-alt",
"title": "Image elements do not have [alt] attributes",
"score": 0,
"details": {
"type": "table",
"items": [
{
"node": {
"type": "node",
"lhId": "page-0-IMG",
"path": "2,HTML,1,BODY,0,MAIN,0,DIV,0,IMG",
"selector": "main > div.hero > img.banner",
"snippet": "<img src=\"banner.jpg\" class=\"banner\">",
"nodeLabel": "img.banner"
}
}
]
}
}
// ...他の監査項目
}
ここでAIに渡すべき必須情報は以下の3点です。
id/title: 何のエラーなのか(例:image-alt)snippet: 問題のあるHTMLコードそのものselector: その要素がどこにあるか(DOM上の位置)
DOM構造の抽出範囲
ここで一つ注意点があります。snippet だけでは情報不足な場合があります。
例えば、input 要素にラベルがないというエラーの場合、その input だけを見ても修正できません。周囲に label 要素があるか、親要素がどうなっているかという「コンテキスト」が必要です。
より高度な修正を目指すなら、Puppeteerなどを併用し、エラー箇所の親要素を含むHTML(Outer HTML)を取得するロジックを追加すると、AIの精度が格段に向上します。
3. データクレンジング:AIに渡す前のノイズ除去
取得した生データをそのままAIに渡すと、トークン(コスト)の無駄遣いになるだけでなく、同じようなエラー修正を何度も繰り返すことになります。前処理(データクレンジング)が重要です。
誤検知(False Positive)のフィルタリング
自動診断ツールは完璧ではありません。明らかに修正不要なものや、サードパーティ製のウィジェット(チャットボットや広告など)起因のエラーは、除外リスト(Allowlist)を作成してフィルタリングします。
// フィルタリング処理のイメージ
const IGNORE_SELECTORS = [
'#chat-widget-container', // 外部ツール
'.ad-banner iframe' // 広告
];
const filteredItems = items.filter(item => {
// 除外セレクタにマッチするものはスキップ
return !IGNORE_SELECTORS.some(selector => item.node.selector.includes(selector));
});
重複エラーの集約(コンポーネント単位の正規化)
例えば、商品リストのページで、20個の商品画像すべてに alt 属性がない場合、エラーは20件報告されます。しかし、修正すべきコード(コンポーネント)は1つである場合がほとんどです。
これを20回AIに修正させるのは非効率です。以下のようなロジックで集約します。
- エラー種別(
id)が同じ - セレクタの構造が類似している(例:
li:nth-child(1)とli:nth-child(2)の違いのみ) - HTMLスニペットの構造が同一
これらをグループ化し、「代表的な1件」のみを修正対象として抽出します。これを「コンポーネント単位の正規化」と呼びます。
修正難易度による分類
エラーには「AIで100%直せるもの」と「人間の判断が必要なもの」があります。
- Low Hanging Fruits(AIが得意):
html-has-lang,image-alt(画像解析AIと組み合わせる場合),color-contrast - Needs Human Review(AIが苦手):
aria-hidden,tabindexの制御, 複雑なインタラクション
プログラム側でエラーIDに基づいてこれらをタグ付けしておくと、後のワークフローを分岐させることができます。
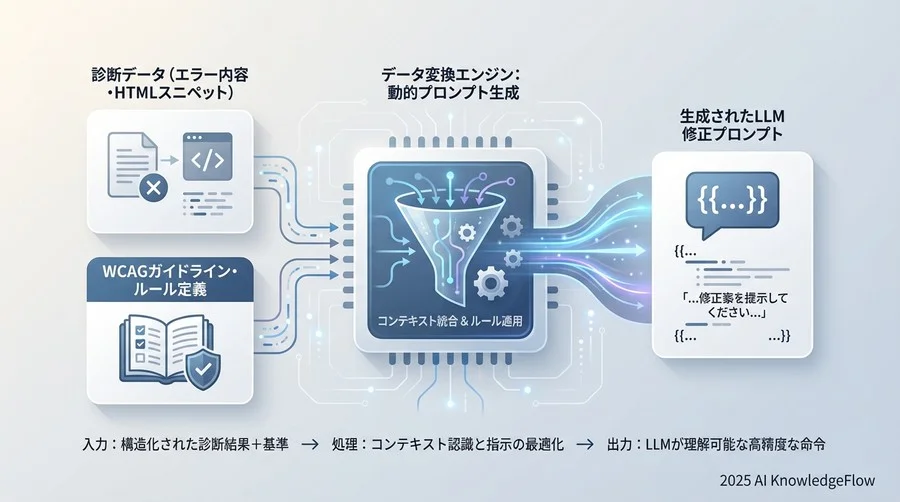
4. データ変換:修正プロンプトの動的生成
クレンジングされたデータを、いよいよLLMへの指示書(プロンプト)に変換する段階に入ります。ここでは、単に「エラーを直して」と指示するだけでは不十分です。UI/UXデザインやアクセシビリティ改善の知見、そしてユーザーが直面する障壁への理解をプロンプトに深く注入することが、質の高い修正案を得るための鍵となります。
診断データとWCAG基準の紐付け
検出されたエラーIDに応じて、参照すべきWCAGの達成基準や、具体的な修正方針をプロンプトに明確に含めます。LLMに対して「なぜその修正が必要なのか」という背景を理解させることで、単なる表面的なコードの書き換えではなく、実際の利用者に寄り添った本質的な改善が期待できます。以下は、プロンプト生成のテンプレート例です。
あなたはWebアクセシビリティの専門家です。
以下のHTMLコードには、Lighthouseによる診断で「{{error_title}}」というエラーが検出されました。
## 対象コード
```html
{{snippet}}
制約条件
- WCAG 2.1 レベルAAに準拠するように修正してください。
- 元のコードの意図や視覚的なデザインを可能な限り維持してください。
- ReactやVueなどのフレームワーク特有の構文ではなく、標準的なHTMLで出力してください(※プロジェクトの環境に合わせて適宜変更してください)。
- 修正したコードのみを出力し、余計な解説は不要です。
修正コード
このように、プログラム内でプレースホルダー(`{{...}}`)を実際の診断データに置換することで、動的かつ精度の高いプロンプトを生成します。
### Few-Shotプロンプトへのデータ埋め込み
より複雑な修正、例えば適切なWAI-ARIA属性の付与やキーボードトラップの解消などが必要な場合は、プロンプト内に「良い修正例」を含めるFew-Shotプロンプティングが極めて有効です。ChatGPTやClaude、Geminiといった主要なLLMにおいて、この手法は現在も標準的なベストプラクティスとして推奨されています。
最近のトレンドとして、長大で複雑な指示文を記述するよりも、2〜3個のシンプルな例示(入力と出力のペア)を提示するアプローチが主流です。多すぎる例示はトークンを消費しすぎるため避けるべきですが、一般的な修正パターンと例外的な境界ケースを少数含めるだけで、AIが文脈やトーンを正確に学習し、出力の形式や品質が劇的に安定します。
```markdown
例:
悪いコード: <div onclick="submit()">送信</div>
良いコード: <button type="button" onclick="submit()">送信</button>
上記の例を参考に、以下のコードを修正してください。
...
このような「入力と出力のペア」の例をエラー種別ごとにライブラリ化して管理しておくことで、自動修正パイプライン全体の品質と安定性が大きく向上します。
出力フォーマットの制御(JSON/Markdown)
AIからの返答を後続のプログラムでスムーズに再利用するために、出力形式をJSONに指定することをお勧めします。プレーンテキストで受け取るよりも、データの取り扱いが格段に容易になります。
{
"original": "<div onclick=\"submit()\">送信</div>",
"fixed": "<button type=\"button\" onclick=\"submit()\">送信</button>",
"reason": "button要素を使用することで、スクリーンリーダーのユーザーに要素の役割が正しく伝わり、キーボード操作も可能になります。"
}
このように構造化して出力させることで、そのままプルリクエストのコメントとして自動投稿したり、修正履歴をCSVレポートとして保存したりする連携作業がスムーズに実現できます。修正の「理由」を含めることで、開発チーム全体のアクセシビリティに対する理解を深める効果も期待できます。
5. パイプライン設計:継続的な改善フローの構築
単発の修正で終わらせないために、開発プロセスの中にこの「自動診断&修正提案」を組み込みます。
CI/CD連携による自動診断
GitHub ActionsなどのCIツールを使い、Pull Requestが作成されたタイミングで診断を実行します。もしアクセシビリティスコアが基準を下回ったり、新たなエラーが検出されたりした場合、自動的にワークフローを回します。
修正案のPull Request自動作成
理想的なフローは以下の通りです。
- 開発者がコードをプッシュ
- CIがアクセシビリティエラーを検知
- AIが修正案を生成
- Botが該当行に修正コードをコメント(または修正PRを自動作成)
これにより、開発者は「指摘される」だけでなく「解決策もセットで提示される」状態になります。これは開発体験(DX)の向上に直結します。
バッチ処理による定期実行
新規開発だけでなく、既存の数千ページあるサイトの改善にもこのパイプラインは有効です。夜間にバッチ処理で主要ページを巡回し、修正案付きのレポートを毎朝Slackに通知する、といった運用も可能です。
6. 品質管理:AI生成コードの検証ルール
最後に、最も重要な「品質管理」について解説します。AIは自信満々に間違ったコードを書くことがあります(いわゆるハルシネーション)。特にアクセシビリティに関しては、「文法的には正しいが、ユーザー体験としては最悪」なコードを生成するリスクが依然として存在します。
AIハルシネーション(存在しないARIA属性等)の検知
よくあるのが、存在しないARIA属性(例: aria-labeledby ※正しくは aria-labelledby)を使ったり、role 属性を不適切に乱用したりするケースです。
GitHub Copilotの最新機能であるCoding Agentなどが、Issueから自動的に修正コードを生成し、Pull Request(PR)まで作成してくれる時代になりました。しかし、AIモデル(ChatGPTやClaude、Geminiなど)の性能が向上しても、アクセシビリティ特有の細かな仕様を誤認することは珍しくありません。
これを防ぐために、AIが生成したコードに対して、HTMLHintやESLintのA11yプラグインを用いた静的解析を必ず実施する「二次検証プロセス」を設けます。GitHub ActionsなどのCIツールでこのチェックを自動化し、エラーが出た場合はマージをブロックする仕組みが不可欠です。
デザイン崩れのリスク評価
HTML構造を変更(例: div → button)すると、CSSが当たらなくなりデザインが崩れることがあります。
これを防ぐため、Visual Regression Testing(視覚的回帰テスト)ツール(BackstopJSやReg-suitなど)と組み合わせ、見た目の変化が許容範囲内かを確認することが理想的です。
人間による最終レビューのポイント
どれだけ自動化しても、最終的な責任は人間が持ちます。また、利用できるAIモデルは頻繁にアップデートされ、古いモデルが廃止されることもあります。使用するモデルが変われば生成されるコードの傾向も変わるため、継続的な注意が必要です。レビュー時には以下の点に注目してください。
- セマンティクス(意味)は正しいか?: AIは文脈を読み違えることがあります。
- 過剰なARIAではないか?: 「No ARIA is better than Bad ARIA(悪いARIAよりARIAなしの方がマシ)」という原則があります。標準のHTML要素で解決できるなら、そちらを優先すべきです。
- 最新のモデルで検証されているか?: AIモデルのライフサイクルは早いため、開発環境の設定が廃止されたモデル(古いバージョンのClaudeやGeminiなど)を指していないか定期的に確認することも、品質維持の隠れたポイントです。
まとめ
Webアクセシビリティ対応を「終わりのない手作業」から「データ駆動型のエンジニアリング」へと変革する手法について解説しました。
診断結果をデータとして扱い、AIという強力なエンジンを組み込むことで、開発チームは膨大なエラーリストに圧倒されることなく、本質的な「ユーザー体験の向上」に注力できるようになります。
今回ご紹介したパイプライン構築は、最初は少し手間がかかるかもしれません。しかし、一度構築してしまえば、それは組織全体の資産となり、開発スピードを落とさずに品質を担保する強力な武器になります。
アクセシビリティは、特別な誰かのためのものではなく、すべてのユーザーのための品質基準です。倫理的な観点からも、誰もが情報にアクセスできる環境を整えることは企業の社会的責任(CSR)の向上にもつながります。AIの力を適切に活用し、より多くの人が快適に利用できるウェブの世界を広げていく一助となれば幸いです。
コメント