導入
「AIに修正させたコードが動かない」「直したと思ったら、別の場所でデグレ(品質低下)が起きていた」
開発現場でGitHub Copilotの新機能やCursorなどのAIツールを導入したものの、こうした声が現場から聞こえてくることはありませんか? 期待して導入したはずの「自律型AIエージェント」が、かえってエンジニアの修正工数を増やしてしまっている——これは、多くのテックリードやマネージャーが直面する「AI導入の壁」です。
ITコンサルタント(AI導入・データ活用支援)の視点から見ると、工場の生産ラインにおける品質管理や異常検知のノウハウは、ソフトウェア開発におけるAI活用の課題解決にも応用できます。実は、AI導入時の課題は、製造現場で新人を教育する際の課題と驚くほど似ているのです。
熟練の職人が「いい感じにやっといて」と言えば通じるのは、受け手に「暗黙知」があるからです。しかし、新人や外部のパートナーに同じ指示を出せば、期待外れの成果物が上がってくるのは当然です。AIエージェントも同じです。彼らは非常に優秀なスキルを持っていますが、プロジェクトの背景や文脈(コンテキスト)については、何も知らない「新人」なのです。
AIによるバグ修正の精度を上げるために必要なのは、プロンプトの小手先のテクニックではありません。情報を構造化して正しく渡す「ロジスティクス」と、上がってきた成果物を評価する「検品基準(品質保証)」の確立です。
本記事では、AIエージェントへの指示出しを属人化させず、チーム全体で品質を担保するための「コンテキストの3層構造」と運用ルールについて、製造業の品質管理(QC)の視点を交えながら紐解いていきます。
なぜAIによるバグ修正は「期待外れ」に終わるのか
AIツールを導入したチームでよく見られるのが、「AIに任せる時間」よりも「AIのミスを修正する時間」の方が長くなってしまうというパラドックスです。なぜ、このような非効率が発生するのでしょうか。
「AI修正のパラドックス」:直してもらう時間が逆にコストになる構造
エンジニアがバグ修正を行う際、無意識のうちに膨大な背景情報を処理しています。「この関数はあそこのモジュールから呼ばれているから、引数を変えると影響が出る」「このライブラリのバージョンは古いから、最新の構文は使えない」といった判断です。
しかし、AIに依頼する際、私たちはつい「このエラーを直して」という短い指示だけで済ませてしまいがちです。AIはその指示に対して、確率的に最もらしいコードを生成しますが、そこにはプロジェクト固有の制約が含まれていません。結果として、「構文としては正しいが、このプロジェクトでは動かないコード」が生成されます。
これを人間がレビューし、修正し、再実行する。この手戻りのループこそが、生産性を下げる要因です。製造業で言えば、図面も渡さずに部品加工を依頼し、出来上がったものが合わないからと何度も作り直させているようなものです。これでは稼働率が低下し、コストが下がるはずがありません。定量的に見ても、手戻りによる工数増加はプロジェクト全体の生産性を10〜20%押し下げる要因になり得ます。
原因はプロンプトではなく「コンテキストの欠落」にある
多くの場合、AIの回答精度が低いと「プロンプト(指示文)が悪い」と考えがちです。しかし、根本的な原因はプロンプトの書き方ではなく、「コンテキスト(文脈情報)の欠落」にあります。
大規模言語モデル(LLM)は、与えられた情報(コンテキストウィンドウ内の情報)のみを頼りに推論を行います。情報が不足していれば、AIはそれを「幻覚(ハルシネーション)」で埋め合わせようとします。つまり、適当な推測で答えを作るのです。
例えば、データベースの接続エラーを修正させる際、使用しているDBの種類やバージョン、ORM(Object-Relational Mapping)の設定ファイルを渡さなければ、AIは一般的な設定を勝手に想定してコードを書きます。これが「期待外れ」の正体です。モデルの頭が悪いのではなく、判断材料が足りていないのです。データドリブンなアプローチにおいては、入力データの質と量が結果を左右します。
自律型エージェントを「新人エンジニア」として扱うマインドセット
AIエージェントを「魔法の杖」ではなく、「超高速でコーディングできるが、プロジェクトのことは何も知らない新人エンジニア」として扱ってみてください。
新人エンジニアにバグ修正を依頼するとき、あなたは何を伝えますか?
- どんなエラーが出ているか(事象)
- どのファイルが関連しているか(環境)
- やってはいけないことは何か(制約)
これらを丁寧に伝えるはずです。AIに対しても全く同じアプローチが必要です。AI活用を成功させているチームは、この「情報伝達のプロセス」を標準化し、誰が指示を出しても必要な情報がAIに渡る仕組みを構築しています。
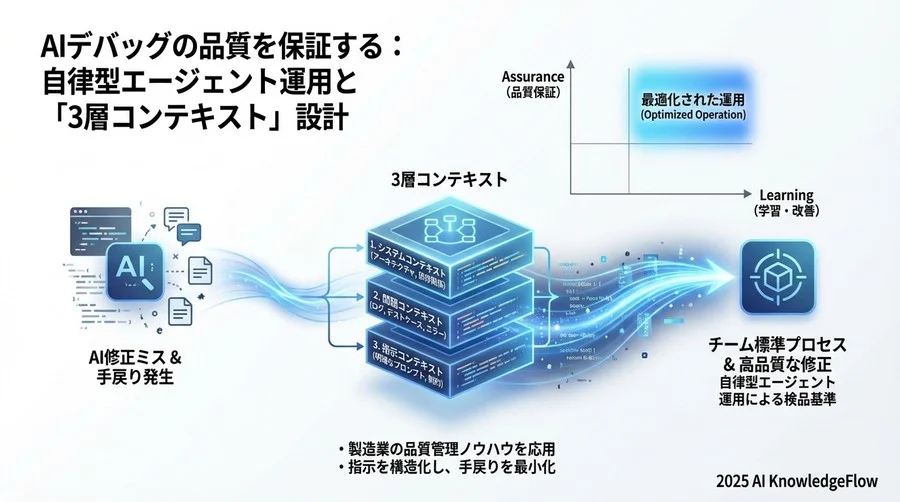
コンテキストの「3層構造」と提供基準の定義
では、具体的にどのような情報を渡せばよいのでしょうか。実務の現場では、バグ修正に必要な情報を「事象」「環境」「制約」の3つのレイヤー(層)に分類して管理することが推奨されます。これを「コンテキストの3層構造」と呼びます。
第1層:事象コンテキスト(What)
これは「何が起きているか」を示す、最も基本的な情報です。多くのエンジニアはこれだけをAIに渡しています。
- エラーログ / スタックトレース: 生のログデータ。要約せずそのまま渡すことが重要です。センサーデータと同様に、生の一次データが最も価値を持ちます。
- 再現手順: どのような操作をしたらエラーが発生したか。
- 期待値: 本来どう動くべきだったか。
ここでのポイントは、「事実」と「推測」を分けることです。「多分ここが悪いと思う」という人間の推測を混ぜると、AIがそれに引きずられて視野狭窄(バイアス)に陥ることがあります。まずは客観的な事実データのみを提供しましょう。
第2層:環境コンテキスト(Where)
バグが発生している「場所」や「状況」に関する情報です。ここが不足すると、環境依存のエラーやバージョンの不整合が発生します。
- 関連ファイル: エラー箇所だけでなく、その関数を呼び出しているファイルや定義ファイル。
- 依存関係:
package.jsonやrequirements.txt、Dockerfileなど。使用しているライブラリのバージョン情報は必須です。 - システム構成: OS、ハードウェアリソース、ネットワーク構成など(インフラ関連のバグの場合)。
特にGitHub Copilotの最新版では、Coding Agent機能やMCP(Model Context Protocol)の統合により、プロジェクト全体の文脈理解能力が飛躍的に向上しています。Issueの内容から関連ファイルを自律的に探索したり、OpenAIやAnthropic、Googleなどの多様な最新モデルを用途に合わせて切り替えて推論させたりすることも可能です。
しかし、AIの自動推論に全てを任せるのではなく、@workspaceコマンドなどを活用して明示的に「このファイルと依存関係を参照して」と指定することで、回答の精度はより確実になります。AIが自律的に動けるようになったからこそ、人間側が「参照すべき環境の範囲」を正しく定義してやることが、誤った修正(ハルシネーション)を防ぐ鍵となります。
第3層:制約コンテキスト(How)
「どのように直すべきか」「やってはいけないことは何か」というルールです。ここが最も見落とされがちですが、コードの品質(保守性や安全性)を担保するためには不可欠です。
- コーディング規約: 変数名の付け方、ディレクトリ構成のルール、使用すべきデザインパターン。
- 禁止事項: 「外部APIへの直接アクセス禁止」「非推奨ライブラリの使用禁止」など。
- パフォーマンス要件: 「レスポンスは100ms以内」「メモリ使用量は〇〇MB以下」など。
製造業で言えば、これは「安全基準」や「仕様書」にあたります。これを与えずに作業させれば、動くけれど危険な機械が出来上がるのと同じで、動くけれどスパゲッティコードやセキュリティホールのあるプログラムが生成されてしまいます。
ノイズの除去:AIを混乱させる「不要な情報」とは
情報は多ければ良いというわけではありません。関係のない大量のファイルをコンテキストに含めると、AIの注意力が散漫になり(これを「Attentionの分散」と呼びます)、重要な情報を見落とす原因になります。
これを「コンテキスト汚染」と呼びます。例えば、バックエンドのバグ修正なのに、フロントエンドの巨大なCSSファイルを読み込ませるような行為です。必要な情報に絞り込む「引き算」の思考も、AIマネジメントには求められます。
バグ修正依頼の標準化:Issueテンプレートとプロンプト設計
コンテキストの3層構造を理解していても、毎回手動で情報を整理して入力するのは手間がかかりますし、担当者によってバラつきが出ます。そこで、チームとして依頼方法を標準化することが重要です。
特に、GitHub Copilotなどの最新の開発支援AIには、Issueやチケットの内容を直接読み込んで自律的にコード修正案を生成する機能が実装されています。これはつまり、Issueテンプレートの品質が、そのままAIエージェントのパフォーマンスに直結する時代になったことを意味します。製造ラインにおける「段取り」の標準化と同様に、AIへの入力も規格化する必要があります。
AIエージェント専用のIssue/チケットテンプレート作成
GitHubやJiraなどのタスク管理ツールで、バグ報告用のテンプレートを作成します。このテンプレート自体を、AIへのプロンプトとしてそのまま流用できる、あるいはAIエージェントが構造化データとして理解しやすい形式にしておくのがコツです。
## バグ修正依頼(AIエージェント用)
### 1. 事象(Facts)
- エラーログ:
(ここにログを貼り付け)
- 再現手順:
1. ...
2. ...
- 期待される動作: ...
### 2. 環境(Context)
- 関連ファイル: `src/api/user.ts`, `src/models/db.ts`
- 実行環境: Node.js (最新LTS), Docker
### 3. 制約(Constraints)
- 必須要件: 既存のAPIレスポンス形式を変更しないこと
- 禁止事項: `any`型の使用禁止
このように項目を埋めるだけで、自然と「3層コンテキスト」が揃うように設計します。最新のAIコーディングツールでは、このIssueをコンテキストとして読み込ませることで、追加の指示なしに精度の高い修正案を得ることが可能になります。
「思考の連鎖(CoT)」を誘発する指示出しのフォーマット
AIにいきなりコードを書かせるのではなく、一度「思考」させるステップを挟むことで、論理的な間違いを減らすことができます。これをChain of Thought(思考の連鎖)と呼びます。
ChatGPTの最新モデルやClaudeの最新版など、近年のAIは「推論(Reasoning)」に特化したモデルやモードが登場し、論理的思考能力が飛躍的に向上しています。これらは内部で複雑な思考プロセスを経て回答を生成しますが、デバッグ業務においては、その「なぜそう判断したか」という思考プロセスがブラックボックスのままでは、人間による検証が困難です。
品質保証の観点からは、AIの内部的な推論能力に頼るだけでなく、あえて明示的に思考プロセスを言語化して出力させる指示を含めることが重要です。プロンプトの最後、あるいはテンプレートの末尾に以下のような一文を加えることを標準ルールにしましょう。
「修正コードを提示する前に、まずエラーの原因をステップバイステップで分析し、なぜその修正が必要なのかを日本語で説明してください。」
これにより、AIは自身の推論プロセスを出力するため、人間が「AIが正しく問題を理解しているか」を判断しやすくなります。もし分析段階で前提が間違っていれば、コードを書かせる前に軌道修正が可能です。これはAI任せにせず、人間が監督者として機能するために不可欠なプロセスです。
再現コード(Minimal Reproduction)の作成ルール
言葉で説明するよりも、「失敗する最小限のコード」を渡すのが最も確実です。これを「Minimal Reproduction」と呼びます。
複雑なプロジェクト全体を渡すのではなく、問題が発生している関数単体を切り出し、入力データを固定して「この入力でエラーになる」という小さなスクリプトを作成します。これをAIに渡し、「このスクリプトが通るように修正して」と依頼すれば、環境要因によるノイズを排除でき、解決率は飛躍的に高まります。
これは製造業における「現物確認」と同じです。言葉で不良品の説明をするより、不良品そのもの(現物)を見せた方が早いのと同じ理屈です。現場での再現性を担保するためにも、この習慣をチームに定着させましょう。
リスクを最小化する「AI修正案」の検品・レビューフロー
AIが修正案を出してきました。さて、これをそのままマージ(統合)して良いでしょうか? 絶対にNGです。AIの成果物は「未検品の部品」です。必ず品質検査(QA)を通す必要があります。
AI特有のミス(幻覚、古いライブラリ使用)を見抜くチェックリスト
人間が書くコードとAIが書くコードでは、ミスの傾向が異なります。AIレビュー専用のチェックリストを用意しましょう。
- 幻覚チェック: 存在しない関数やメソッドを使っていないか?(import文を必ず確認)
- バージョン不整合: プロジェクトで指定しているバージョンでは使えない構文を使っていないか?(AIの知識は学習時点のもので止まっている場合がある)
- セキュリティ: 入力値の検証(バリデーション)を勝手に削除していないか? SQLインジェクションの脆弱性を作り込んでいないか?
- ロジックの単純化: 複雑な条件分岐を勝手に省略していないか?
自動テストによる回帰テスト(Regression Testing)の必須化
AIによる修正を受け入れる絶対条件は、「自動テストが通ること」です。もしテストコードがない場合は、AIに「修正コードと一緒に、その修正が正しいことを証明する単体テストコードも書いて」と指示します。
修正対象のコードとテストコードをセットで生成させ、実際にテストを実行してパスすることを確認します。これにより、AIが「動くつもりで書いたコード」が実際に動くかを機械的に検証できます。これを「ダブルチェック」としてプロセスに組み込みましょう。
人間による最終承認(Human-in-the-loop)の運用ルール
最終的なマージ権限は必ず人間が持ちます。AIエージェントに直接プルリクエストをマージさせる設定は、よほど成熟したテスト環境がない限り避けるべきです。
レビュー担当者は、コードの行単位の正誤だけでなく、「設計として正しいか」「可読性は保たれているか」という高次の視点でチェックを行います。AIは局所最適解(その場のエラーだけ直す)に走りがちなので、全体最適の視点を持つのが人間の役割です。
修正成功率を高める継続的な運用改善サイクル
AI導入は「入れて終わり」ではありません。むしろ、運用しながら育てていくものです。製造ラインが日々「カイゼン」活動を行うように、AI活用のプロセスも継続的に改善していく必要があります。小さく始めて成果を可視化し、段階的にスケールアップするアプローチが有効です。
失敗パターンの分析と「コンテキストライブラリ」への蓄積
AIが修正に失敗したときこそ、最大の学びのチャンスです。「なぜ間違えたのか?」を分析してください。
- 必要なファイルが渡されていなかった?(環境コンテキストの不足)
- 社内独自のルールを知らなかった?(制約コンテキストの不足)
- 指示が曖昧だった?(事象コンテキストの不足)
不足していた情報が特定できたら、それをドキュメント化し、次回のプロンプトやRAG(検索拡張生成)の参照元に追加します。これを繰り返すことで、チーム固有の「コンテキストライブラリ」が充実し、AIはどんどん賢くなっていきます。
チーム内での成功プロンプト共有会(Prompt Review)
週に一度、またはスプリントの振り返り(レトロスペクティブ)の中で、「AIにどう指示したらうまくいったか」「どんな失敗をしたか」を共有する時間を5分でも設けましょう。
「このエラーの時は、あえてスタックトレースだけでなく設定ファイルも渡すと一発で直った」といった現場の知見は、マニュアルには載っていない貴重なノウハウです。これをチーム全体で共有することで、個人のスキル差を埋め、チーム全体のAIリテラシーを底上げできます。
まとめ
AIエージェントによるバグ修正は、単なるツールの導入ではなく、新しい「ワークフローの構築」です。
本記事で解説したポイントを振り返ります。
- コンテキストの3層構造: 事象・環境・制約を整理して渡すことで、AIの推論精度を高める。
- 標準化: テンプレートや再現コードを用いて、誰でも高品質な指示が出せるようにする。
- 品質保証: AIの成果物は「未検品」と捉え、チェックリストとテストで検証する。
- 継続的改善: 失敗を分析し、コンテキストライブラリを強化し続ける。
これらは一見手間に思えるかもしれませんが、一度プロセスとして定着させれば、AIは信頼できる「最強のパートナー」へと進化します。手戻りが減り、エンジニアはより創造的な設計やアーキテクチャの検討に時間を使えるようになります。
まずは、現在抱えているバグ修正タスクの一つで、この「3層構造」を意識した指示出しを試してみてください。AIの回答の質が明らかに変わるのを実感できるはずです。
もし、チーム全体でのAI導入や、より具体的な運用ルールの策定にお悩みであれば、専門家に相談することをおすすめします。実際の開発フローの中で、どのようにコンテキストを管理し、AIエージェントを制御できるのか、具体的なソリューションを検討することが重要です。
コメント