「またAIがもっともらしい嘘をついた」
開発現場で、何度この言葉を聞いたでしょうか。
チャットボットが架空の社内規定を捏造したり、カスタマーサポートAIが存在しない割引キャンペーンを案内したりする。そのたびに現場では「プロンプト」という名のテキストファイルを修正し、「もっと丁寧に」「嘘をつかないで」と、まるで新入社員を諭すように指示を書き換えます。
しかし、はっきり申し上げます。このアプローチには限界があります。
テックリードやプロダクトマネージャーである皆さんが目指すべきは、完璧な「魔法の呪文(プロンプト)」を見つけることではありません。確率的に動作するLLM(大規模言語モデル)を、決定論的な業務システムの一部として機能させるための「制御アーキテクチャ」を構築することです。
AIエンジニアとして対話システムの設計に向き合う実務の現場では、成功するプロジェクトに共通しているのは、プロンプトを「文章」としてではなく、「システムコンポーネント」として扱っている点です。特に金融や小売業界など、厳密な顧客体験の改善が求められる領域では、ユーザーの発話パターンを分析し、適切な対話フローを設計することが不可欠です。
この記事では、属人的な「プロンプト芸」を卒業し、エンジニアリングとして再現性のあるAI制御を実現するための「3層システムプロンプトアーキテクチャ」について解説します。ユーザーテストと改善のサイクルを回し、使われるチャットボットを構築するための設計図を共有しましょう。
なぜ「プロンプトエンジニアリング」だけでは不十分なのか
「プロンプトエンジニアリング」という言葉が流行し、書店には多くの解説本が並んでいます。しかし、業務システムの開発において、単一のプロンプトをひたすら磨き上げることには構造的なリスクが潜んでいます。
確率論的モデルの不確実性とビジネス要件のギャップ
根本的な問題は、LLMが「確率論的(Probabilistic)」なモデルであるのに対し、ビジネス要件の多くは「決定論的(Deterministic)」な結果を求めている点にあります。
LLMは、文脈に基づいて「次に来る確率が最も高い単語(トークン)」を予測し続けているに過ぎません。一方、業務システムでは「在庫があればA、なければBを表示する」といった厳密なロジックが求められます。単に「在庫を正確に答えて」とプロンプトに書くだけでは、99回成功しても、重要な1回で確率の揺らぎにより失敗する可能性があるのです。
このギャップを埋めるためには、プロンプトという「お願い」だけでなく、出力を枠にはめるためのシステム的な「制約」が必要です。
「ドメイン特化」が失敗する典型的なパターン
自社データに特化したAIを作ろうとして陥りがちなのが、「巨大モノリシックプロンプト」の罠です。
- 製品マニュアルの全テキスト
- 過去のFAQリスト
- 禁止用語集
- 口調の指定
- 例外処理のルール
これら全てを一つのシステムプロンプト(System Message)に詰め込むとどうなるでしょうか。コンテキストウィンドウ(入力可能なトークン数)の制限に引っかかるだけでなく、モデルの「Attention(注意機構)」が分散してしまいます。
特に、「Lost in the Middle」と呼ばれる現象が知られています。これは、長大なプロンプトの中間部分にある指示が、最初や最後の指示に比べて無視されやすいという特性です。重要な禁止事項をプロンプトの中ほどに書いておいたせいで、本番環境であっさり破られるという事故は、まさにこれが原因です。
システム設計としてのプロンプト管理への転換
必要なのは、プロンプトを静的な「テキスト」として扱うのではなく、動的に生成・制御される「プログラム」として扱う視点の転換です。
状況に応じて必要な情報だけを注入し、不要なノイズを排除する。出力形式を厳密に定義し、ルール違反があればシステム側で検知して弾く。このように、LLMの前工程(入力処理)と後工程(出力処理)を含めたパイプライン全体で品質を担保するアプローチこそが、業務レベルのAI開発には不可欠です。
グラウンディングの核心:AIを現実に繋ぎ止めるメカニズム
AIに嘘をつかせないための最重要概念が「グラウンディング(Grounding)」です。直訳すれば「接地」。AIという浮遊しがちな知性を、事実という地面に繋ぎ止める技術です。
グラウンディング(Grounding)の定義と重要性
LLMにおけるグラウンディングとは、モデルが生成する回答の根拠を、学習済みの内部知識(Parametric Memory)ではなく、外部から提供されたコンテキスト(Non-Parametric Memory)に求めるように制御することを指します。
例えば、ChatGPTのような最新のLLMであっても、学習しているのは特定のカットオフ時点までの情報に限られます。当然ながら、自社の「今朝変更された就業規則」は知りません。もしAIが「一般的な就業規則」に基づいて回答してしまえば、それはもっともらしい嘘、すなわちハルシネーション(幻覚)となります。
知識の「想起」と「参照」の違い
人間で例えるなら、「暗記している知識で答える(想起)」のと、「目の前の教科書を見ながら答える(参照)」の違いです。
業務利用において、AIに「想起」させてはいけません。AIの記憶は曖昧で、細部が混ざり合うことがあります。常に「参照」させる設計が必要です。
- 想起(NG): 「当社の返品ポリシーについて教えて」→ AIが学習データ内の一般的なECサイトの知識を混ぜて回答。
- 参照(OK): 「(検索システムが取得した最新の返品規定テキストを提示し)この情報に基づいて、返品ポリシーを教えて」→ AIは提示されたテキストを要約・整形して回答。
ハルシネーションを抑制する情報のアンカー
グラウンディングを成功させるためには、プロンプト内で「情報源」を明確に区別する必要があります。「以下の情報は事実として扱ってください」という強い指示とともに外部データを与え、それをアンカー(錨)として回答生成の範囲を限定させるのです。
これは単なるRAG(Retrieval-Augmented Generation)の実装の話だけではありません。プロンプトの中で、どこからどこまでが「事実(Context)」で、どこからが「指示(Instruction)」なのかを、モデルが誤解しようのない形式で構造化して渡す技術が求められます。
提案:ドメイン特化型システムプロンプトの「3層アーキテクチャ」
ここからが実践編です。対話の自然さと業務要件のバランスを保ちつつ、メンテナンス性を維持するために、システムプロンプトを3つのレイヤーに分割して管理するアプローチが有効です。
第1層:役割定義(Persona & Mission Layer)
「あなたは誰で、何のために存在するのか」
最も基礎となる層です。ここではAIのペルソナと、大局的な目的を定義します。この層は基本的に静的(Static)で、頻繁に変更されることはありません。
- 内容: 名前、職務(例:シニアテクニカルサポート)、専門領域、ターゲットユーザー。
- 目的: 回答の視座を固定する。例えば「初心者向けに優しく」なのか「専門家向けに簡潔に」なのか、ここでの定義が全ての回答のベースラインになります。
第2層:制約と境界(Constraint & Boundary Layer)
「やってはいけないこと、守るべきルール」
ビジネスロジックに直結する層です。出力フォーマットの指定や、倫理的なガードレール、回答不可時の振る舞いなどを記述します。この層は、サービスの仕様変更に合わせて調整される準静的な部分です。
- 内容:
- 出力形式(JSON, Markdownなど)
- 禁止事項(競合他社の言及禁止、投資助言の禁止など)
- トーン&マナー(「です・ます」調、絵文字の使用可否)
- フォールバック(答えられない場合の定型句)
- 目的: AIの創造性を制限し、システムとして扱いやすい出力を保証する。
第3層:動的コンテキスト(Dynamic Context Layer)
「今、何について答えるべきか」
ユーザーの質問ごとに動的に生成される層です。RAGで検索したドキュメント、直前の会話履歴、ユーザーの属性情報などがここに入ります。
- 内容:
- Retrieved Documents(検索された関連知識)
- Conversation History(会話ログ)
- User Profile(ユーザー名、契約プランなど)
- User Query(現在の質問)
- 目的: グラウンディングを実現し、パーソナライズされた回答を生成する。
この3層をプログラムコードのようにテンプレート化し、実行時に結合して最終的なプロンプトを生成します。これにより、「役割を変えずに検索ロジックだけ変える」といったA/Bテストも容易になります。
詳細設計1:コンテキスト注入とRAG連携の設計パターン
第3層にあたる「動的コンテキスト」の実装詳細について、エンジニア視点で深掘りします。RAGシステムが検索してきたテキストを、ただ漫然とプロンプトに貼り付けるだけでは、期待する精度は出せません。
関連情報の取得とフィルタリング戦略
検索システム(Vector DBなど)から取得したドキュメントチャンク(情報の断片)には、どうしてもノイズが含まれます。関連度の低い情報をプロンプトに含めると、AIが混乱し、ハルシネーション(もっともらしい嘘)の原因になります。
ここで重要なのが、Reranking(再順位付け)というプロセスです。検索で広めに上位10〜20件を取得した後、より高精度なモデル(Cross-Encoderなど)を使って関連度を厳密に再評価し、本当に重要なトップ3〜5件だけをプロンプトに渡します。これにより、コンテキストウィンドウを節約しつつ、回答の精度を大幅に向上させることができます。
プロンプトへのコンテキスト埋め込み形式
LLMにとって「ユーザーへの指示(System Prompt)」と「参照すべきデータ(Context)」の境界線を明確にすることは極めて重要です。これを曖昧にすると、データ内の文章を指示と勘違いするリスクも高まります。
この境界を明確にするために、XMLタグのような構造化マーカーを活用するのがベストプラクティスです。
# Context
以下の `<documents>` タグ内の情報を唯一の事実として回答を作成してください。外部知識を使用してはいけません。
<documents>
<doc id="1" title="返品規定">
商品到着後7日以内であれば、未開封に限り返品可能です。
</doc>
<doc id="2" title="送料について">
返品時の送料はお客様負担となります。
</doc>
</documents>
このように明示的な区切り文字(Delimiter)を使うことで、AIは「どこからどこまでが参照データか」を正確に認識できます。特にClaudeの最新モデルを含む多くの高性能LLMでは、XMLタグを用いた構造化データの認識能力が高く調整されており、この手法は非常に有効です。
情報の鮮度と優先順位の制御
複数のドキュメントで情報が矛盾している場合(例:古いマニュアルと新しいマニュアルが混在している場合)、AIはどう判断すべきでしょうか?
プロンプト内で優先順位の判断ロジックを明示的に記述します。
「複数の情報源に矛盾がある場合は、メタデータの
dateが新しい情報を優先してください。日付が不明な場合は、doc_type="official_rule"の情報を優先してください」
このように、本文だけでなくメタデータ(日付やカテゴリ)もセットでプロンプトに注入し、判断基準を言語化して伝えることで、人間のような柔軟な判断ロジックをシミュレートさせることが可能です。
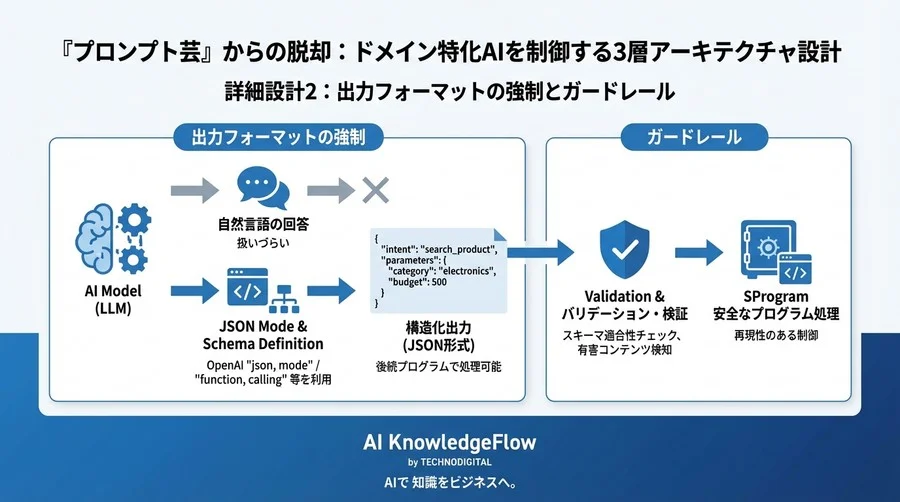
詳細設計2:出力フォーマットの強制とガードレール
第2層「制約」における重要テクニックです。AIの出力を後続のプログラムで処理したい場合、自然言語の回答は扱いづらいものです。
JSONモードとスキーマ定義による構造化出力
OpenAIの「JSON Mode」や「Function Calling」、あるいは各モデルの出力強制機能を利用し、回答をJSON形式に固定します。
例えば、ユーザーの質問から「意図」と「パラメータ」を抽出する場合:
// 期待する出力スキーマ
{
"intent": "search_product\
コメント