「AIチャットボットを導入したが、嘘をつくので公開できない」
最近、製造業のDX推進の現場では、このような課題が頻繁に議論されています。社内の膨大なPDFマニュアルや技術仕様書をRAG(検索拡張生成)システムに投入し、PoC(概念実証)までは進む。しかし、いざ精度検証を行うと、存在しない型番を答えたり、危険な操作手順を案内したりする――いわゆる「ハルシネーション(幻覚)」の問題に直面することがあります。
経営層はAIに期待し、現場は正確性を要求する。その板挟みでプロジェクトが頓挫するケースは少なくありません。
もし、人命や高額な設備に関わる領域で、AIに「リアルタイムで」回答を生成させようとしているなら、そのアーキテクチャは一度見直すべきでしょう。現在のLLM(大規模言語モデル)において、ハルシネーションを完全に防ぐことは極めて困難です。
では、AIは使えないのでしょうか? いいえ、使い方が重要です。技術の本質を見抜き、ビジネスへの最短距離を描くことが求められます。
推奨するのは、AIを「接客係(チャットボット)」としてではなく、「編集者(データ作成者)」として活用するアプローチです。つまり、マニュアルからAIを使って事前にFAQ(質問と回答のペア)を一括生成し、それを人間がレビューして「静的なデータベース」として検索システムに投入するのです。
これなら、誤情報は公開前にフィルタリングできます。既存の検索システムやFAQツールもそのまま活かせます。まずは動くプロトタイプを作り、仮説を即座に形にして検証してみましょう。
本記事では、この「静的FAQ生成(Synthetic Data Generation)」パイプラインの構築方法を、具体的なPythonコードやプロンプト設計と共に解説します。確実に動くシステムを、スピーディーに作り上げましょう。
1. なぜ「対話型ボット」ではなく「FAQ一括生成」なのか
一般的な傾向として、生成AI活用において最初にRAG(検索拡張生成)ベースのチャットボット導入を目指すケースが多いですが、これは決して容易な道のりではありません。AIエージェント開発・研究者の視点から、なぜあえて「FAQ一括生成」というアプローチを推奨するのか、経営者視点とエンジニア視点を融合させて整理してみましょう。
リアルタイム生成(RAG)のリスクと運用コスト
RAGシステムは、ユーザーの質問に対して関連ドキュメントを検索し、それをコンテキストとしてLLMに回答を生成させます。このプロセスは動的であり、同じ質問でもタイミングやモデルのバージョンによって回答が変わる「非決定論的」な性質を持っています。
製造業や金融、医療といったミッションクリティカルな領域において、この「揺らぎ」は看過できないリスクとなります。「95%の精度」と言えば聞こえはいいですが、残りの5%で重大な事故やコンプライアンス違反につながる誤情報を出力する可能性があるシステムを、チェックなしで顧客向けに公開できるでしょうか?
さらに、運用コストの観点も重要です。RAGの場合、以下のコストが継続的に発生します。
- 推論コスト: ユーザーが質問するたびに高性能なLLMのトークン消費が発生します。
- LLMOps(運用基盤)の維持: 回答の「正確性(Faithfulness)」や「関連性(Relevance)」を監視し続けるための評価パイプラインが必要です。最新の評価フレームワークを導入し、継続的に精度をモニタリングする体制構築には、高度なエンジニアリングリソースが求められます。
Human-in-the-loop(人間による確認)を前提としたワークフロー
一方、「FAQ一括生成」のアプローチはバッチ処理です。夜間にAIを稼働させてマニュアルから大量のQ&Aペアを作成し、それをCSVやJSONとして出力します。
ここでの最大の利点は、「公開前に人間が介入できる(Human-in-the-loop)」という点です。生成されたQ&Aリストをエンジニアやドメインエキスパートが事前にチェックし、誤りや不適切な表現を修正・削除できます。
このプロセスを経ることで、検証済みの「確定情報」だけが本番環境(FAQ検索システム)に登録されます。これにより、本番稼働中のハルシネーション(もっともらしい嘘)リスクを物理的にゼロに近づけることが可能です。
既存のFAQシステム(Zendesk/Salesforce等)資産の有効活用
実務の現場では、すでにZendesk、Salesforce Service Cloud、あるいは自社開発のFAQ検索システムが運用されているケースが多々あります。RAGチャットボットを導入する場合、これらとは別のUI/UXを構築し、ユーザーに新しいインターフェースへの適応を強いることになります。
しかし、AIで生成したデータを既存システムのインポート形式に合わせて出力すれば、大規模なシステム改修は不要です。検索アルゴリズムも、長年チューニングされた既存の技術(キーワード検索やハイブリッド検索)をそのまま活用できるため、動作も高速で安定的です。
「最新のAI技術を入れること」自体を目的にせず、「サポートコスト削減と顧客満足度向上」というビジネスの最短距離を描く目的に立ち返れば、この堅実なアプローチこそが極めて合理的と言えるでしょう。
2. アーキテクチャ設計:PDFから構造化データへ
マニュアルという「非構造化データ」を、FAQという「構造化データ」に変換するパイプラインの設計方針を定義します。ここでは、単にテキストを抽出して並べるのではなく、文書の文脈や意図をシステムに理解させるための変換プロセスが求められます。
非構造化データ(マニュアル)の解析課題
取扱説明書や製品仕様書(PDF)は、AIモデルにとって非常に読み取りづらいデータの代表格といえます。
- 多段組みレイアウト: 人間の目には読みやすくデザインされていても、単純なテキスト抽出ツールを通すと行の順序が崩壊し、文章の意味が通らなくなるケースが多発します。
- 図表とキャプション: 重要な仕様数値が表(テーブル)の中に埋もれていたり、図解の中に小さな注釈として記載されていたりするため、テキスト情報だけを追うと致命的な情報の欠落を招きます。
- ヘッダー・フッター: 全ページに共通して印字される「会社名」や「機密保持」などの定型文言は、FAQを生成する際のノイズとして働きます。
これらの生データをそのままLLM(大規模言語モデル)に投入すると、ノイズを過剰に拾い上げ、結果として質の低いQ&Aが生成されてしまいます。生成の前段階における「前処理」こそが、システム全体の精度を左右する鍵を握っています。
処理パイプラインの全体像
信頼性の高いFAQを生成するための標準的なパイプラインは、以下のステップで構成されます。
- Ingestion (取り込み): PDFファイルを読み込み、元のレイアウト情報を保持したまま、テキスト、タイトル、表、画像などの各要素に分解します。
- Cleaning (浄化): ヘッダーやフッターの削除、ページ番号の除外、OCR特有の無意味な記号の排除を行い、データをクリーンアップします。
- Chunking (分割): トピック単位やセクション単位など、意味的なまとまり(チャンク)ごとにデータを適切に分割します。
- Generation (生成): 分割された各チャンクを入力データとして、LLMにQ&Aペアを生成させます。
- Evaluation (評価): 生成されたQ&Aを別の評価用LLMで検証し、事実誤認や低品質な回答を自動的にフィルタリングします。
- Export (出力): 最終的な人間によるレビュー工程を経て、システムにインポート可能なCSVやJSON形式で出力します。
使用する技術スタック(LangChain, Unstructured, OpenAI API)
この高度なパイプラインを実装するためには、適切な技術スタックの選定が不可欠です。AIモデルの進化は非常に速いため、常に最先端の技術スタックをアップデートし、世代交代に即座に対応できるアーキテクチャを組むことが重要です。
LangChain:
LLMアプリケーション構築におけるデファクトスタンダードのフレームワークです。セキュリティパッチが適用された最新バージョン(langchain-core等)の利用を強く推奨します。過去のバージョンには深刻な脆弱性が報告されているケースがあるため、本番環境では必ず最新の安定版を採用し、各種LLM APIとの安全な統合を図ってください。Unstructured.io:
複雑なPDF解析に特化したライブラリです。高度なレイアウト解析能力を備え、仕様書などに含まれる難解な表データの抽出において高い精度を発揮します。OpenAI API (GPT-5.2) / Google Gemini API:
推論エンジンとしてパイプラインの中核を担います。かつて主流だったモデルは急速にレガシー化しているため、最新モデルへの移行を前提とした設計が求められます。- GPT-5.2への移行:
OpenAIの公式情報によると、2026年2月13日にGPT-4oやGPT-5.1などの旧モデルはChatGPTのUIから引退し、デフォルトモデルはGPT-5.2ファミリーに一本化されました。API経由では一部旧モデルの利用も継続可能ですが、新規のパイプライン開発においては、回答の正確性やコンテキスト理解が大幅に向上したGPT-5.2への移行を推奨します。GPT-5.2はInstant、Thinking、Auto、Proの4つのモードを備えており、タスクに応じた柔軟な使い分けが可能です。 - 推論強化機能(Thinkingモード等):
複雑なロジックを含む仕様書の解析には、GPT-5.2のThinkingモードのような深い推論プロセスを持つモデルが不可欠です。これにより、表面的なテキストの切り貼りではなく、論理的な整合性を保った高度なFAQ生成が実現します。 - Google Gemini 3.1 Pro:
Googleのエコシステムを活用する場合、2026年2月19日にリリースされたGemini 3.1 Proが強力な選択肢となります。以前のGemini 1.5 ProやGemini 3 Proと比較して推論性能が2倍以上に向上しており、複雑な問題解決や視覚データの統合に特化しています。大量のドキュメントを処理するバッチ処理において、高いコストパフォーマンスと圧倒的な精度を提供します。
- GPT-5.2への移行:
Pydantic:
出力データの厳格なバリデーションツールです。LLMに指定したJSONスキーマ通りの形式で出力させ、後続のシステム(データベースや検索エンジン)で確実に処理できるようにするために組み込みます。
3. 実装ステップ1:ドキュメントローダーと前処理の実装
それでは、具体的な実装に入りましょう。まずはPDFからテキストと表データを抽出する部分です。ここは重要な作業であり、疎かにすると後の工程に影響が出ます。理論だけでなく「実際にどう動くか」を重視し、コードを動かしながら確認していくのが一番です。
PythonによるPDF解析ライブラリの選定と実装
Pythonには PyPDF2 や pdfminer など多くのPDFライブラリがありますが、マニュアルの解析には unstructured が適しています。レイアウト解析を行い、それが「タイトル」なのか「本文」なのか「表」なのかを識別してくれるからです。
以下は、unstructured を用いてPDFを要素ごとに分解する基本的なコード例です。
from unstructured.partition.pdf import partition_pdf
# PDFファイルのパス
filename = "manual_v1.0.pdf"
# PDFを要素に分割(高解像度モデルを使用)
elements = partition_pdf(
filename=filename,
strategy="hi_res\ 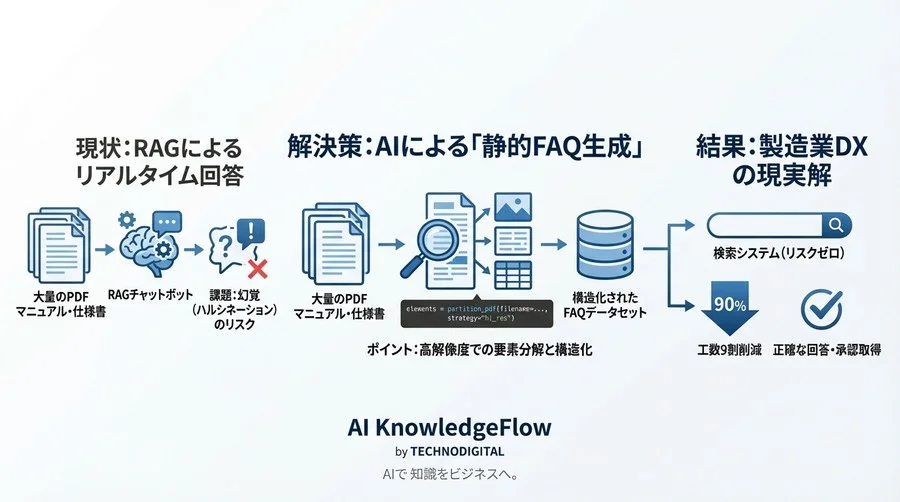
",
infer_bounding_boxes=True,
extract_images_in_pdf=False,
)
# 抽出した要素からテキストと表を抽出
extracted_texts = []
for el in elements:
if el.category in ["Title", "NarrativeText", "Table"]:
extracted_texts.append(str(el))
# 扱いやすいようにテキストを結合
document_text = "\n".join(extracted_texts)
print(f"抽出完了: {len(document_text)}文字")
このコードにより、PDF内のレイアウトを保持したまま、タイトル、本文、表データだけをクリーンに抽出できます。ヘッダーやフッターといったノイズになりやすい要素(Header, Footer)は自動的に除外されるため、後続のLLMによる処理精度が劇的に向上します。
セマンティックチャンキング(意味的分割)の導入
抽出した長文テキストをそのままLLMに渡すと、コンテキストウィンドウの制限や、情報過多による精度低下(Lost in the Middle現象)を引き起こします。そのため、適切なサイズに分割する「チャンキング」が必要です。
単に文字数で区切るのではなく、見出しや段落の区切りなど、意味のまとまりを維持したセマンティックチャンキングを行うことが、高品質なFAQ生成の鍵となります。LangChainの RecursiveCharacterTextSplitter などを使用し、見出しタグや改行コードを基準に分割する設定を行いましょう。
4. 実装ステップ2:プロンプトエンジニアリングとFAQ一括生成
テキストが準備できたら、いよいよLLMにFAQを生成させます。ここで重要なのは、LLMに「どのようなFAQを作ってほしいか」を明確に指示し、出力形式を厳密に定義することです。GitHub Copilotなどのツールも駆使し、仮説を即座に形にして検証を繰り返すアプローチが有効です。
Pydanticを用いた構造化出力の強制
JSON形式で出力させる場合、プロンプトだけで指示するとキー名がブレたり、不要なテキストが混ざったりすることがあります。PydanticモデルとLangChainの StructuredOutputParser(または各LLMプロバイダーのStructured Outputs機能)を組み合わせることで、堅牢なパイプラインを構築します。
from pydantic import BaseModel, Field
from typing import List
class FAQ(BaseModel):
question: str = Field(description="ユーザーが検索しそうな自然な疑問文")
answer: str = Field(description="マニュアルの記述に基づいた正確で簡潔な回答")
reference: str = Field(description="回答の根拠となるマニュアル内のセクションやページ番号")
class FAQList(BaseModel):
faqs: List[FAQ] = Field(description="生成されたFAQのリスト")
生成プロンプトの設計
製造業のドキュメント向けには、以下のようなプロンプトが効果的です。役割(Role)、タスク(Task)、制約条件(Constraints)を明確に分離します。
from langchain_core.prompts import ChatPromptTemplate
system_prompt = """あなたは製造業の熟練したテクニカルライターです。
提供されたマニュアルの一部から、現場の作業員や顧客が直面しそうなトラブルシューティングや仕様に関するFAQ(質問と回答のペア)を作成してください。
【制約条件】
- 提供されたテキストの情報のみを使用し、外部の知識や推測を含めないこと(ハルシネーションの防止)。
- 質問は「〜が動かない」「〜の寸法は?」など、実践的な表現にすること。
- テキスト内にFAQとして抽出できる情報がない場合は、空のリストを返すこと。
- 指定されたJSONスキーマに厳密に従って出力すること。
"""
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "以下のテキストからFAQを生成してください:\n\n{text}")
])
このプロンプトとチャンク化されたテキストを最新のLLMに渡し、バッチ処理で一気にFAQリストを生成させます。
5. 実装ステップ3:生成データの自動評価(LLM-as-a-Judge)
生成が終わったからといって、そのまま人間にレビューを回すのは非効率です。数千件のQ&Aペアを一つずつ確認するのは多大な労力がかかります。そこで、別のLLM(あるいは同じLLMの別プロンプト)を用いて、生成されたFAQの品質を自動評価(スコアリング)するステップを挟みます。
評価の観点は主に以下の2点です。
- 正確性(Faithfulness): 回答が元のドキュメントの内容に完全に裏付けられているか。
- 有用性(Usefulness): 質問が実際の業務において意味のある内容か。
スコアが一定基準を下回るFAQは自動的に破棄するか、「要確認フラグ」を立てて出力します。これにより、人間のレビューアーは「AIが自信を持って生成した高品質なFAQ」の最終確認と、「グレーゾーンのFAQ」の修正にのみ集中でき、作業コストを大幅に削減できます。
6. まとめ:AIを「運用可能な形」で現場に届ける
「AIが嘘をつく」という課題に対して、RAGの精度向上アルゴリズムを延々とチューニングし続けるのは、多くの場合、ビジネスの要求スピードに合いません。特に正確性が絶対視される領域では、技術的な理想を追うよりも、実務の運用プロセスでリスクをコントロールする設計が求められます。
本記事で解説した「静的FAQ生成」アプローチは、LLMの強力なテキスト理解・生成能力を活かしつつ、出力の非決定論的リスクを「Human-in-the-loop(人間の介在)」と「静的データベース化」によって完全に封じ込める、極めて実践的な現実解です。
- PDFから意味のまとまり(チャンク)を正確に抽出する。
- 最新のLLMと構造化出力を用いてFAQを一括生成する。
- 自動評価でノイズを弾き、人間が最終レビューを行う。
- 既存の検索システムやFAQシステムに安全にデプロイする。
このパイプラインを構築することで、組織は既存のシステム資産を活かしながら、安全かつ確実に生成AIの恩恵を顧客や現場の作業員に届けることができます。AIプロジェクトをPoCで終わらせず、真の業務効率化へと繋げるために、ぜひこのアプローチを検討してみてください。まずは動くプロトタイプを作り、実際のデータで検証してみませんか? 確実な一歩が、ビジネスのDXを前進させるはずです。
コメント