はじめに:RAGの回答は「流暢」なだけで十分ですか?
企業のDX推進や業務効率化の現場において、RAG(Retrieval-Augmented Generation)システムの導入プロセスでは、頻繁に直面する課題があります。
それは、「AIの回答は一見すると良さそうだが、本当に業務で使えるレベルなのか?」という、評価の壁です。
PoC(概念実証)の段階では、「社内ドキュメントの内容を答えてくれた」と期待が高まります。しかし、いざ実務のエキスパートが検証すると、反応が冷ややかになるケースは少なくありません。
「この製品の型番、微妙に違う」
「社内ではこの現象を『バグ』ではなく『仕様制限』と呼んでいる」
「略語の使い方が一般的すぎて、社内の文脈に合っていない」
これらは単なる「表記揺れ」ではありません。B2Bや専門領域において、ドメイン固有の専門用語(Terminology)が正確に使われているかどうかは、そのシステムの信頼性を決定する最重要ファクターです。
どれだけ流暢な日本語で回答が生成されていても、肝心のキーワードが抜けていたり、誤った用語が使われていたりすれば、そのRAGは実務に耐えうるツールとは評価されません。
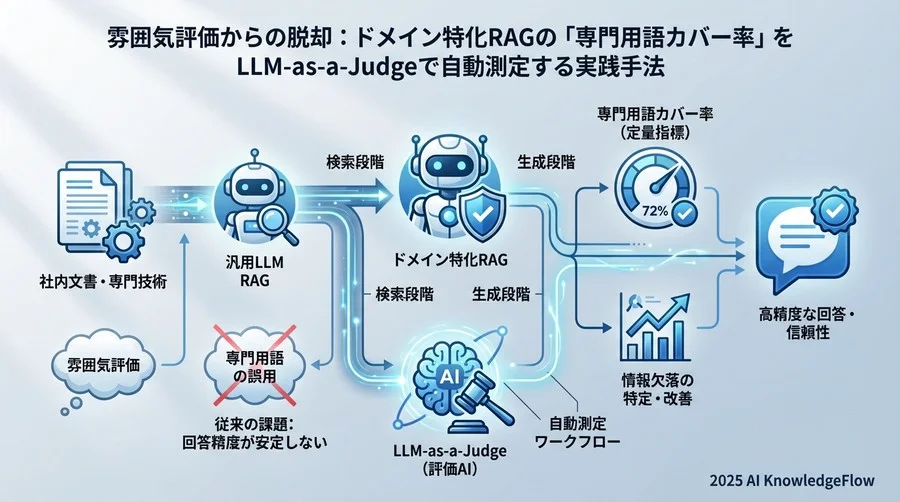
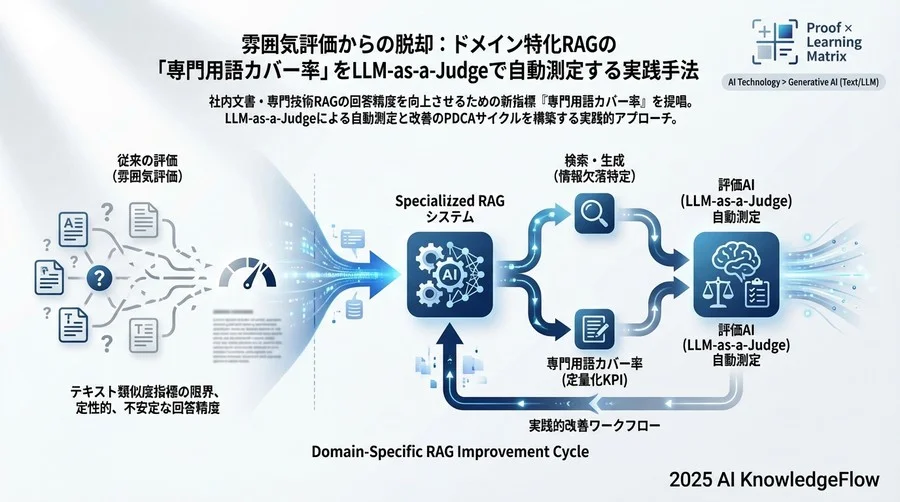
多くの現場でこの精度評価を目視で行う傾向がありますが、持続可能なアプローチとは言えません。プロジェクトマネジメントやシステム開発の観点から目指すべきは、「回答の質」を定量的なKPIに落とし込み、それを自動的に計測・改善できる仕組み(パイプライン)を構築することです。
今回は、実務の現場で効果を上げている「専門用語カバー率(Terminology Coverage)」という指標と、それをLLM-as-a-Judge(評価者としてのLLM)を用いて自動測定する実践的なアプローチについて解説します。
感覚的な評価から脱却し、論理的かつ定量的に語れるエンジニアリングの世界へ、RAGの品質管理レベルを一段階引き上げていきましょう。
ドメイン特化型RAGの成否は「用語の再現性」で決まる
なぜ、ここまで「用語」にこだわる必要があるのでしょうか。まずは、ドメイン特化型RAGにおける「精度」の本質を再定義します。
汎用LLMが陥る「言葉のゆらぎ」問題
ChatGPTやClaudeなど、汎用LLMの推論能力は飛躍的に向上しています。長文コンテキストの理解や、複雑なタスクに応じた推論機能の強化により、回答の論理性はかつてないレベルに達しました。旧世代のモデルから新たな標準モデルへの移行が進む中で、文脈の把握や指示への追従性は大幅に改善されています。
しかし、その学習基盤がインターネット上の公開データであることに変わりはありません。そのため、モデルは一般的な言葉のつながりや、世の中で多数派を占める表現を優先して生成する傾向があります。
企業固有のドメイン(領域)では、世の中の常識とは異なる言葉の使い方がされることが多々あります。
- 社内用語: 「プロジェクトA」ではなく「PJ-Alpha」と呼ぶ。
- 業界用語: 一般的な「顧客」ではなく「パートナー」と定義している。
- 製品仕様: 「防水機能」ではなく「耐水性能IPX7」と厳密に区別する。
どれほど高性能なLLMに移行し、推論能力が強化されたとしても、これらは学習データにおける出現頻度が低いため「確率的に低い表現」と判断されやすく、放っておくと一般的な言葉に言い換えられてしまうリスクがあります。これを「言葉のゆらぎ」と呼びますが、専門業務においては、このゆらぎが重大な誤解を生む原因になり得ます。モデルの進化によって論理的な破綻は減っても、固有用語の丸め込みは構造的な課題として残り続けるのです。
回答精度と専門用語出現率の相関関係
認知心理学の観点からも、人は「自分が知っている専門用語が正しく使われているか」で、相手(この場合はAI)の専門性を判断すると言われています。
例えば、医療従事者向けのRAGが「お腹が痛い」という表現を使ったらどうでしょうか。「腹痛」あるいは具体的な部位を示す専門用語が使われていなければ、医師はその回答を信頼しない可能性があります。たとえ内容の論理が合っていても、専門家としての信頼は損なわれます。
多くの技術サポート導入プロジェクトにおいて、ユーザー満足度と「回答に含まれる正式な製品名の数」に強い相関関係が報告されています。流暢な文章や高度な推論プロセスよりも、「キーワードが網羅されているか」が、実務上の有用性に直結しているのです。
つまり、ドメイン特化型RAGにおいて、ハルシネーション(もっともらしい嘘)を防ぐことと同じくらい、「必要な専門用語を欠落させずに回答に含めること」が重要なKPIとなります。モデルが新しくなるにつれて、単なる回答の流暢さで精度を測る時代は終わりを告げつつあります。専門用語のカバー率こそが、実務で使えるRAGとそうでないRAGを分ける決定的な指標となります。
参考リンク
なぜ従来のテキスト類似度指標(BLEU/ROUGE)では不十分なのか
「精度の測定なら、BLEUスコアやROUGEスコアを使えばいいのでは?」
機械学習の経験がある方なら、そう思われるかもしれません。しかし、RAG、特にドメイン特化型の評価において、これらの伝統的なNLP(自然言語処理)指標はあまり役に立ちません。その理由を技術的な視点で解説します。
表面的な一致では専門性を評価できない理由
BLEUやROUGEは、正解文(Reference)と生成文(Hypothesis)の間で、単語(N-gram)がどれだけ重複しているかを計算します。
例えば、以下の例を見てください。
- 正解文: 「本製品の再起動には、リセットボタンを5秒間長押ししてください。」
- 生成文A: 「この機械を再起動するには、リセットボタンを5秒間押し続けてね。」
- 生成文B: 「本製品の再起動には、電源ボタンを5秒間長押ししてください。」
生成文Aは、「長押し」が「押し続けて」になっており、文体もカジュアルですが、意味は合っています。一方、生成文Bは、文体は正解文にそっくりでN-gramの一致率は高いですが、「リセットボタン」が「電源ボタン」になっており、誤りです。
従来の指標では、生成文Bの方が「スコアが高い(良い回答)」と判定されるリスクがあります。単語の並び順や表面的な一致率だけを見ており、「どの単語が重要か(専門用語か)」という重み付けができないからです。
埋め込みベクトル(Embedding)による類似度判定の落とし穴
では、最近主流のEmbedding(ベクトル化)によるコサイン類似度はどうでしょうか。
OpenAI text-embedding-3 などのモデルを使えば、文の意味的な近さを数値化できます。しかし、ここにも落とし穴があります。
ベクトル空間において、「リセットボタン」と「電源ボタン」は、文脈上非常に近い位置に配置されることが多いです。どちらも「機械を操作するボタン」だからです。その結果、意味的には似ているが、事実としては異なるという微妙な違いを、類似度スコアだけで検知するのは困難です。
特に、型番の違い(「X-100」と「X-200」)などは、ベクトル上では誤差のような扱いになりがちですが、ビジネス上は全く別の製品です。
だからこそ、汎用的な類似度ではなく、「指定した専門用語が含まれているか」という、ルールベースに近い厳格な評価軸(専門用語カバー率)が必要になるのです。
ベストプラクティス1:用語辞書ベースの「ゴールデンデータセット」構築
ここからは、実際に「専門用語カバー率」を測定するための具体的なステップに入ります。まずは測定の基準となる「正解データ(ゴールデンデータセット)」の作り方です。
必須用語リスト(Required Terminology List)の定義
多くの現場では、「質問」と「理想の回答」のペアを作って満足してしまいますが、これだけでは不十分です。ここに「その回答に必ず含まれるべき用語リスト」というカラムを追加します。
スプレッドシートで以下のような管理を行うことが考えられます。
| ID | 質問 (Query) | 理想の回答 (Ground Truth) | 必須用語 (Must-Have Terms) | 重要度 | 関連ドキュメントID |
|---|---|---|---|---|---|
| Q001 | 経費精算の締日はいつですか? | 毎月第3営業日までにConcurで申請し、上長承認を完了してください。 | ["第3営業日", "Concur", "上長承認"] | High | Doc_HR_005 |
| Q002 | VPNがつながらない場合 | GlobalProtectの再接続を試し、ダメならITヘルプデスクへチケット起票してください。 | ["GlobalProtect", "ITヘルプデスク", "チケット起票"] | High | Doc_IT_023 |
このように、回答の文章そのものではなく、「この質問に対しては、このキーワード(用語)を使って説明しなければならない」という制約条件を明文化します。
ドメインエキスパートを巻き込んだ用語選定
この作業はAIエンジニアだけでは完結しません。現場のドメインエキスパート(業務担当者)の協力が不可欠です。
「この質問に対して、『申請』という言葉だけでいいですか?それとも『起票』という言葉を使うべきですか?」
こうしたヒアリングを通じて、用語の重要度をランク付けします。
- Must(必須): これがないと回答として成立しない、または誤解を招く用語(製品名、固有名詞、数値など)。
- Should(推奨): あった方が望ましい専門用語。
- Want(任意): 文脈によるが、自然な表現ならOK。
まずは「Must」の用語だけで評価を始めるのが、スモールスタートのコツです。これを50〜100セット用意できれば、十分なベンチマークテストが可能になります。
ベストプラクティス2:LLM-as-a-Judgeによる「カバー率」判定プロンプト設計
データセットができたら、次は評価の自動化です。人間がいちいち「この単語が入っているか」を目視確認するのは非効率です。Pythonの文字列マッチングでも可能ですが、表記揺れ(「VPN」と「VPN」など)に対応するため、LLM自体を評価者(Judge)として使うアプローチが有効です。
評価AIへの役割付与と判定基準
ここでは、ChatGPTなどの高性能モデルを「厳格な査読者」に見立ててプロンプトを構築します。
以下は、実務で活用できる評価用プロンプトのテンプレートです。LangChainや生のOpenAI API呼び出しで実装可能です。
JUDGE_PROMPT = """
あなたはドメイン知識豊富な専門査読者です。
以下の「ユーザーの質問」に対する「AIの回答」を評価してください。
特に、指定された「必須用語リスト」に含まれる用語が、
回答の中で【正しく】【過不足なく】使用されているかを厳密に判定してください。
## 入力データ
- ユーザーの質問: {query}
- 必須用語リスト: {must_have_terms}
- AIの回答: {generated_answer}
## 判定基準
1. 必須用語が回答テキスト内に存在するか(完全一致または軽微な表記揺れは許容)。
2. その用語が文脈上、正しく使われているか(単に単語があるだけでなく、意味が通っているか)。
## 出力形式
必ず以下のJSON形式のみを出力してください。
{{
"score": 0.0〜1.0の数値(含まれている用語の割合),
"missing_terms": ["回答に含まれなかった用語1", "回答に含まれなかった用語2"],
"reason": "判定の根拠を簡潔に"
}}
"""
Binary判定からスコアリングへの展開
このプロンプトのポイントは、単なる「OK/NG」ではなく、score と missing_terms を出力させている点です。
例えば、必須用語が3つあり、そのうち2つが含まれていれば、スコアは 0.66 となります。これを全テストケースで平均することで、システム全体の「専門用語カバー率」が算出できます。
また、missing_terms をリストとして抽出することで、「どの用語がAIにとって苦手なのか」を集計・分析することが可能になります。「製品B」に関する用語ばかり抜けているなら、その製品に関するドキュメントのインデックス化に問題があるのかもしれない、と推測できます。
Chain-of-Thoughtを用いた判定理由の出力
プロンプト内の reason フィールドも重要です。LLMに判定理由を書かせることで(Chain-of-Thought)、評価自体の精度を高める効果があると考えられます。「なぜこの単語が含まれていないと判定したのか」を後からレビューできるため、評価AI自体のチューニングにも役立ちます。
ベストプラクティス3:検索(Retrieval)と生成(Generation)の用語損失分析
カバー率が低い(例えば60%に留まる)場合、次にすべきは原因の切り分けです。RAGは「検索」と「生成」の2段階プロセスですが、用語はどの段階で欠落したのでしょうか。
これは「用語損失分析(Terminology Loss Analysis)」と呼ばれ、体系的なデバッグを行うために以下のフローが有効です。
1. 検索段階での用語欠落(Retrieval Miss)
まず、RAGが検索してきたドキュメント(Context)の中に、必須用語が含まれているかを確認します。
- 現象: 検索結果のチャンク(文章の塊)の中に、そもそも「必須用語」が存在しない。
- 原因: 検索クエリの作り方が悪い、チャンクサイズが不適切で用語が切れている、あるいは元のドキュメントにその用語がない。
- 対策:
- ハイブリッド検索: ベクトル検索だけでなく、キーワード検索(BM25など)を併用する。専門用語はキーワード検索の方がヒットしやすいです。
- リランク(Re-ranking): 検索結果の上位50件を取得し、Cohereなどのリランクモデルを使って、質問との関連度が高い順に並べ替える。
2. 生成段階での用語消失(Generation Loss)
次に、検索結果には用語が含まれているのに、最終的な回答生成時にLLMがそれを使わなかったケースです。
- 現象: Contextには用語があるが、Answerにはない。
- 原因: LLMがその用語を重要だと認識しなかった、あるいは要約しすぎて削ってしまった。
- 対策:
- システムプロンプトの強化: 「提供されたコンテキスト内の専門用語(特に大文字、製品名)は、言い換えずにそのまま使用してください」と指示する。
- Few-Shotプロンプティング: 用語を正しく使って回答している例(Shot)をプロンプトに含める。
このように、Retrieval Coverage と Generation Coverage を分けて計測することで、闇雲なチューニングを避け、ボトルネックにピンポイントで対策を打てるようになります。
実測データ:専門用語カバー率を40%から90%へ改善したプロセス
製造業における社内技術QAシステムの改善事例として、数値を一般化したモデルケースを紹介します。
プロジェクト初期:スコア42%
初期のRAGは、単純なベクトル検索とGPT-3.5を使用していました。
- 課題: 「A部品の耐熱温度は?」という問いに対し、「高温に耐えられます」といった曖昧な回答が多発。具体的な数値や規格名(JISなど)が出てこない。
- 分析: 検索結果には規格書が含まれていたため、Generation段階での情報の丸め込み(要約過多)が原因と判明。
改善フェーズ1:プロンプト改善とモデル変更(-> 68%)
- 施策: 生成モデルをChatGPTに変更し、プロンプトに「数値や規格名はコンテキストからそのまま引用せよ」と指示を追加。
- 結果: 数値は出るようになったが、社内独自の略語(「T-Spec」など)がまだ無視される。
改善フェーズ2:ハイブリッド検索とリランク導入(-> 85%)
- 分析: 略語で検索した際に、ベクトル検索がうまく機能せず、関連ドキュメントが拾えていないケース(Retrieval Miss)が見られました。
- 施策: キーワード検索を併用し、検索ヒット数を増やした上で、Re-rankingモデルを導入。
- 結果: 略語を含むドキュメントが正しくコンテキストに入り、回答にも反映されるようになった。
改善フェーズ3:用語辞書による事後検証ループ(-> 92%)
- 施策: 本記事で紹介した「LLM-as-a-Judge」による自動評価をCI/CDパイプラインに組み込み、カバー率が低下したらアラートが出るように設定。
- 結果: ドキュメント更新時などの予期せぬ精度低下を即座に検知し、高い水準を維持できるようになった。
このように、定量的なKPIを設定することで、プロジェクトチーム全体が「何が問題で、どうすれば改善できるか」を客観的に議論し、着実に改善プロセスを回すことが可能になります。
アンチパターン:過度な用語強制が生む弊害
最後に注意喚起をしておきます。数字(カバー率)を追うことは重要ですが、それが目的化してはいけません。
文脈を無視したキーワードスタッフィング
「カバー率100%」を目指すあまり、プロンプトで「このリストの用語を全部使え」と強く強制しすぎると、LLMは文脈に関係なく無理やり用語を詰め込んだ、不自然な文章を生成し始める可能性があります。
「本製品はGlobalProtectを使用し、Concurではありませんが、上長承認が必要です。」
これでは日本語として破綻していますし、ユーザーを混乱させます。
ユーザー体験とのバランス
用語カバー率はあくまで「正確性」の一指標に過ぎません。最終的なゴールは、ユーザーの課題解決です。
- 初心者向け: あえて専門用語を噛み砕いて説明する。
- エキスパート向け: 正確な用語で簡潔に答える。
このように、ターゲットユーザーに合わせて「Must用語」の定義を変える柔軟性も必要です。KPIハッキング(数字だけを良くすること)に陥らないよう、定期的に人間による定性評価も組み合わせてバランスを取りましょう。
まとめ:定量評価がRAGの信頼を作る
ドメイン特化型RAGにおいて、「専門用語」は単なる言葉ではなく、その業務知識の結晶です。これを正しく扱えるかどうかが、システムへの信頼を左右します。
- 用語の正確性をKPIにする: 雰囲気評価をやめ、「専門用語カバー率」を定義する。
- ゴールデンデータセットを作る: 必須用語(Must)を紐付けたQ&Aペアを作成する。
- LLMに評価させる: 評価用プロンプトを設計し、自動テストの仕組みを作る。
- 検索と生成を分けて分析する: 用語がどこで消えたかを特定し、適切な技術(リランク、プロンプト指示)で対策する。
このサイクルを回すことで、RAG開発は「手探りの調整」から「エンジニアリングされた改善プロセス」へと進化します。
まずは、プロジェクトで最も重要な「トップ10の専門用語」を選び、それらが正しく回答に含まれているかチェックすることから始めてみてください。その小さな一歩が、信頼されるAIシステムへの飛躍につながるはずです。
次のアクション:
- チーム内で「絶対に間違えてはいけない用語リスト」をブレインストーミングする。
- 現状のRAGに対して、その用語を含む質問を投げかけ、カバー率を算出してみる。
- 評価自動化のためのPythonスクリプトやLangChainの実装を検討する。
コメント