AI導入の現場において、最近特に多いのが「AI議事録ツールを導入したけれど、結局手直しに時間がかかって定着しない」という課題です。
「すごい精度だと聞いて導入したのに、固有名詞はボロボロだし、誰が何を言ったか分からない」「結局、自分でゼロから書いた方が早い気がする」……そんなため息混じりの声が、多くのビジネス現場から聞こえてきます。
技術の本質から言えば、それはツールの性能が悪いからではありません。「AIというシェフに、泥付きの野菜をそのまま投げ込み、レシピも渡さずに『美味しい料理を作れ』と命じている」状態だからです。
AI、特に現在の主流である大規模言語モデル(LLM)を用いたNLP(自然言語処理)技術は、魔法の杖ではありません。非常に優秀な「処理エンジン」ですが、入力されるデータ(食材)の質と、処理の指示(レシピ)が適切でなければ、期待通りのアウトプットは出せないのです。
本記事では、エンジニアではないDX担当者の皆様に向けて、NLPのメカニズムを噛み砕いて解説し、「AIが処理しやすい会議」を設計する方法と、「意図通りの議事録を出力させるプロンプト技術」を共有します。これらは、実務の現場で成果を上げている「Human-in-the-loop(人間参加型)」のアプローチです。
今日から「AIに使われる」のではなく、「AIを使いこなす」ための設計図を一緒に描いていきましょう。
なぜAI議事録は「あと一歩」使えないのか?NLP視点で解明する
まず、敵を知る……いえ、パートナーを知ることから始めましょう。なぜAIが生成する議事録には「違和感」や「嘘」が混じるのでしょうか。その原因は、ツールの性能不足というよりも、私たちが普段無意識に行っているハイコンテクストなコミュニケーションと、AIの処理方式(NLP:自然言語処理)の間に横たわるギャップにあります。
「抽出型要約」と「生成型要約」の違い
従来の要約ツールは、主に「抽出型(Extractive)」と呼ばれる手法を採用していました。これは、文章の中から重要度が高いと判断された文をそのまま「切り抜いて」つなぎ合わせるアプローチです。元発言をそのまま使うため事実は正確ですが、文脈が断絶しやすく、箇条書きの羅列になりがちで「読み物」としての質は低いのが難点でした。
一方、ChatGPTやClaudeなどに代表される最新のAIは「生成型(Abstractive)」です。これは、内容を一度理解した上で、AIが自分の言葉で文章を「再構築」する手法です。人間が要約するプロセスに極めて近く、非常に流暢で自然な文章を作成できます。
しかし、ここに構造的な落とし穴があります。生成型AIは、数千億のパラメータに基づき「確率的に次に来る最も適切な言葉」を予測して文章を紡ぎ出します。最新のモデルでは推論能力が飛躍的に向上していますが、それでも元の発言にない情報を「文脈的に自然だから」という理由で補完してしまうリスクは排除できません。これが「ハルシネーション(幻覚)」です。
例えば、会議で「予算は厳しい」とだけ発言があったとします。AIが文脈を過剰に解釈し、「予算は厳しい(ため、今回は見送る)」と勝手に因果関係を捏造してしまうことがあるのです。実際は「予算は厳しい(が、別枠で検討する)」だったとしてもです。議事録という事実性が命のドキュメントにおいて、この「滑らかな嘘」は最大のリスク要因となります。
AIが苦手とする「文脈の省略」と「指示語」
日本語は世界的に見ても極めて「ハイコンテクスト」な言語です。主語を省いたり、「あれ」「それ」といった指示語のみで会話が成立したりします。私たち人間は、共有している背景知識、過去の経緯、あるいはその場の空気感(非言語情報)を使って、無意識のうちに「あれ=来週のプレゼン資料のことだな」と脳内で補完しています。
しかし、AIにはその「空気」が見えません。AIに渡されるのは、音声認識によってテキスト化された文字列だけです。
- 人間: 「例の件、どうなった?」「あー、ちょっと厳しいですね」
- AIの解釈: (「例の件」の参照先が不明。「厳しい」の対象も不明。確率的に最も関連しそうな直前の話題と結びつけよう)
この情報欠落を、生成型AIは持ち前の推論能力で埋めようとします。その結果、「プロジェクトAの進捗について、厳しいとの報告があった」と、全く別の話題と誤って結合させてしまうエラーが発生します。最新のAIモデルはコンテキストウィンドウ(記憶できる文脈の量)が拡大していますが、そもそも「入力されていない情報(暗黙の了解)」は理解できないという原則は変わりません。
期待値のズレ:AIは「重要」をどう判断しているか
また、「要約して」というシンプルな指示に対するAIの判断基準も理解しておく必要があります。
AIの内部(Transformerアーキテクチャなど)では、Attention(注意機構)と呼ばれる仕組みが働き、単語間の関連性や重要度を計算しています。しかし、AIがデフォルトで「重要」と判断しやすいのは、以下のような要素です。
- 頻出度: 何度も繰り返された単語やフレーズ
- 位置: 発言の冒頭や結論部分
- 情報密度: 具体的な数値や固有名詞が含まれる部分
一方で、ビジネス会議における「重要」はこれとは異なります。「1時間のうち55分議論したが却下されたA案」ではなく、「最後の5分で急浮上し、鶴の一声で採用されたB案」こそが議事録の核心であるべきです。
しかし、AIに何のヒント(コンテキスト)も与えないと、情報量の多いA案の議論を中心に要約を構成してしまいます。これはAIのミスではなく、「重要さの定義」を人間が指示していないことによる不整合です。
この「重み付け」のズレを解消し、AIに私たちの意図する「重要」を理解させることこそが、プロンプトエンジニアリングの真髄なのです。
事前準備:AIが「良い議事録」を書ける環境を整える
「Garbage In, Garbage Out(ゴミが入ればゴミが出る)」はデータサイエンスの鉄則ですが、議事録作成においても同様です。ツールを起動する前、つまり会議の現場で、AIにとって処理しやすい「良質なデータ」を作る準備が必要です。
マイク環境と話者分離(ダイアライゼーション)の重要性
NLP解析の精度を最も左右するのは、実は「音質」です。ノイズが混じっていたり、声が遠かったりすると、そもそも文字起こしの段階でエラーが起きます。
特に重要なのが「話者分離(ダイアライゼーション)」です。「誰が発言したか」を識別する技術ですが、1つのマイクを囲んで複数人が同時に喋ると、AIは誰が話しているか判別不能になります。
- 悪い例: PC内蔵マイクを使い、広い会議室でガヤガヤと話す。紙をめくる音やタイピング音がノイズとして入る。
- 良い例: 指向性マイクやスピーカーフォン(JabraやAnkerなど)を使用し、発言者はなるべく被らないように話す。
これだけで、後のプロセスでの修正工数が3割は減ります。適切に導入した場合、会議室のマイクを全指向性から単一指向性に変えただけで、文字起こしの誤字率が15%前後改善した事例もあります。物理的なデバイスへの投資は、AI活用のROI(投資対効果)を最も確実に高める手段の一つです。
会議冒頭で行うべき「コンテキスト注入」の儀式
最も効果的なテクニックが、会議冒頭での「コンテキスト注入(Context Injection)」です。
AIに対して、この音声データが「何についてのものか」というメタデータを与えるために、会議の最初に司会者が明確に宣言するのです。
「これより、2024年度下期のマーケティング予算配分に関する会議を始めます。本日の参加者は、田中部長、鈴木リーダー、そして私、佐藤です。この会議のゴールは、Web広告費の増額可否を決定することです。」
このように、日時、参加者、議題、ゴールを音声として明示的に吹き込むことで、AIはその後の会話を「マーケティング予算の話だな」というバイアス(良い意味での偏り)を持って解析し始めます。これにより、同音異義語の誤変換や文脈の取り違えが激減します。
資料共有と専門用語リストの活用
社内用語、プロジェクトのコードネーム、独特な略語。これらはAIにとって「未知の単語」です。
高度なAI議事録ツールでは、事前に「ユーザー辞書」を登録できる機能があります。ここに、参加者名やプロジェクト名を登録しておくだけで、「HARITAさん」が「張田さん」に誤変換されるような悲劇を防げます。
もし辞書機能がないツールを使う場合でも、後述するプロンプト入力時に「用語リスト」としてテキストで渡すことで、精度を補完することが可能です。
ステップ1:文字起こしテキストの構造化とクレンジング
録音が終わり、文字起こしテキスト(Transcript)が生成されました。ここでいきなり「要約ボタン」を押してはいけません。ここからが、AIエージェント開発や高速プロトタイピングの知見を活かしたアプローチの本領発揮です。
フィラー(えー、あー)除去と整形処理
生の文字起こしデータには、「えー」「あのー」といったフィラーや、言い淀み、言い直しが大量に含まれています。これらはNLPモデルにとってノイズとなり、文脈理解の妨げになります。
多くのツールには「フィラー除去」機能がついていますので、必ずONにしましょう。もし生データをLLM(ChatGPTなど)に渡す場合は、まず以下のような前処理プロンプトを挟むのが定石です。
「以下のテキストから、意味を変えずにフィラー(えー、あー等)や言い淀みを除去し、読みやすい文章に整形してください。要約はせず、発言内容は保持すること。」
話者の特定とラベル付けの修正フロー
次に確認すべきは「話者ラベル」です。AIが「話者A」「話者B」と分類したものが、実際の参加者と合っているかを確認します。
特に、「部長が承認した」という事実は議事録の核心です。ここが「メンバーの発言」として処理されると、決定事項の重みが変わってしまいます。全文を直す必要はありませんが、「重要な決定発言をしたのが誰か」だけは、人間が目で見て修正しておく必要があります。
タイムスタンプを活用した議論のブロック化
1時間の会議データを丸ごとAIに投げると、話題の遷移を捉えきれず、後半の話題が無視されることがあります。
これを防ぐために、議論のテーマが変わるタイミングでテキストを分割(チャンキング)するか、タイムスタンプを目印に構造化します。
- 00:00 - 10:00:現状報告
- 10:00 - 40:00:課題のブレスト
- 40:00 - 55:00:解決策の決定
このように大まかなブロックを意識し、AIに対して「10分から40分の議論を踏まえて、40分以降の決定事項をまとめよ」と指示できれば、精度は飛躍的に向上します。
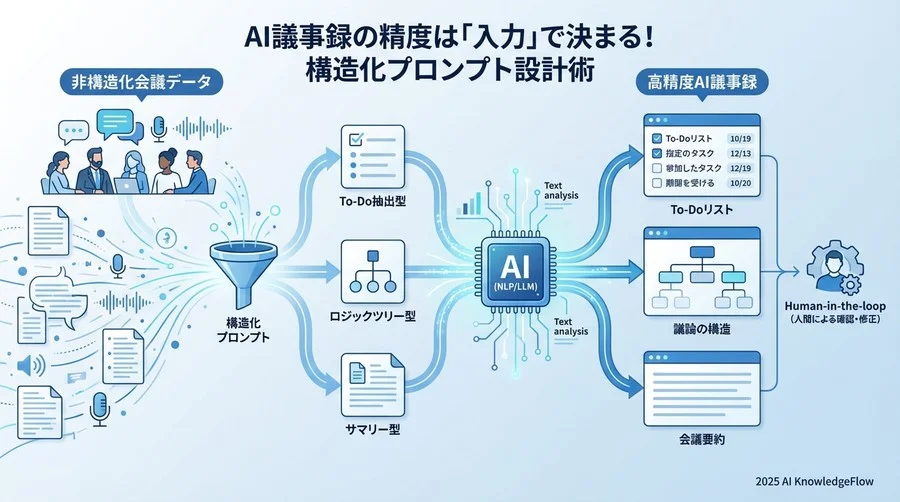
ステップ2:目的別「構造化プロンプト」の設計テンプレート
ここが最も重要な「レシピ」の部分です。「良い感じにまとめて」という曖昧な指示ではなく、出力形式(フォーマット)を厳密に定義した「構造化プロンプト」を使用します。
決定事項を漏らさない「To-Do抽出型」プロンプト
進捗確認会議や定例ミーティングなど、「次に誰が何をするか」を明確にしたい場合に有効です。
# 指示
以下の会議テキストから、決定事項とネクストアクション(To-Do)を抽出してください。
# 制約条件
- 出力はMarkdownの表形式で行うこと。
- To-Doには必ず「担当者」と「期限」を含めること。期限が明言されていない場合は「未定」と記載すること。
- 決定事項は箇条書きで簡潔にまとめること。
# 出力フォーマット例
## 決定事項
- A案の採用を決定
- 予算の上限を50万円に設定
## ネクストアクション
| タスク内容 | 担当者 | 期限 |
| --- | --- | --- |
| 見積書の再取得 | 佐藤 | 10/25 |
議論の経緯を残す「ロジックツリー型」プロンプト
企画会議やブレインストーミングなど、結論に至るまでの「なぜ」や「反対意見」を残したい場合に使います。
# 指示
以下の会議における議論のプロセスを構造化してまとめてください。
# 制約条件
- 提案された案ごとに、メリット・デメリット・結論を整理すること。
- 採用されなかった案についても、なぜ却下されたかの理由を記載すること。
- 議論の中で出た懸念点は漏らさず記載すること。
# 出力フォーマット
## 議題:[議題名]
### 提案A
- メリット:...
- デメリット:...
- 結論:[採用/不採用]
- 理由:...
短時間で内容を把握する「エグゼクティブサマリー型」プロンプト
経営層への報告用など、詳細よりも大枠の把握を優先する場合です。
# 指示
以下の会議内容を、経営層向けに300文字以内で要約してください。
# 制約条件
- 専門用語は極力一般的なビジネス用語に言い換えること。
- 「現状の課題」「決定した対策」「期待される効果」の3点を含めること。
- 感情的な発言や雑談は除外すること。
このように、「誰が読むのか」「何のために使うのか」に合わせてプロンプトを切り替えることが、AI議事録活用の肝です。
ステップ3:人間による最終仕上げ(Human-in-the-loop)の最適化
AIが90%の完成度で出力してきたものを、人間が最後の10%で仕上げます。これをHuman-in-the-loop(人間参加型ループ)と呼びます。この工程をいかに効率化するかが、業務システム設計やDXの成否を分けます。
AIが見落とす「非言語情報」の補完
AIはテキスト情報を処理しますが、実際の会議には「沈黙」「苦笑い」「強い口調」といった非言語情報が含まれています。
例えば、テキスト上では「わかりました」となっていても、現場では「(渋々)わかりました」だったかもしれません。このようなニュアンスは、その場にいた人間しか補完できません。議事録の備考欄に「※担当者は難色を示していたため、フォローが必要」と一言添える。これこそが、人間にしかできない付加価値の高い仕事です。
ハルシネーション(嘘)の効率的なチェック方法
AIの生成物をチェックする際は、全文を読み直すのではなく、以下のポイントに絞って「スポット検品」を行います。
- 数値: 金額、日付、個数。これらは最も間違いやすく、かつ影響が大きい箇所です。
- 固有名詞: クライアント名、製品名。
- 否定形: 「やらない」が「やる」になっていないか(AIは否定語の処理を時々ミスします)。
これらを重点的にチェックし、文法や細かい言い回しの修正には時間をかけないことがコツです。
チームへの共有とフィードバックループの構築
作成した議事録をチームに共有する際、「AIが作ったので間違っているかもしれません」と言い訳をするのはやめましょう。代わりに、「AIで作成し、重要ポイントを確認しました。修正点があればフィードバックください」と伝えます。
そして、チームから指摘された修正内容は、次回のプロンプト設計や辞書登録に反映させます。「前回、プロジェクトコードXが誤認識されていたから、今回は辞書に入れておこう」という改善のサイクル(ループ)を回すことで、AI議事録システムは組織に特化した「専用秘書」へと育っていくのです。
実務の現場では、このフィードバックループを3ヶ月回した結果、議事録作成にかかる時間が1回あたり40分から5分へと8分の1に短縮された事例も報告されています。AIは教えれば教えるほど賢くなりますが、教えるのは常に人間の役割です。
まとめ:AI議事録は「作成」から「設計」の時代へ
AI議事録の導入は、単なる「文字起こしの自動化」ではありません。それは、会議という業務プロセスそのものを、データとして扱いやすい形に「再設計(リデザイン)」する取り組みです。
最後に、本記事のポイントを整理します。
- 仕組みを知る: AIは文脈を読むのが苦手。抽出型ではなく生成型であることを意識し、ハルシネーションに注意する。
- 入力を整える: マイク環境を整え、会議冒頭で「コンテキスト注入」を行う。
- 指示を設計する: 目的(To-Do抽出、経緯記録、サマリー)に合わせて構造化プロンプトを使い分ける。
- 人間が補完する: 非言語情報と重要事実(数値・固有名詞)のチェックに集中し、AIを育てる。
明日からの会議で、まずは冒頭の「コンテキスト注入」から試してみてください。「今日は〇〇を決める会議です」とマイクに向かって宣言する。たったこれだけで、AIのアウトプットが変わるのを実感できるはずです。
現在、「自社の会議スタイルに合わせたプロンプトを設計したい」「セキュリティを担保しながら、過去の議事録データをAIに学習させたい」といった課題を抱える企業が増えています。会議データという「原石」をビジネスの武器に変えるためには、最適なAIパイプラインの構築と、まず動くプロトタイプを作って検証するアプローチが不可欠です。
コメント