「あの資料、どこに保存したっけ?」
この一言から始まる不毛な探索時間は、現代のオフィスにおける最大の「見えないコスト」かもしれません。クラウドストレージの導入で、いつでもどこでもファイルにアクセスできるようになったはずが、皮肉なことに私たちは以前よりも多くの時間を「ファイル探し」に費やしています。
BoxやSharePoint、Google Driveといったクラウドストレージは、確かに便利です。しかし、そこに保存されるデータの90%以上は「非構造化データ」――つまり、データベースのように整理されていない文書ファイルや画像、動画です。これらが無秩序に蓄積された状態は、いわば「デジタルゴミ屋敷」と言えます。
多くの企業がこの問題に対し、フォルダ階層のルール化やファイル名規則の徹底で対抗しようとします。しかし、断言してもいいでしょう。人間による手動整理は、必ず破綻します。
なぜなら、情報の「意味」は多義的であり、一つのフォルダ(箱)に収まりきらないからです。そして今、この積年の課題に対し、LLM(大規模言語モデル)という強力な解決策が登場しました。これは単なる「自動化」ではありません。コンピュータが初めて「文脈」を理解し、人間と同じように、あるいはそれ以上に緻密に情報を整理できるようになったという、歴史的な転換点なのです。
本記事では、AI導入コンサルタントの視点から、顧客体験と業務効率の両立を意識しつつ、なぜ従来の検索では見つからないのか、そしてLLMがどのようにして非構造化データの整理に革命をもたらすのか、その技術的裏側と設計思想を解剖していきます。
ツールを導入する前に、まずはその「仕組み」を正しく理解することから始めましょう。それが、失敗しないDXの第一歩です。
なぜクラウドストレージは「デジタルゴミ屋敷」化するのか
「弊社ではフォルダ構成のルールを徹底していますから大丈夫です」
実務の現場において、ルールを徹底している企業であっても、実際のストレージの中身は迷宮のような階層構造になり、頭を抱えているケースが少なくありません。個人の整理整頓能力の問題ではなく、従来のファイル管理システムそのものが抱える構造的な欠陥に起因しています。
階層型フォルダ管理の構造的限界
私たちが慣れ親しんでいる「フォルダ」という概念は、物理的な「書類棚」のメタファー(比喩)です。物理的な紙の書類は、同時に2つの場所に存在することができません。したがって、「2024年度」のフォルダに入れるか、「プロジェクトA」のフォルダに入れるか、「請求書」のフォルダに入れるか、どれか一つを選ぶ必要があります。
しかし、実際の業務において、あるドキュメントは「2024年度」のものであり、かつ「プロジェクトA」に関連し、かつ「請求書」でもあります。この多面的な属性を持つ情報を、単一のツリー構造(階層構造)に押し込めようとすること自体に無理があるのです。
結果として何が起こるか。
- 重複保存の発生: 「プロジェクトA」フォルダと「経理部」フォルダの両方に同じファイルをコピーして保存する。
- 迷子の発生: 作成者は「プロジェクトA」に入れたつもりだが、探す人は「経理部」フォルダを探して見つからない。
- 階層の深化: 「2024年」→「営業部」→「第1四半期」→「取引先企業」→「契約関連」…と階層が深くなりすぎ、誰も辿り着けない。
このように、フォルダ階層による管理は、情報の量が増えれば増えるほど検索性が低下する「負のスケールメリット」を持っています。
人間による手動タグ付けが100%形骸化する理由
フォルダの限界を補うために導入されるのが「タグ付け」や「メタデータ付与」です。多くのドキュメント管理システム(DMS)にはこの機能が備わっています。しかし、これを人間に任せると、遅かれ早かれ必ず形骸化します。
理由はシンプルです。タグ付けは、作成者にとっては「面倒な作業」であり、その恩恵を受けるのは「将来の検索者」だからです。
今忙しい作成者にとって、ファイルをアップロードする際に「文書種別」「関連プロジェクト」「機密レベル」などの属性をいちいちプルダウンから選択するのは、苦痛以外の何物でもありません。その結果、どうなるか。
- デフォルト値の乱用: 全ての項目で一番上の選択肢(例:「その他」や「一般」)が選ばれる。
- 入力漏れ: 必須項目以外は空欄になる。
- 表記ゆれ: 「見積書」「見積り」「Estimate」など、人によって入力する言葉がバラバラになる。
これでは、検索時にタグを活用することができません。人間は、自分に直接的なメリットがない作業を継続できない生き物なのです。
キーワード検索だけでは「文脈」を拾えない
「Googleのようにキーワード検索できればいいのでは?」と思われるかもしれません。確かに全文検索エンジンは進化しましたが、依然として「キーワードの一致」に依存しています。
例えば、「コスト削減の提案書」を探したいとします。しかし、ファイルの中に「コスト削減」という単語が一度も出てこず、「経費適正化」や「予算圧縮」、「Bottom line improvement」と書かれていたらどうでしょうか。従来のキーワード検索では、これらはヒットしません。
また、「契約書ではない資料」を探そうとして「-契約書」と除外検索をしても、本文中に「本契約書に基づき…」という参照文言があれば、そのファイルはヒットしてしまいます。文脈(コンテキスト)を理解せず、単なる文字列のパターンマッチングを行っている限界がここにあります。
クラウドストレージがゴミ屋敷化するのは、管理者の怠慢ではありません。「多義的な意味を持つ情報を、硬直的な箱(フォルダ)に入れ、曖昧な言葉(キーワード)で探そうとしている」というアプローチそのものの限界なのです。
LLMによる「意味理解」と自動分類のメカニズム
ここで登場するのが、LLM(Large Language Model)です。LLMは、従来のプログラムとは全く異なるアプローチでテキストを扱います。キーワードの一致ではなく、「意味の近さ」を計算するのです。顧客体験を損なう「検索しても見つからない」という課題は、この新しいアプローチによって劇的に改善されると考えます。
キーワードマッチ vs セマンティック理解
従来の検索が「辞書的な照合」だとすれば、LLMによる処理は「司書による文脈の読解」に近いと言えます。
例えば、「Apple」という単語があったとき、従来のシステムは単に「A-p-p-l-e」という文字列として認識します。しかし、LLMは前後の文脈を読み取ります。
- 「Appleはおいしい」→ 果物のリンゴ
- 「Appleの株価が上がった」→ テクノロジー企業のApple
前後の文脈から、その単語が何を指しているのかを推論できるのです。これにより、表記が異なっていても意味が同じであれば関連付けることが可能になります。「自動車」と「クルマ」、「Car」を同じ概念として扱えるのは、このセマンティック(意味論的)な理解があるからです。業務効率化の観点からも、ユーザーがどのような言葉で検索しても適切なドキュメントにたどり着ける仕組みは非常に有益です。
ベクトル埋め込み(Embeddings)が実現する「概念の数値化」
この「意味理解」を技術的に支えているのが、「ベクトル埋め込み(Embeddings)」という技術です。
コンピュータは言葉をそのまま理解できません。そこで、言葉や文章を数百から数千次元の「数値の列(ベクトル)」に変換します。これを「埋め込み」と呼びます。
巨大な多次元空間の中に、あらゆる言葉が配置されている状態を想像してみてください。意味が似ている言葉同士は近くに、意味が遠い言葉は遠くに配置されます。
- 「犬」と「猫」のベクトルは、空間内の距離が近い。
- 「犬」と「冷蔵庫」のベクトルは、距離が遠い。
ドキュメント分類においては、ファイルの中身(テキスト)をこのベクトルに変換し、あらかじめ定義されたタグ(例:「請求書」「契約書」「仕様書」)のベクトルと比較します。そして、「このドキュメントのベクトルは、『請求書』タグのベクトルと最も距離が近い(角度が似ている)」と判断されれば、AIはそれを「請求書」と分類するのです。
これが、キーワードが含まれていなくても分類できる理由です。「支払いのお願い」というタイトルの文書でも、その内容のベクトルが「請求書」概念のベクトルに近ければ、正しく分類されます。
LLMが「請求書」と「見積書」を文脈で区別する仕組み
さらに高度化したLLM(GPT-4やClaude 3など)は、単なる単語の近さだけでなく、文書全体の論理構造や文脈を深く理解します。近年では100万トークンを超える長大なコンテキストに対応するモデルも登場しており、複雑な資料や長文の処理能力が飛躍的に向上しています。
「請求書」と「見積書」は、使われている単語(金額、品目、日付、会社名など)が非常に似通っており、単純なベクトル化だけでは区別が難しい場合があります。しかし、推論能力が向上した現在のモデルは、以下のような文脈の手がかりを正確に捉えます。
- 時制: 「〜の予定です(見積)」か「〜をご請求します(請求)」か。
- 条件: 「有効期限(見積)」か「支払期限(請求)」か。
- 目的: 提案の段階か、取引確定後の段階か。
特に最新の推論特化型モデル(思考プロセスを伴うモデルなど)では、複雑なビジネス文書や曖昧な条件下でも判断のブレが少なくなっています。LLMに対して単に分類を指示するだけでなく、「文書の目的を特定し、判断根拠をステップごとに計画してから分類せよ」といったタスク分割のワークフロー(具体的なコンテキスト指定やエージェント的なアプローチ)を用いることで、人間と同じように文書の意図を解釈し、高精度な分類を実現します。
ルールベース(if文)で「"請求"という文字があったら請求書」と定義するのとは、次元の違う柔軟性と精度を実現しているのです。これにより、顧客対応のバックエンド業務も大幅に効率化されると考えます。
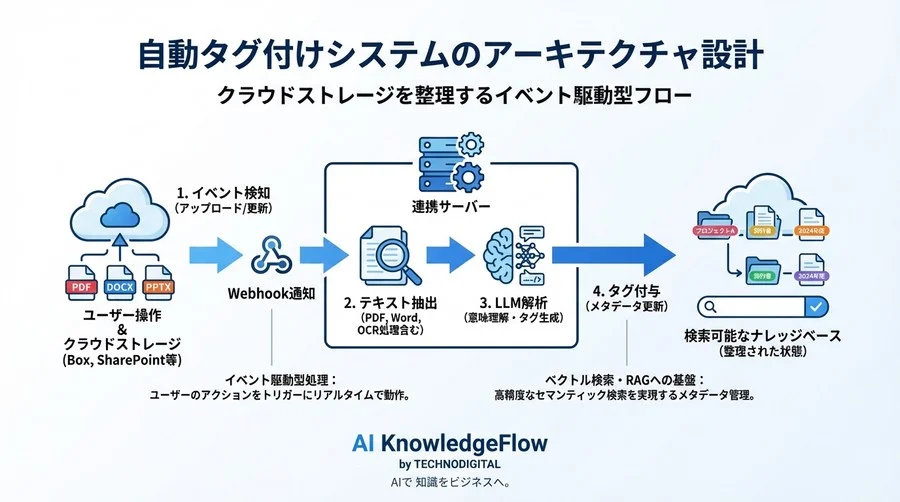
自動タグ付けシステムのアーキテクチャ設計
では、実際にこの技術をクラウドストレージにどう組み込むのでしょうか。ここでは、ベンダー製品の中身で何が行われているか、あるいは自社開発する場合の標準的なアーキテクチャについて解説します。
イベント駆動型処理フロー(アップロード→解析→付与)
システムは通常、ユーザーがファイルを操作したタイミングをトリガー(きっかけ)として動作する「イベント駆動型」で設計されます。
- イベント検知: ユーザーがBoxやSharePointにファイルをアップロード(または更新)する。
- Webhook通知: クラウドストレージから連携サーバーへ「新しいファイルが来た」という通知が飛ぶ。
- テキスト抽出: 連携サーバーがファイルを取得し、PDFやWord、PowerPointからテキストデータを抽出します。ここでは最新のAI-OCR技術が重要な役割を果たします。従来のOCRでは困難だった手書き文字や非定型帳票の読み取り精度が大幅に向上しているほか、表形式の構造を維持したままテキスト化したり、抽出段階でデータのクレンジング(ETL処理)を行ったりすることが可能になっています。
- LLM解析: 抽出したテキストと、分類ルール(プロンプト)をLLM APIに送信する。
- メタデータ生成: LLMが解析結果(カテゴリ、日付、重要度など)をJSON形式で返す。
- メタデータ書き込み: 連携サーバーがクラウドストレージのAPIを叩き、元のファイルにメタデータ(タグ)を付与する。
この一連の流れが、ユーザーが意識することなくバックグラウンドで数秒〜数十秒のうちに実行されます。ユーザーから見れば、ファイルをアップロードして一息ついた頃には、すでに適切なタグが付与されている状態になります。
構造化データ抽出(JSON出力)のプロンプト設計
ここで最も重要なのが、LLMからの出力をいかにシステムで扱いやすい形にするかです。LLMは放っておくと「この文書は請求書だと思われます。なぜなら…」と人間のように喋り出してしまいます。これではシステムがタグとして登録できません。
そこで活用されるのが、OpenAIの「Structured Outputs(構造化出力)」や「Function Calling」といった機能です。特に最新のモデルでは、事前に定義したデータ構造(JSONスキーマ)に完全に準拠した出力を生成する能力が強化されています。これにより、LLMに対して以下のような厳格な出力を強制できます。
{
"document_type": "invoice\
",
"issue_date": "2024-04-01",
"total_amount": 500000,
"confidence_score": 0.98
}
このように、文書の種別だけでなく、日付や金額といった特定の属性データまで正確に抽出させることができます。これにより、後続のシステムは受け取ったJSONの値をそのままAPI経由でクラウドストレージのメタデータプロパティにマッピングするだけで済むのです。プログラマティックに処理できるこの確実性こそが、LLMを単なるチャットボットから「バックエンドの処理エンジン」へと昇華させる鍵となります。
セマンティックタグ付けがもたらす「検索体験の再定義」
自動付与された正確なメタデータが蓄積されると、ユーザーの検索体験は劇的に変わります。もはや「どのフォルダに保存したか」を思い出す必要はありません。
属性を掛け合わせた高度な絞り込み(ファセット検索)
文書種別や日付、金額などのタグが構造化データとして付与されていれば、「先月アップロードされた、金額が50万円以上の請求書」といった複雑な条件での絞り込みが瞬時に可能になります。キーワードの有無に依存する全文検索では不可能だった、データベースのような精緻な検索が、非構造化データに対しても適用できるのです。
RAG(検索拡張生成)の基盤としての価値
さらに重要なのは、このセマンティックタグ付けが次世代のAI活用基盤になるという点です。近年注目を集めているRAG(社内データを活用したAI回答システム)を構築する際、ノイズだらけの「デジタルゴミ屋敷」をそのまま読み込ませても、AIは関係のない文書まで参照してしまい、誤った回答(ハルシネーション)を引き起こす確率が高くなります。
しかし、事前にLLMによって整理・分類された質の高いメタデータが付与されていれば、「契約書カテゴリの中から、特定の条項に関する情報を抽出する」といったように、AIの検索範囲を適切に絞り込むことができます。つまり、セマンティックタグ付けは、単なる検索の効率化にとどまらず、企業内データのAI活用を成功させるための必須条件とも言えるのです。
まとめ:人間は「整理」から解放され、「創造」へ向かう
フォルダ階層という物理的な書類棚のメタファーは、デジタルデータが爆発的に増加する現代において、すでに限界を迎えています。人間が手作業でルールを守り、タグを付けることで秩序を保とうとするアプローチは、必ずどこかで破綻します。
LLMによる「セマンティックタグ付け」は、テキストの文脈や意味を理解し、自動的かつ正確に情報を構造化する画期的なアプローチです。コンピュータが初めて自ら情報の意味を解釈し、適切なメタデータを付与できるようになった今、私たちが「ファイル探し」に時間を奪われる理由はなくなりました。
情報の整理はAIに任せ、人間はそこから得られた情報を活用して新たな価値を生み出すことに集中する。それこそが、本来あるべきデジタル変革の姿です。自社のクラウドストレージが「デジタルゴミ屋敷」化していると嘆く前に、まずはこの「意味で探せる」新しい情報管理の仕組みへ目を向けてみてください。ツールに合わせた人間の努力を強いるのではなく、人間の思考に寄り添うシステムの構築こそが、ファイル探索にかかる時間を大幅に削減できるだけでなく、顧客対応のスピード向上という定量的な成果にも直結し、業務効率化の真のブレイクスルーとなるはずです。
コメント