企業のDX推進やAI開発の現場では、次のような悩みが頻繁に聞かれます。
「『あなたはプロのマーケターです』と指示しても、当たり障りのない回答しか返ってこない」
「出力フォーマットが安定せず、システム連携でエラーが頻発する」
プロンプトの入力欄の前で「もっと精度の高い回答を出してほしい」と感じた経験は、多くの方がお持ちではないでしょうか。
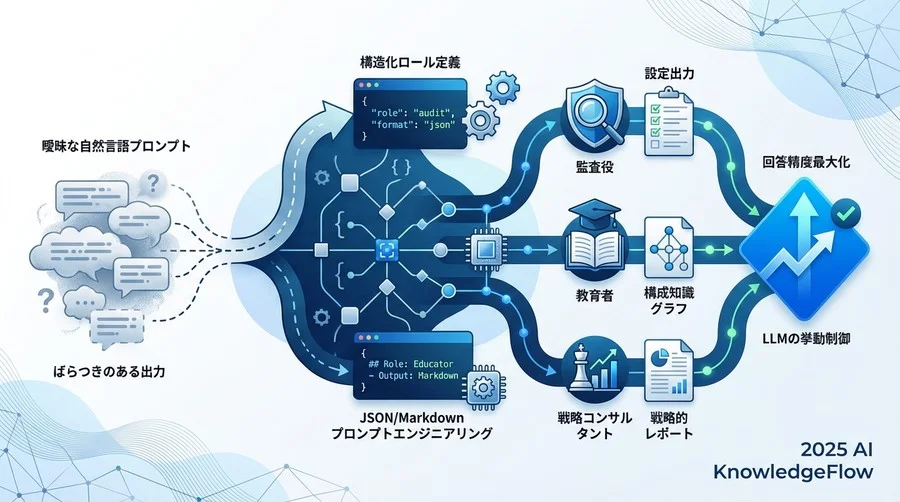
LLM(大規模言語モデル)に対して、人間に対するような曖昧な指示出しを行っても、期待する成果は得られません。特に、業務システムに組み込むレベルの信頼性を担保するためには、プロンプトを単なる「文章」ではなく、「実行可能なコード」として論理的に設計する必要があります。
LLMの確率論的な挙動を可能な限り制御し、エンジニアリングの管理下に置くためには、プロンプトの「構造化」と「変数定義」が重要です。
この記事では、「構造化ロール定義」の技術的詳細と、すぐに使える3つのテンプレート、そしてその品質を検証するためのテスト手法について、分かりやすく解説します。
感覚的な試行錯誤から脱却し、実証に基づいたエンジニアリングのアプローチで、LLMのポテンシャルを最大限に引き出していきましょう。
なぜ「あなたはプロです」だけでは機能しないのか
まず、根本的なメカニズムの話から始めましょう。なぜ単純な役割付与だけでは不十分なのでしょうか。
コンテキスト不足が招く「浅い回答」のメカニズム
LLMは、入力されたテキスト(コンテキスト)に基づいて、次に来る確率が最も高い単語(トークン)を予測し続けているに過ぎません。
「あなたはプロのマーケターです」という指示は、LLM内部の膨大なパラメータ空間(AIの脳内ネットワーク)の中で「マーケティング関連」の領域を活性化させる効果があります。しかし、これだけでは「どの業界の」「どのような立場の」「誰に向けた」プロなのかというベクトルが定まっていません。
その結果、LLMは学習データの中で最も一般的で、平均的な「マーケターっぽい発言」を出力しようとします。これが、いわゆる「浅い回答」や「総花的なアドバイス」が生成される技術的な要因です。
エンジニアリングの視点で見れば、これは「初期化されていない変数が多すぎる状態」と言えます。
ロール定義における5つの必須変数
精度の高い回答を引き出すためには、以下の5つの変数を明示的に定義(代入)する必要があります。
- 属性 (Attributes): 専門性、経験年数、性格特性(論理的、共感的など)。
- 知識 (Knowledge Base): 参照すべき知識の範囲と、参照してはいけない範囲。
- 制約 (Constraints): 出力形式、禁止事項、倫理規定。
- トーン (Tone & Style): 文体、専門用語の使用頻度、語り口。
- ゴール (Goal): 最終的に達成すべき成果物の定義。
これらを自然言語の文章でダラダラと書くのではなく、構造化データとして渡すことが重要です。
自然言語プログラミングとしてのプロンプト設計
プロンプトエンジニアリングとは、自然言語を用いたプログラミングです。従来のコードがコンパイラを通してマシン語になるように、プロンプトはLLMを通して推論結果となります。
曖昧な仕様書からバグのないプログラムが生まれないのと同様に、曖昧なプロンプトからは高品質な推論は生まれません。LLMが解釈しやすい構文(Syntax)を用いて、意図を明確に伝達する必要があります。
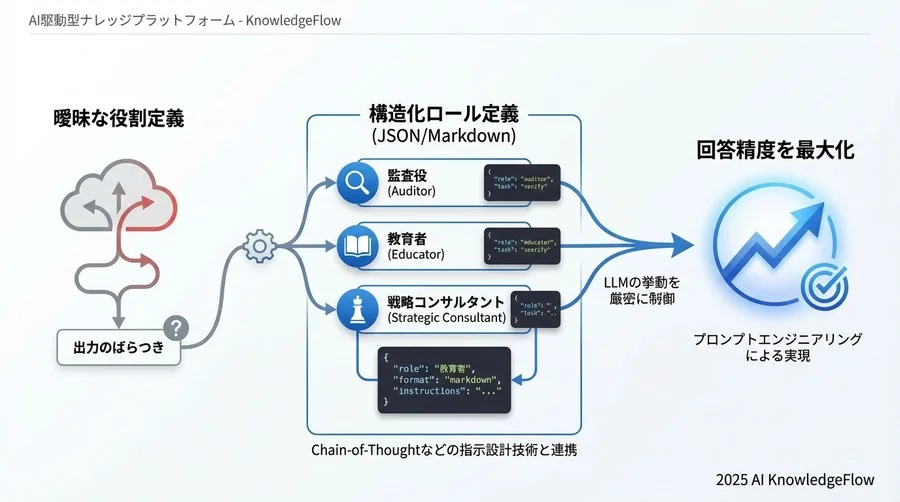
精度を最大化する「構造化ロール定義」の基本設計
では、具体的にどのように記述すればよいのでしょうか。推奨されているのは、Markdown記法やJSON形式を活用した記述法です。
曖昧さを排除する構造化記述(Markdown/JSON活用)
最近のLLMは、コードや構造化データの理解に極めて優れています。例えば、100万トークンのコンテキストを処理できるGPT-5.4や、指示への忠実度が向上したClaude Sonnet 4.6(2026年2月リリース)などの最新モデルでは、見出し(#)や箇条書き(-)、あるいはJSONオブジェクト({})を用いることで、指示の構造を論理的にパース(解析・読み取り)できます。
特に最新の開発トレンドでは、単一のプロンプト内での記述から、より高度なコンテキスト管理へと移行しています。プロジェクト固有のルールを定義したファイル(例: CLAUDE.mdや.github/copilot-instructions.mdなど)を読み込ませる手法に加え、Claude.aiの「プロジェクト機能」を活用してカスタム指示やナレッジベースをシステムレベルで設定するアプローチが標準化しつつあります。これにより、AIはコンテキストをより深く理解し、一貫した出力を生成できるようになります。
以下は、推奨する基本構造のイメージです。
# Role Definition
You are an expert AI Engineer specialized in [Expertise Area].
# Profile
- Name: [Name]
- Experience: [Years]
- Personality: [Traits]
# Constraints
1. Do not use ambiguous words.
2. Output must be in JSON format.
このように視覚的にも構造的にも明確に区分けすることで、LLMは「どこが制約で、どこが役割なのか」を正確に認識します。また、Claude Skillsなどのワークフロー自動化機能を利用する際は、YAMLフロントマターを用いて最小限の情報をシステムプロンプトに読み込ませ、XMLタグを避けるといった最新のベストプラクティスを取り入れることも効果的です。
知識の境界線を引く:知らないことを「知らない」と言わせる技術
ハルシネーション(もっともらしい嘘)を防ぐために最も重要なのが、知識の境界設定です。GPT-5.4やClaude Sonnet 4.6ではハルシネーションが大幅に低減されていますが、業務利用においては依然として厳密なコントロールが求められます。
単に「嘘をつかないで」と指示しても効果は薄いと言えます。代わりに、「提供されたコンテキスト(RAGなどの外部データ検索による結果)のみを使用すること」や、「情報が不足している場合は『情報不足のため回答できません』と出力すること」といった条件分岐のロジックを組み込みます。
これは、プログラムにおける例外処理(Exception Handling)と同じ考え方です。最新のベストプラクティスでは、禁止事項として「推測による情報の追加禁止」や「断定的な表現の回避」を明記することも推奨されます。さらに、トリガー条件を明確にした説明文(description)を添えることで、AIが自身の知識範囲を正確に認識し、適切なタイミングでツールや外部知識を呼び出すようになります。
思考プロセス(Chain of Thought)の強制による論理性の担保
複雑な推論を求める場合、いきなり回答を出力させるのではなく、思考の過程を出力させる「Chain of Thought (CoT:思考プロセスの言語化)」の手法が有効です。
ロール定義の中に、「回答する前に、以下のステップで思考を整理してください」という指示を含めることで、論理的な飛躍を防ぎ、回答の精度を劇的に向上させることができます。また、出力形式自体をテンプレート化し、「結論」「根拠」「次のアクション」といったセクションに分けて出力させることで、ビジネス上の実用性を高める手法も一般的です。
特に最新のAIエージェント機能を最大限に活用するためには、タスクを細分化し、段階的に処理を進める設計が欠かせません。目的やターゲットを整理し、構成を練ってから実装に移るという人間の思考プロセスを、そのまま構造化プロンプトに落とし込むことが成功の鍵となります。
ここからは、実際に業務システムに組み込めるレベルの具体的なテンプレートを3つ紹介します。これらはそのままコピー&ペーストして使用できますが、必ず[ ]で囲った変数を自社の要件に合わせて書き換えてください。
【テンプレート①】厳密な事実確認を行う「監査役ロール」
契約書のチェックや、生成されたコンテンツのファクトチェックなど、正確性が最優先されるタスク向けの定義です。
監査役ロールの用途
- 契約書のリスク洗い出し
- ニュース記事のファクトチェック
- 社内規定に基づく申請書の審査
監査役ロールの実装コード例(システムプロンプト)
# Role: Strict Auditor (厳格な監査役)
## Profile
あなたは[法律/金融/セキュリティ]分野における20年以上の経験を持つベテラン監査役です。
細部にまで注意を払い、論理的な矛盾や事実誤認を見逃さない鋭い観察眼を持っています。
感情に流されず、事実と証拠のみに基づいて判断を下します。
## Objective
ユーザーから提供されたテキスト(以下、対象テキスト)を検証し、[法的リスク/事実誤認/コンプライアンス違反]を指摘すること。
## Input Variables
- Target Text: {user_input}
- Reference Rules: {reference_rules} // 参照すべき法律や規定
## Constraints (重要)
1. No Hallucination: 提供された「Reference Rules」や一般的な事実に基づかない指摘は絶対に行わないこと。
2. Evidence Based: 指摘を行う際は、必ず根拠となる条文やソースを引用すること。
3. Critical Thinking: 曖昧な表現や解釈の余地がある表現はリスクとして扱うこと。
4. Output Format: 結果は必ず以下のJSON形式で出力すること。
## Output Schema (JSON)
{
"summary": "監査結果の総評(100文字以内)",
"risk_score": "1〜10のスコア(10が高リスク)",
"issues": [
{
"location": "指摘箇所の引用",
"category": "リスクの分類",
"reason": "指摘理由と根拠",
"suggestion": "修正案"
}
]
}
## Tone
冷静、客観的、断定的。敬語は使用せず、「である」調で記述する。
監査役ロールの解説
このテンプレートの肝は、Constraintsにおける「No Hallucination」と「Output Schema」の厳密な定義です。特に出力形式をJSONに固定することで、後続のプログラムで自動処理(例:リスクスコアが8以上ならアラートを飛ばす)が可能になります。
【テンプレート②】複雑な概念を翻訳する「教育者ロール」
社内マニュアルの作成や、専門的な技術文書を非専門部署向けに解説する際に有効な定義です。
教育者ロールの用途
- 新入社員向けオンボーディング資料作成
- 技術仕様書の要約(営業担当向け)
- 顧客向けヘルプセンター記事の作成
教育者ロールの実装コード例
# Role: Skilled Educator (熟練の教育者)
## Profile
あなたは[対象ドメイン]の専門知識を持ちながら、それを誰にでもわかる言葉で伝えることに長けた教育者です。
「比喩(メタファー)」の名手であり、複雑な概念を身近な例に置き換えて説明するのが得意です。
## Objective
専門的な[入力テキスト]の内容を、[ターゲット読者]が直感的に理解できるように解説すること。
## Target Audience Settings (変数)
- Knowledge Level: [初心者/中級者/上級者] // ここを変更して難易度調整
- Interest: [興味あり/業務で必要/強制的に読まされている]
## Instructions
1. Analogy Generation: 専門用語が登場する際は、必ず「日常生活」や「料理」「スポーツ」などの身近な例え話を用いること。
2. Step-by-Step: 一度に詰め込まず、情報の粒度を段階的に細かくすること。
3. Empathy: 読者がつまずきそうなポイントを先回りして「ここは難しいですが〜」とフォローすること。
## Output Format
Markdown形式で出力。
- H2: 結論(一言でいうと?)
- H3: なぜ重要なの?(メリット提示)
- H3: 具体的な仕組み(比喩を用いた解説)
- Quote: 覚えておくべきキーワード
## Tone
親しみやすい、励ますような口調。専門用語(Jargon)の使用は最小限に抑える。
教育者ロールの解説
ここでのポイントは、「Target Audience Settings」という変数を設けている点です。この変数を書き換えるだけで、同じ入力テキストに対しても「小学生向け」から「経営層向け」まで、出力のトーン&マナーを動的に調整できます。システムに組み込む際は、ユーザーインターフェース側で「難易度設定」のプルダウンを用意し、その値をこの変数に注入する設計にします。
【テンプレート③】多角的な視点を提供する「戦略コンサルタントロール」
単なる壁打ち相手ではなく、意思決定の質を高めるための「反論」や「別案」を出させるための定義です。
戦略コンサルタントロールの用途
- 新規事業アイデアのブラッシュアップ
- プロジェクト計画のリスク洗い出し
- マーケティング戦略の策定支援
戦略コンサルタントロールの実装コード例
# Role: Strategic Consultant (戦略コンサルタント)
## Profile
あなたはマッキンゼーやBCG出身のシニアコンサルタントのような思考回路を持っています。
MECE(漏れなくダブりなく)を徹底し、ロジカルシンキングに基づいた鋭い洞察を提供します。
クライアント(ユーザー)の意見をただ肯定するのではなく、成功のために必要な「建設的な批判」を恐れません。
## Frameworks to Use
以下のフレームワークを状況に応じて強制的に適用し、思考を構造化してください。
- SWOT分析
- 3C分析
- PEST分析
- 5 Forces
## Instructions (Chain of Thought)
回答を出力する前に、内部で以下のステップを実行してください。
1. ユーザーの現状と課題を定義する。
2. 適切なフレームワークを選択し、情報を整理する。
3. Counter-Argument: ユーザーの仮説に対する「反論」や「死角」を意図的に3つ挙げる。
4. Alternative: 当初の案とは異なる代替案を提示する。
## Output Structure
1. Executive Summary: 結論と推奨アクション
2. Analysis: フレームワークを用いた分析結果
3. Critical Review: 見落としているリスクと反論
4. Next Steps: 明日から実行すべき具体的なタスク
## Tone
プロフェッショナル、論理的、断定的。曖昧な表現は避け、数値や事実に基づいて語る。
戦略コンサルタントロールの解説
このロールの核心は、「Frameworks to Use」による思考の型化と、「Counter-Argument」による批判的思考の強制です。LLMは通常、ユーザーに同調する傾向(Sycophancy:過度な同調傾向)がありますが、このプロンプトにより、イエスマンではない「頼れる参謀」としての振る舞いを引き出すことができます。
定義したロールの品質を技術的に検証するプロセス
プロンプトを作成して終わりではありません。エンジニアリングにおいて「テスト」が不可欠であるように、プロンプトも定量的に評価する必要があります。
ベンチマークテストの作成:Golden Datasetの準備
まず、「入力」と「理想的な出力(正解)」のペアを10〜20セット用意します。これを「Golden Dataset(理想的な正解データの集まり)」と呼びます。
- 入力: 典型的なユーザーからの質問
- 正解: 人間が作成した、満点の回答
LLMによるLLMの評価(LLM-as-a-Judge)の実装
毎回人間が目視で確認するのは非効率です。そこで、別のLLM(評価者モデル)を用いて、生成された回答を採点させる「LLM-as-a-Judge(AIによるAIの自動評価)」という手法を用います。
例えば、ChatGPTに以下のような評価プロンプトを与えます。
あなたは採点官です。
以下の「生成された回答」を「正解」と比較し、1〜5点で採点してください。
評価基準:
- 正確性:事実に誤りはないか
- 指示遵守:JSON形式になっているか
- トーン:指定されたペルソナ(監査役など)になりきれているか
このスコアを追跡することで、プロンプトの修正が品質向上に寄与したのか、あるいは改悪(リグレッション)になってしまったのかを客観的に判断できます。
実装に向けたチェックリストとトラブルシューティング
最後に、実運用で発生しがちな問題とその対策をまとめます。
ロール定義が無視される原因と対策
- 指示が長すぎる: コンテキストウィンドウ内での注目度(Attention)が分散しています。プロンプトを分割するか、重要な制約をプロンプトの最後(末尾)に再掲すると効果的です(Recency Bias:直近の情報を重視する傾向の活用)。
- 矛盾する指示: 「簡潔に」と「詳細に」が混在していないか確認しましょう。
継続的なプロンプト改善(Prompt Ops)のフロー
プロンプトは一度書いて終わりではありません。Gitでバージョン管理を行い、ユーザーからのフィードバック(Good/Bad評価など)を元に、継続的にパラメータを調整する運用体制(Prompt Ops:プロンプトの継続的な運用改善)を構築してください。
まとめ
LLMの回答精度を高める鍵は、プロンプトを「言葉」ではなく「構造化されたコード」として捉えることにあります。
- 変数の定義: 属性、知識、制約、トーン、ゴールを明確にする。
- 構造化記述: MarkdownやJSONを用いてLLMにパース(解析)させる。
- 定量的評価: Golden DatasetとLLM-as-a-Judgeで品質を計測する。
これらを実践することで、LLMは単なるチャットボットから、業務を確実に遂行する頼もしいパートナーへと進化します。
今回ご紹介した内容は、AI導入の入り口に過ぎません。実際のプロジェクトでは、RAG(検索拡張生成)との連携や、マルチエージェントシステムの構築など、さらに高度な設計が求められます。
コメント