なぜ今、「ローカルLLM×自律エージェント」が企業の現場で注目されるのか
「今月のAPI利用料の請求額、これ合ってる…?」
月末に届く請求書を見て、驚いた経験はないでしょうか。あるいは、「社外秘データを含むログをクラウドに送信するのはNG」というセキュリティ部門の一声で、せっかくのAIプロジェクトが頓挫してしまうケースも実務の現場では珍しくありません。
対話の自然さと業務要件を両立させるAIシステム設計において、クラウド型LLMの限界や制約に直面することは多々あります。ユーザーの発話パターンを分析し、適切な対話フローを設計しようとA/Bテストを繰り返すほど、コストやセキュリティの壁が立ちはだかるのです。
昨今、生成AIの活用は「チャットで質問する」フェーズを超え、AI自身がツールを使ってタスクを完遂する「エージェント」の領域へと進化しています。しかし、高度なエージェントを作ろうとすればするほど、APIの呼び出し回数は増え、コストは青天井になりがちです。また、機密情報を扱う業務では、外部サーバーへのデータ送信自体が大きなリスクとなります。
そこで今、現場のエンジニアたちの熱い視線を集めているのが、「ローカルLLM」と「自律型エージェント」の組み合わせです。
「ただのチャットボット」と「自律エージェント」の決定的な違い
まず、言葉の定義をはっきりさせておきましょう。ここが曖昧だと、対話設計のゴールがぶれてしまいます。
従来のチャットボット(LLM単体)は、いわば「博識な相談相手」です。知識は豊富ですが、基本的にはユーザーからの問いかけに答えることしかできません。箱の中に閉じ込められた賢者、といったイメージですね。
一方、自律型AIエージェントは、「手足を持った実行者」です。ユーザーが「競合他社の最新ニュースを調べてまとめて」と頼めば、自らWebブラウザを立ち上げて検索し、記事を読み込み、要約してレポートを作成します。LLMは単なる知識ベースではなく、どのツールをどの順番で使うかを判断する「司令塔(脳)」として機能するのです。
この「脳」を自分のPC内に持ち、「手足」となるツールを自由に操作させる。これがローカルでエージェントを構築する醍醐味であり、実験志向のエンジニアにとって理想的な環境と言えます。
OpenAI依存のリスク:従量課金の青天井とデータガバナンスの壁
OpenAIの最新APIモデルをはじめとする商用モデルは確かに優秀です。しかし、エージェント開発においては、試行錯誤の回数が桁違いになります。
「思考のループ」が発生するためです。エージェントは1つのタスクをこなすために、「検索しよう」→「結果を読もう」→「情報が足りないから再検索しよう」と、内部で何度も推論を繰り返します。API課金モデルでは、このループの回数だけコストがかかっていくわけです。
2026年2月には、GPT-4oやGPT-4.1などのレガシーモデルが廃止され、100万トークン級のコンテキスト処理や高度な推論能力を備えたGPT-5.2、そしてコーディングタスクに特化したGPT-5.3-Codexへと標準モデルが移行しました。推論能力や応答品質は飛躍的に向上していますが、開発段階で「エラーが出るたびに課金される」というプレッシャーは、エンジニアの実験精神を削ぎます。また、旧モデル廃止に伴うプロンプトの再テストや移行作業のコストも考慮しなければなりません。さらに、金融や小売業界など機密情報を扱う業務では、そもそもクラウドにデータを送ること自体が許されないケースも多々あります。
オープンソースLLM(LlamaやMistral等)の進化がもたらしたパラダイムシフト
少し前まで、ローカルで動くLLMといえば「動作が重い」「推論が的外れ」というのが一般的な認識でした。しかし、Meta社のLlamaや、Mistral AI社のモデル群の登場で、状況は一変しました。
現在では、MoE(Mixture of Experts)アーキテクチャの採用により推論効率を劇的に高め、長大なコンテキストウィンドウやマルチモーダル入力に対応したLlamaや、コード生成に特化したDevstralを含むMistralの各モデルが、オープンソースまたはオープンウェイトで利用可能です。これらは、一般的なゲーミングPCやMacBook Proレベルのスペックでも十分に動作し、一昔前の商用モデルを凌駕し、最新のクラウドAIに迫る推論能力を持っています。
つまり、「自分専用の高性能AI」を、追加コストなしで、完全にオフラインの環境で動かせる時代が来たのです。
これは単なるコスト削減の話ではありません。AIの挙動をブラックボックスにせず、すべてのログを手元で確認しながら、AIがどう「考えて」いるのかを解剖できる最高の学習環境が手に入ることを意味します。ユーザーテストと改善のサイクルを回す上で、これほど強力な武器はありません。
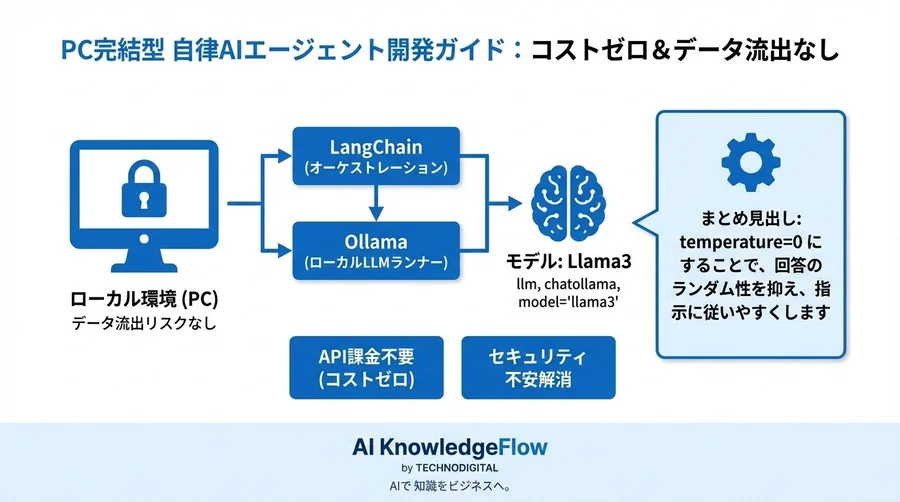
仕組みを解剖する:LangChainが「脳」と「手足」をつなぐ構造
「AIが自分で考える」といっても、魔法を使っているわけではありません。そこには明確なロジックと、それを支えるフレームワークが存在します。ここでは、PythonライブラリのデファクトスタンダードであるLangChainが、どのようにしてLLMをエージェント化しているのかを見ていきましょう。
ReActプロンプティング:AIが「考えてから行動する」プロセス
自律型エージェントの核心技術の一つに、「ReAct(Reasoning + Acting)」という手法があります。これは、AIに対して以下のような思考プロセスを強制するプロンプトエンジニアリングの一種です。
- Thought(思考): ユーザーの依頼に対して、今何をすべきかを考える。
- Action(行動): 具体的なツール(検索エンジンや計算機など)を選択し、実行する。
- Observation(観察): ツールの実行結果を確認する。
- Repeat: 解決するまで1〜3を繰り返す。
通常、LLMに「今日の東京の天気を教えて」と聞くと、学習データに含まれていなければ「わかりません」と答えるか、適当な嘘(ハルシネーション)をつきます。しかしReActを用いれば、AIは「今の天気は知らない。だから『天気検索ツール』を使おう」と推論し、外部データを取得しに行けるのです。適切なフォールバック設計と組み合わせることで、より堅牢な対話AIが実現します。
LangChainの役割:LLMと外部ツール(検索、計算、DB)の接着剤
LLM自体はテキストしか入出力できません。「検索ツールを実行する」といっても、LLMが勝手にブラウザを操作できるわけではないのです。
ここでLangChainの出番です。LangChainは、LLMが出力した「検索ツールを使いたい」というテキスト(Action)を解析し、実際にPythonの関数として検索APIを叩き、その結果(Observation)を再びテキストとしてLLMに戻す役割を担います。
いわば、LLMという「脳」と、外部ツールという「手足」をつなぐ「神経系」がLangChainなのです。このフレームワークがあるおかげで、複雑なAPI連携のコードをスクラッチで書くことなく、数行のコードでエージェントを定義できます。
コンテキストウィンドウとメモリ:会話の文脈をどう維持するか
ローカルLLMを利用する際に特に意識したいのが、コンテキストウィンドウ(記憶容量)の制限です。クラウドの最上位モデルと違い、ローカルモデルは一度に処理できるトークン数が限られていることが多いです。
エージェントが思考と行動を繰り返すと、対話履歴(Thought/Action/Observationのログ)がどんどん積み上がっていきます。これがコンテキストウィンドウを超えると、AIは最初の目的を忘れてしまったり、エラーを吐いたりします。
LangChainには、この履歴を要約して保持したり、重要な情報だけを抽出して短期メモリに残したりする機能(Memoryモジュール)が備わっています。限られたリソースで賢く振る舞わせるための工夫も、ローカル開発ならではの面白さであり、対話フロー設計の腕の見せ所と言えるでしょう。
準備編:15分で整う「Ollama」を中心とした開発環境
理論はこれくらいにして、実際に手を動かしていきましょう。かつてローカルLLMの環境構築は、Pythonの依存関係地獄やCUDAのバージョン管理など、初心者が心を折られる難所でした。しかし、Ollamaの登場でその歴史は終わりました。
Ollamaのインストールとモデル(Llama / Mistral)の起動
Ollamaは、Dockerのようにコマンド一つでLLMをダウンロードし、APIサーバーとして立ち上げてくれるツールです。macOS、Linux、そしてWindows(プレビュー版)に対応しています。
手順1: Ollamaのインストール
公式サイト(ollama.com)からインストーラーをダウンロードして実行するだけです。
手順2: モデルの実行
ターミナル(またはコマンドプロンプト)を開き、以下のコマンドを打ち込みます。
ollama run Llamaモデル
これだけで、数GBのモデルファイルが自動的にダウンロードされ、チャット画面が立ち上がります。「Hello」と打って返事が来れば成功です。終了するには /bye と入力します。
この裏側では、ローカルホストの 11434 ポートでAPIサーバーが稼働しており、LangChainからはこのポート経由でLLMにアクセスすることになります。
Python仮想環境とLangChainライブラリのセットアップ
次に、Python側の準備をします。プロジェクト用のディレクトリを作り、仮想環境を用意しましょう。
mkdir local-agent-demo
cd local-agent-demo
python -m venv venv
source venv/bin/activate # Windowsの場合は venv\\Scripts\\activate
必要なライブラリをインストールします。LangChainは機能ごとにパッケージが分かれているので注意が必要です。
pip install langchain langchain-community langchain-ollama duckduckgo-search
langchain: フレームワーク本体langchain-community: サードパーティツール(検索機能など)を含むパッケージlangchain-ollama: Ollamaとの連携用パッケージduckduckgo-search: APIキー不要で使える無料の検索ツール
推奨スペックと動作が重い時の軽量化設定
ローカルLLMを快適に動かすには、ある程度のマシンスペックが必要です。
- 推奨: メモリ(RAM)16GB以上、GPU搭載(NVIDIA GeForce RTX 3060以上 または Apple Silicon M1/M2/M3)
- 最低: メモリ8GB(動作はしますが、応答に時間がかかります)
もし動作が重い場合は、より軽量なモデルを試してみてください。例えば Llamaモデル (8Bモデル) が重い場合、Microsoftの phi3 などの小型モデルや、量子化レベル(圧縮率)の高いモデルを指定することで、動作を軽くできます。
実践編:Web検索能力を持つ「調査アシスタント」を作る
環境が整ったので、いよいよコードを書いていきます。今回作るのは、「ユーザーの質問に対してWeb検索を行い、最新情報を元に回答するエージェント」です。
Toolの定義:AIに「Google検索」という武器を持たせる
まずは、必要なライブラリをインポートし、LLMとツールを定義します。
from langchain_ollama import ChatOllama
from langchain_community.tools import DuckDuckGoSearchRun
from langchain.agents import AgentExecutor, create_react_agent
from langchain_core.prompts import PromptTemplate
# 1. ローカルLLMの指定
# temperature=0 にすることで、回答のランダム性を抑え、指示に従いやすくします
llm = ChatOllama(model="Llamaモデル\
コメント